文章目錄
-
-
- KeyBy
- Reduce
-
- flink儲存累計值原理
- Split 和Select
-
- split
- Select
-
- 需求:将kafka中資料根據某屬性分割開,分成兩個流
- Connect和 CoMap
-
- Connect
- CoMap,CoFlatMap
- Union
-
- Connect與 Union 差別
-
常見的map.flatMap,filter類比spark
DataStream → KeyedStream:輸入必須是Tuple類型(一般通過map轉換),邏輯地将一個流拆分成不相交的分區,每個分區包含具有相同key的元素,在内部以hash的形式實作的。
KeyedStream → DataStream:一個分組資料流的聚合操作,合并目前的元素和上次聚合的結果,産生一個新的值,傳回的流中包含每一次聚合的結果,而不是隻傳回最後一次聚合的最終結果。
//求各個管道的累計個數
val startUplogDstream: DataStream[StartUpLog] = dstream.map{ JSON.parseObject(_,classOf[StartUpLog])}
val keyedStream: KeyedStream[(String, Int), Tuple] = startUplogDstream.map(startuplog=>(startuplog.ch,1)).keyBy(0)
//reduce //sum
keyedStream.reduce{ (ch1,ch2)=>
(ch1._1,ch1._2+ch2._2)
} .print().setParallelism(1)
類比可知,spark的reduceByKey == keyBy+Reduce
flink是一種有狀态的流計算架構
- operator state : 主要是儲存資料在流程中的處理狀态,用于確定語義的exactly-once
- keyed state : 主要儲存資料在計算過程中的累計值
這兩種狀态都是通過checkpoint機制儲存在StateBackend中,StateBackend可以選擇儲存在記憶體中(預設使用)或者儲存在磁盤檔案中。
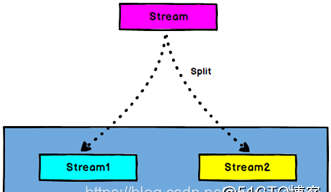
DataStream → SplitStream:根據某些特征把一個DataStream拆分成兩個或者多個DataStream。

SplitStream→DataStream:從一個SplitStream中擷取一個或者多個DataStream。
package kafka
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.api.scala._
object ConsumerApp {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
val kafkaConsumer = KafKaUtil.getConsumer("test")
//import org.apache.flink.api.scala._ 這裡要加入隐式轉換
val dstream = environment.addSource(kafkaConsumer)
// dstream.print()
val logStream = dstream.split {
log =>
var flags: List[String] = null
if ("Apple".equals(log)) {
flags = List(log)
} else {
flags = List("Android")
}
flags
}
val apple = logStream.select("Apple")
apple.print("apple:").setParallelism(1)
val android = logStream.select("Android")
android.print("Android:").setParallelism(1)
environment.execute()
}
}
DataStream,DataStream → ConnectedStreams:連接配接兩個保持他們類型的資料流,兩個資料流被Connect之後,隻是被放在了一個同一個流中,内部依然保持各自的資料和形式不發生任何變化,兩個流互相獨立。
這兩個不是算子,隻是類比 connect + map / flatMap
ConnectedStreams → DataStream:作用于ConnectedStreams上,功能與map和flatMap一樣,對ConnectedStreams中的每一個Stream分别進行map和flatMap處理。
val connStream = androidStream.connect(appleStream)
val allStream = connStream.map(
(log1: String) => log1 + "1",
(log2: String) => log2 + "2"
)
allStream.print("連接配接流:")
val unionStream = appleStream.union(androidStream)
unionStream.print("union:")
environment.execute()