随着AlphaGo和AlphaZero的出現,強化學習相關算法在這幾年引起了學術界和工業界的重視。最近也翻了很多強化學習的資料,有時間了還是得自己動腦筋整理一下。
強化學習定義
先借用維基百科上對強化學習的标準定義:
強化學習(Reinforcement Learning,簡稱RL)是機器學習中的一個領域,強調如何基于環境而行動,以取得最大化的預期利益。
從本質上看,強化學習是一個通用的問題解決架構,其核心思想是 Trial & Error。
強化學習可以用一個閉環示意圖來表示:
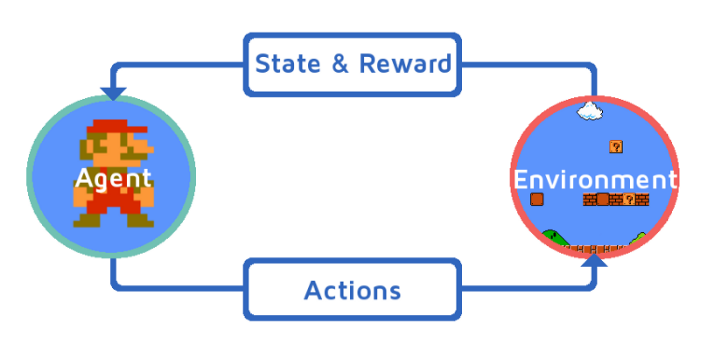
強化學習四元素
- 政策(Policy):環境的感覺狀态到行動的映射方式。
- 回報(Reward):環境對智能體行動的回報。
- 價值函數(Value Function):評估狀态的價值函數,狀态的價值即從目前狀态開始,期望在未來獲得的獎賞。
- 環境模型(Model):模拟環境的行為。
強化學習的特點
- 起源于動物學習心理學的試錯法(trial-and-error),是以符合行為心理學。
- 尋求探索(exploration)和采用(exploitation)之間的權衡:強化學習一面要采用(exploitation)已經發現的有效行動,另一方面也要探索(exploration)那些沒有被認可的行動,已找到更好的解決方案。
- 考慮整個問題而不是子問題。
- 通用AI解決方案。
強化學習 vs. 機器學習
機器學習是人工智能的一個分支,在近30多年已發展為一門多領域交叉學科,而強化學習是機器學習的一個子領域。強化學習與機器學習之間的關系可以通過下圖來形式化的描述:
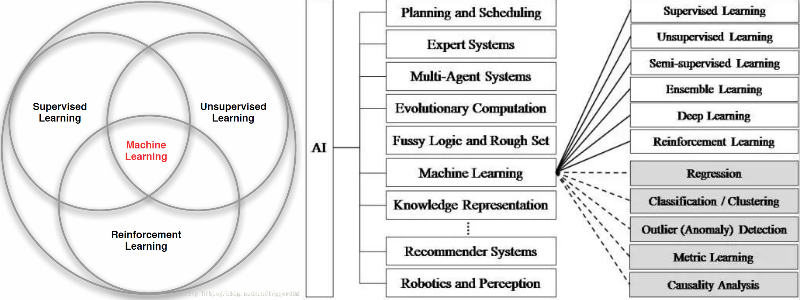
注:上圖中Machine Learning分支應該包含進化算法(Evolutionary Algorithms)。
強化學習與其他機器學習的不同:
- 強化學習更加專注于線上規劃,需要在探索(explore 未知領域)和采用(exploit 現有知識)之間找到平衡。
- 強化學習不需要監督者,隻需要擷取環境的回報。
- 回報是延遲的,不是立即生成的。
- 時間在強化學習中很重要,其資料為序列資料,并不滿足獨立同分布假設(i.i.d)。
強化學習 vs. 監督學習
強化學習與監督學習可以參考下圖:
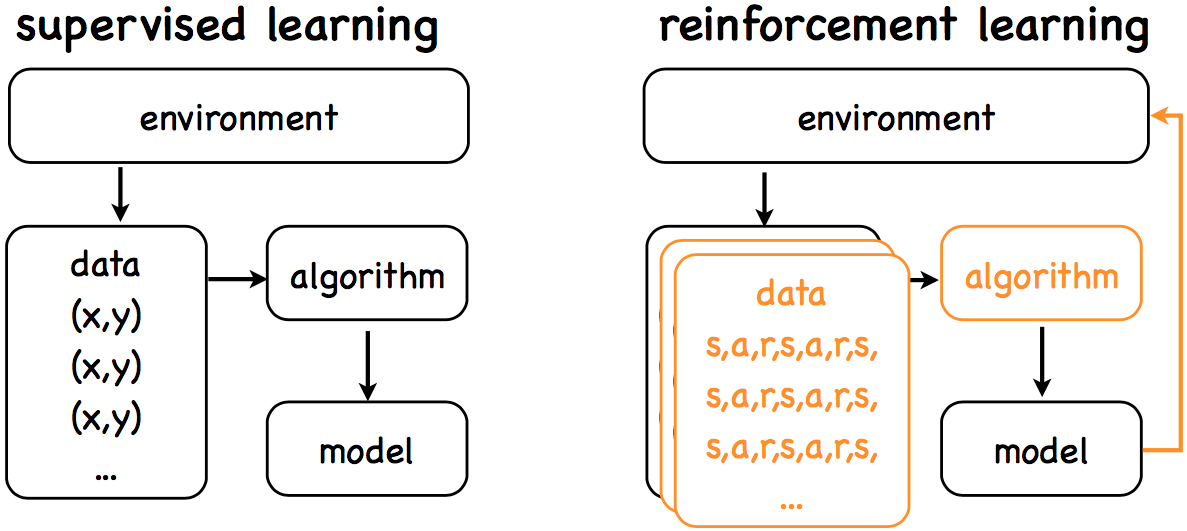
兩者的目标都是學習一個model,而差別在于:
監督學習:
- Open loop
- Learning from labeled data
- Passive data
強化學習:
- Closed loop
- Learning from decayed reward
- Explore environment
強化學習 vs. 進化算法
進化算法(Evolutionary Algorithms,簡稱EA)是通過生物進化優勝略汰,适者生存的啟發而發展的一類算法,通過種群不斷地疊代達到優化的目标。進化算法屬于仿生類算法的一種,仿生類算法還包括粒子群算法(PSO)、人工免疫算法以及如日中天的神經網絡算法等。
進化算法最大的優點在于整個優化過程是gradients-free的,其思想可以通過下圖表示:
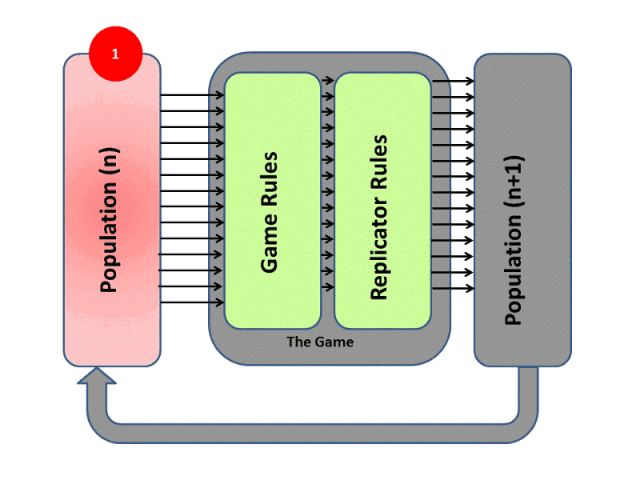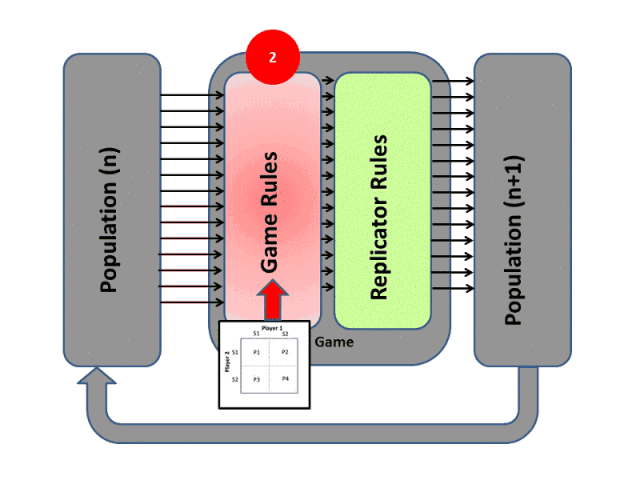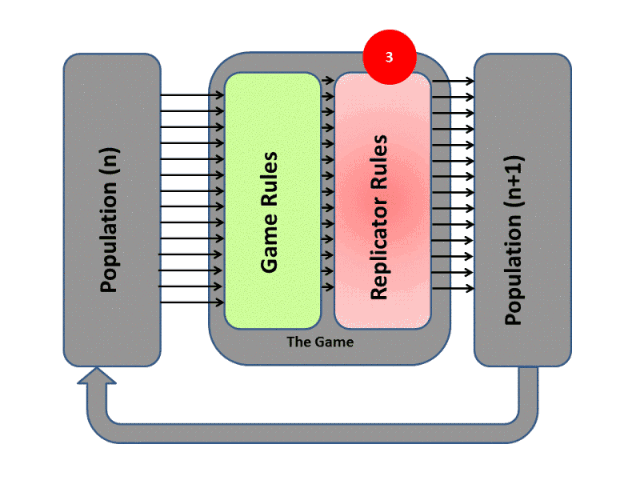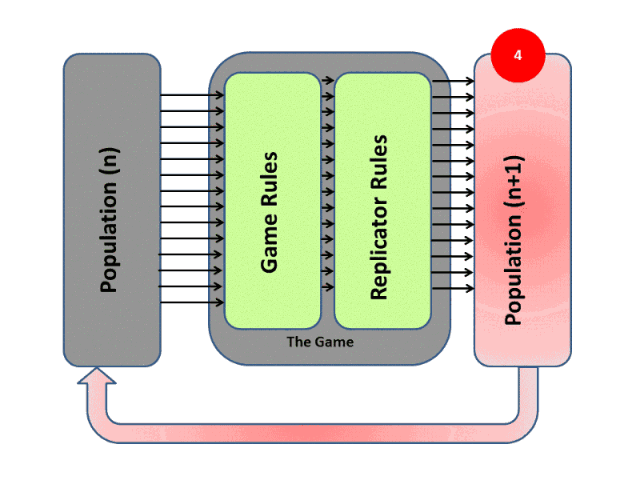
RL和EA雖然都屬于優化問題的求解架構,而且兩者都需要大量的算力,但是兩者有着本質上的差別。
Sutton在其強化學習介紹一書中也重點談到了RL與EA的差別,這裡簡單談幾點:
- RL通過與環境互動來進行學習,而EA通過種群疊代來進行學習;
- RL通過最大化累計回報來解決序列問題,而EAs通過最大化适應函數(Fitness Function)來尋求單步最優;
- RL對于state過于依賴,而EA在agent不能準确感覺環境的狀态類問題上也能适用。
近期随着RL的研究熱潮不斷推進,很多研究也嘗試通過将EA和RL結合解決優化問題,比如OpenAI通過使用進化政策來優化RL,獲得了突破性的進展[3]。
強化學習分類
強化學習分類比較多樣:
- 按照環境是否已知可以分為Model-based & Model-free;
- 按照學習方式可以分為On-Policy & Off-Policy;
- 按照學習目标可以分為Value-based & Policy-based。
下圖為根據環境是否已知進行細分的示意圖:

強化學習相關推薦資料
- Reinforcement Learning: An Introduction, Richard S. Sutton and Andrew G. Barto:介紹強化學習很全面的一本書籍,相關的電子書及源碼見這裡。
- David Silver在UCL的強化學習視訊教程:介紹強化學習的視訊教程,基本與Sutton的書籍可以配套學習,Silver來自于Google Deepmind,視訊和課件可以從Silver的首頁擷取,中文字幕版視訊YouTube連結點這裡。
- 強化學習在阿裡的技術演進與業務創新:介紹強化學習在阿裡巴巴的落地,可以拓展強化學習應用的業務思路,電子版見這裡,密碼:yh48。
- Tutorial: Deep Reinforcement Learning:同樣來自于Sliver的一個課件,主要針對RL與DL的結合進行介紹,電子版見這裡,密碼:9mrp。
- 莫煩PYTHON強化學習視訊教程:可以通過簡短的視訊概括地了解強化學習相關内容,适合于入門的同學,視訊見這裡。
- OpenAI Gym:Gym is a toolkit for developing and comparing reinforcement learning algorithms,Gym包含了很多的控制遊戲(比如過山車、二級立杆、Atari遊戲等),并提供了非常好的接口可以學習,連結見這裡。
- Lil'Log:介紹DL和RL的一個優質部落格,RL相關包括RL介紹、Policy Gradients算法介紹及Deep RL結合Tensorflow和Gym的源碼實作,首頁連結見這裡。
Reference
[1] 維基百科-強化學習
[2] Reinforcement Learning: An Introduction, Richard S. Sutton and Andrew G. Barto, 2018
[3] Evolution Strategies as a Scalable Alternative to Reinforcement Learning
作者:Poll的筆記
部落格出處:http://www.cnblogs.com/maybe2030/
本文版權歸作者和部落格園所有,歡迎轉載,轉載請标明出處。
<如果你覺得本文還不錯,對你的學習帶來了些許幫助,請幫忙點選右下角的推薦>
![算法導論8-5思考題-平均排序-average sorting[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)