關于CPU CACHE工作機制的學習
由于這段時間的工作需要,對目前CPUCACHE 高速緩存的工作原理機制進行了相對比較易通的學習和了解工作。
歡迎轉載,轉載請标明出處
1. 存儲層次結構
由于兩個不謀而合的因素如下:
l 硬體:由于不同存儲技術的通路時間相差很大。速度較快的技術每個位元組的成本要比速度較慢的技術高,而且容量小。CPU和主存之間的速度差距在增大
l 軟體:一個編寫良好的程式傾向于展示出良好的局部性。
聰明的人類想出了一種組織存儲器系統的方法,叫做 存儲器層次結構。
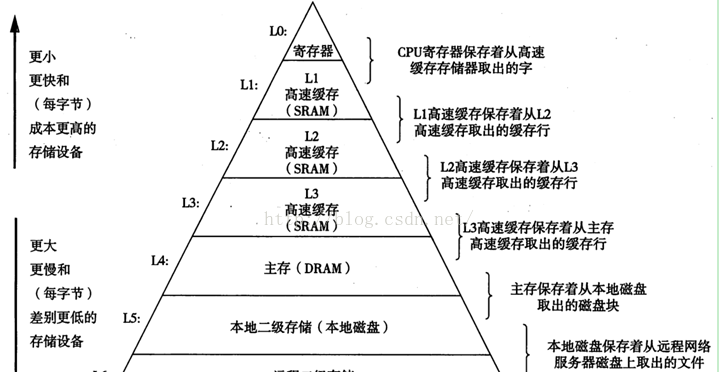
千言萬語不如一張圖:摘自《深入了解計算機系統第二版》
圖1
2. CACHE 緩存什麼
CACHE緩存什麼麼?
不同的緩存都緩存着自己以為重要的東西,來看張圖2

寄存器裡面是寄存器有32位和64位(也就是4位元組和8位元組的)
其中TLB 叫做:翻譯後背緩沖器。
MMU:存儲管理單元(MemoryManagement Unit)
3. 通用高速緩存存儲器結構
下圖3,講的非常明白
有效位指明這個行是否包含有意義的資訊,還有t=m-(b+s), m=t+b+s.
标記位唯一地辨別存儲在這個高速緩存行中的塊。
高速緩存大小,C=SXEXB
我想以上大家都能容易了解的。
3.1 具體工作機制
如上圖三所示,參數S和B将m個位址分為了三個字段。
n 其中s個組索引位是一個S個數組的索引。從第0組,第1組,。。到最後一組。組索引位告訴我們這個字必須放在哪個組中。OK。
n 标記位,則告訴我們在這個組的哪一行包含這個字(如果有,需要看有效位是否有效)
n 塊偏移位給出了在B個位元組的資料塊中的字偏移。
我們可以知道對于m位的 記憶體位址,每個尋址對能對應于CACHE上的一個位元組。
這裡放入圖4,關于高速緩存參數的小結,這些參數都非常容易了解。
3.1.1 直接映射高速緩存
根據E(每個組的高速緩存行數)高速緩存被分為不同的類。每個組隻有一行的高速緩存稱為直接高速緩存(direct-mapped cache).
高速緩存确定一個請求是否命中,然後抽取出請求的字的過程,分為三步:
組選擇,行比對,字抽取。
如下圖5所示
3.1.1.1 例子
這個例子非常好。如下圖6-9
3.1.1.2 直接映射問題
直接映射高速緩存中通常會發生沖突不命中。
即使程式有良好的空間局部性,而且我們的高速緩存中也有足夠的空間來存放資料,但是每次引用還是會導緻沖突不命中,這是因為這些塊被映射到了同一個高速緩存組。
這種抖動導緻速度下降2或3倍并不稀奇。這對于更大、更現實的直接映射高速緩存來說,問題很真實。
3.1.2 組相聯高速緩存
直接映射高速緩存中沖突不命中造成的問題源于每個組隻有一行這個限制。組相聯高速緩存(set associative cache)放松了這條限制,每個組都儲存有多于一個的高速緩存行。
E>1 但是 E< E/B叫做E路組相聯高速緩存。當E=C/B的時候,就是全相聯高速緩存了。
組相聯高速緩存中的行比對比直接映射高速緩存中的更複雜,因為必須檢查更多個行的标記位和有效位,以确定所請求的字是是否在集合中。
看如下圖10
這裡需要注意的是,組中任何一行 都可以包含任何映射到這個組的存儲器塊。
是以高速緩存必須搜尋組中的每一行,尋找一個有效的行,其标記與位址中的标記相比對。
3.1.2.1 有關命中
如果CPU請求的字不再組的任何一行中,那麼就是緩存不命中,高速緩存必須從存儲器中去取包含這個字的塊。如下圖11
3.1.3 全相聯高速緩存
全相聯高速緩存(fullyassociative cache)是由一個包含所有高速緩存行的組(即E=C/B)
如下圖12
由于全相聯,隻有一個組,位址隻被分為了一個标記和一個塊偏移。如下
圖13
全相聯高速緩存中的行比對和字選擇與組相聯高速緩存中的是一樣的。差別主要是規模大小的問題。因為高速緩存電路必須并行的搜尋許多相比對的标記,構造一個又大又快的相聯高速緩存很困難,而且很昂貴。是以,全相聯高速緩存隻适合走小的高速緩存,例如TLB,緩存頁表項。
3.1.4 有關寫
關于讀的操作非常簡單。寫的情況就複雜一些了。
如果更新了一個位元組的拷貝之後,怎麼更新低一層中的拷貝呢?最簡單的方法是直寫(write-through),就是将w的高速緩存塊寫回到緊接着的低一層中。雖然簡單,但是直寫的缺點是每次寫都會引起總線流量。另一種是寫回(write-back),盡可能的推遲存儲器更新,隻有當替換算法要驅逐更新過的塊時,才把它寫到緊接着的第一層中。寫回能顯著地減少總線流量,但是它的缺點是增加了複雜性。高速緩存必須為每個高速緩存行維護一個額外的修改位,表明這個高速緩存塊是否被修改過。
另外一個問題是,如果處理寫不命中。一種方法稱為寫配置設定(write-allocate),加載相應的低一層的塊到高速緩存中,然後更新這個高速緩存塊。寫配置設定視圖利用寫的空間局部性,但是缺點是每次不命中都會導緻一個塊從低一層傳送到高速緩存。另一種方法,稱為非寫配置設定(not-write-allocate),避開高速緩存,直接把這個字寫到低一層中。直寫高速緩存通常是非寫配置設定的。寫回高速緩存通常是寫配置設定的。
3.1.5 實際高速緩存剖析
現代處理的高速緩存即儲存指令的高速緩存,又儲存資料的高速緩存。稱為統一的高速緩存。其中指令高速緩存是制度的,比較簡單。
圖14i7的
I7高速緩存層次結構的特性如下圖15
4. 對性能影響
4.1 高速緩存參數的性能影響
優化高速緩存的成本和性能的折中是一項很精細的工作,需要在現實的基準程式代碼上進行大量的模拟。
相聯度的優點是降低了高速緩存由于沖突不命中出現抖動的可能性。較高的相聯度造成較高的成本,而且很難使速度變快。每一行需要更多的标記位,每一行需要額外的LRU狀态為和額外的控制邏輯。也會增加命中時間。
相聯度的選擇最終程式設計了命中時間和不命中出發之間的折中。