出現擁塞
\[∑_{對資源的需求} > ∑_{可用資源}
\]
擁塞控制是防止過多的資料注入到網絡中,使網絡中的路由器或鍊路不過載,這是一個全局性的。
流量控制是點對點的通信量的控制,是端到端問題。
擁塞控制方法
在最寬泛的級别上,我們可根據網絡層是否為運輸(傳輸)層擁塞控制提供顯示幫助,來區分擁塞控制方法。
端到端擁塞控制
在這種方式中,網絡層沒有為運輸層擁塞控制提供顯示支援。端系統必須通過對網絡行為的觀察(如分組丢失與時延)來推斷網絡是否出現擁塞。TCP必須通過端到端的方法來解決也擁塞控制,因為IP層不會向端系統提供有關網絡擁塞的回報資訊。TCP封包段的丢失(通過逾時或3次備援确認得知)被認為是網絡出現擁塞的一個迹象,TCP會相應地減小其視窗長度。
在TCP擁塞控制的一些最建立議也會使用往返時延RTT值的增加作為網絡擁塞程度增加的訓示。
網絡輔助的擁塞控制
在網絡輔助的擁塞控制中,網絡層構件(即路由器)向發送方提供有關網絡中擁塞狀态的顯示回報資訊。
擁塞資訊從網絡回報到發送方通常有兩種方式:
- 直接回報資訊由網絡路由器發給發送方,這種通知方式常采用了一種 阻塞分組(choke packet) 的形式(含義為:“我阻塞了”)
- 顯示擁塞通知(Explicit Congestion Notification,ECN)。該方式由路由器标記或更新發送方流向接收方的分組中的某個字段(IP頭部的CE字段)來訓示擁塞的産生。當接收方接收到這樣的分組後,就會向發送方發送網絡擁塞的通知(在回複的ACK的TCP字段置位ECN字段)。然而,這種方式需要至少需要一個完整的RTT。(使用網絡輔助的擁塞控制例子可參見ATM ABR擁塞控制)
關于TCP擁塞控制的三個問題
TCP使用的是端到端擁塞控制。TCP所采用的方法是讓每一個發送方根據感受到的網絡擁塞程度來限制其能向其連接配接發送流量的速率。由此可引出三個問題:①TCP發送方如何限制它向其連接配接發送流量的速率?②TCP發送方如何感覺它到目的地之間的路徑上出現了擁塞?③當發送方感受到了端到端的時延,使用何種算法來改變其發送速率呢?下面我們一一分析。
TCP發送方如何限制它向其連接配接發送流量的速率?
一條TCP連接配接會建立一些狀态變量,比如LastByteRead、rwnd。運作在發送方的TCP擁塞控制即使會跟蹤一個變量,即
擁塞視窗(congestion window)。擁塞視窗表示為cwnd,它對一個TCP發送方能向網絡中發送流量的速率進行了限制。需要注意在一個發送方中未被确認的資料量不會超過cwnd和rwnd中的最小值。即:
\[LastByteSent - LastByteAcked <= min\{cwnd, rwnd\}
為了關注擁塞控制(與流量控制形成對比),我們後面假設TCP接收緩存足夠大,以至于忽略接受視窗rwnd的限制,發送方中未确認的資料量僅受限于cwnd。并且假設發送一直有資料要發送,即在擁塞視窗中的所有封包段都要被發送。
這些限制限制了發送方中未被确認的資料量,是以間接地限制了發送方的發送速率。
TCP發送方如何感覺它到目的地之間的路徑上出現了擁塞?
當過度的擁塞出現時,在沿着這條路徑上的一台或者多台路由器的緩存會溢出,引起一個資料報(含TCP封包段)被丢棄。丢棄的資料報會引起發送方的丢包事件(逾時或者受到三個備援ACK),發送方就會認為到接收方的路徑上出現了擁塞訓示。(收到3個備援ACK時,會進行快重傳對丢失封包進行重傳而不必等到逾時再重傳,因為逾時重傳對發送速率影響很大,二者對擁塞控制的影響可見下文。前一篇文章簡要介紹了快速重傳,後面會補充快重傳為什麼是要接收到3個備援ACK)
TCP發送方如何确定它的發送速率?
發送方會接收到确認封包并且增加擁塞視窗長度,TCP可以被稱為是
自計時(self-clocking)的。給定cwnd來控制發送速率可還是不知發送方如何确定它應當發送的速率。如果衆多發送方總體上發送地太快,它們會擁塞網絡,而發送地太慢又不可以充分利用網絡帶寬。
那TCP是如何确定它們的發送速率,既不會使網絡擁塞也不會浪費帶寬?TCP發送方式顯示地協作,或者存在一種分布式方法使得TCP發送方能夠基于本地資訊設定它們的發送速率?
這裡有一些指導性原則回答這些問題:
- 一個丢失的封包段意味着擁塞,是以當丢失封包段時應當降低TCP發送方的速率
-
對目前未确認的封包的确認到達時,能夠增加發送方的速率
确認封包的到達可以看做一些順利的訓示,訓示發送方封包段被順利地傳遞給接收方,網絡中沒有出現擁塞。是以,擁塞視窗長度可增加。
-
帶寬探測
ACK封包回複隐含地訓示了從源到目的地的路徑上面沒有出現擁塞,丢包事件則訓示出現了擁塞。由此,TCP便通過調節其傳輸速率增加影響ACK封包,如果出現丢包便減小傳輸速率,然後再進行增加速率,看擁塞狀況是否改變。
TCP擁塞控制算法
該算法主要包括3個主要部分:①慢啟動;②擁塞避免;③快速恢複。慢啟動和擁塞避免是TCP強制部分,兩者的差異在于對接收到的ACK做出反應時cwnd增加的長度。慢啟動比擁塞避免能更快的增加cwnd的長度。快速恢複是推薦部分,對TCP發送方并非是必需。
慢啟動
在慢啟動狀态,cwnd的值以一個MSS開始并當傳輸的封包首次被确認就增加一個MSS。如下圖所示,開始發送一個封包段,收到确認後擁塞視窗增加1。然後傳輸2個封包段,收到2個确認後增加擁塞視窗變成了4個MSS。這樣沒經過一個RTT,發送速率就會翻番。于是,TCP發送的起始速率慢,但是在慢啟動階段會以指數增長。
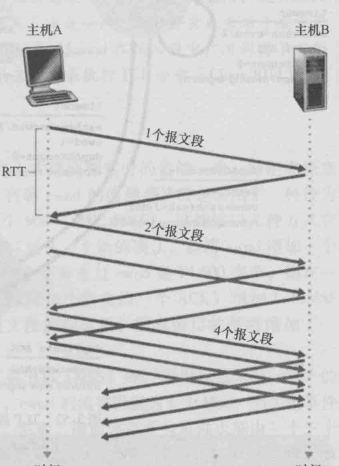
但是這樣會的增長何時終止呢?慢啟動對這個問題提供了幾種答案。
- 第一種: 如果出現一個有逾時引起的丢包事件(即網絡中出現了擁塞),TCP發送方将cwnd設定為1并重新開始慢啟動過程。它還會将第二個狀态變量 ssthresh(“慢啟動門檻值”) 設定為cwnd/2。
- 第二種: 與ssthresh相關。當增加到cwnd=ssthresh時,結束慢啟動并開始擁塞避免。
- 第三種: 如果檢測到3個備援ACK,這時TCP執行快速重傳進入快速恢複狀态。
擁塞避免
進入擁塞狀态後,TCP的cwnd增加速率就比較緩慢,一個RTT将cwnd的值增加一個MSS,線性增長。例如,發送方在1個RTT時間内發送10個封包,那麼收到所有10個确認封包後,擁塞視窗的值增加一個MSS。
在這個階段的cwnd增長停止時的情況:
-
逾時
出現逾時,\(ssthresh = 1/2 * cwnd\),cwnd被置為1個MSS,然後開始慢啟動
-
收到三個備援ACK
TCP對于這種丢包事件,較與逾時的做出的反應,比較溫和。TCP将cwnd減半(為使測量結果較好,計已收到的3個備援ACK要加上3個MSS),并将ssthresh置為cwnd(未減半)的一半。然後進入快速恢複狀态。
快速恢複
在快速恢複中,對于引起TCP進入快速恢複狀态的缺失封包段,對收到的每個備援的ACK,cwnd的值都增加一個MSS。最終,當對丢失封包段的一個ACK到達時,TCP在降低cwnd後進入擁塞避免狀态。如果出現逾時事件:cwnd置為1個MSS,并且ssthresh置為cwnd的一半,遷移到慢啟動。
快速恢複是TCP推薦部件而不是必需。一種早期的TCP版本
TCP Tahoe,不管是逾時而引起的丢包還是3個備援ACK引起的丢包事件,都會将cwnd置為1個MSS,并進入慢啟動階段。TCP較新的版本
TCP Reno綜合了快速恢複算法。
附圖一張TCP擁塞控制流程圖

在每個RTT内cwnd線性增加1MSS,然後出現3個備援ACK事件時cwnd減半(乘性減)。是以,TCP擁塞控制常被稱為
加性增乘性減(Additive-Increase, Multiplicative-Decrease, AIMD)擁塞控制方式。
基于遲延的擁塞控制算法之TCP Vegas算法
TCP Vegas算法試圖在維持較好吞吐量的同是避免擁塞。基本思想是:①在分組丢失發生之前,在源與目的地之間檢測路由器中的擁塞;②當檢測出快發生分組丢失時,線性地降低發送速率。通過觀察RTT來預測分組是否要發生丢失。分組的RTT越長,路由器中的擁塞越嚴重。
快速重傳為什麼是收到3次備援ACK
對同一封包收到兩次ACK很有可能是封包段亂序造成的,收到3個及3個以上一定是丢包造成的!
依據經驗,收到3個duplicated ACK便可以啟動快重傳。
參考[知乎:TCP快速重傳為什麼是三次備援ack,這個三次是怎麼定下來的?車小胖回答
](https://www.zhihu.com/question/21789252)後,作圖如下:
每天進步一點點,不要停止前進的腳步~