來自這篇論文:<Learning Spatial Fusion for Single-Shot Object Detection>
論文位址:https://arxiv.org/pdf/1911.09516v1.pdf
代碼位址:https://github.com/ruinmessi/ASFF
捕捉到題目中重點: Learning spatial fusion 即論文主要是提出一種新的自适應融合政策,實作特征在空間上的融合,在單階段目标檢測中取得了較好的效果.這種政策作者将它命名為Adaptively Spatial Feature Fusion (ASFF)
一、contribution:
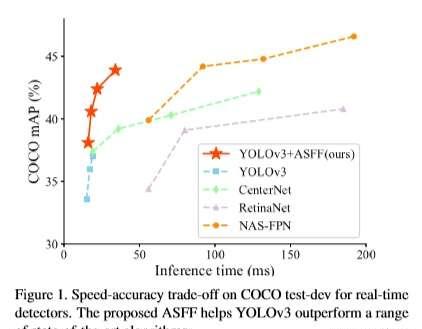
1.實作了一個更strong的baseline (将YOLOv3 從33.0%直接提升到38.8%)
作者博采衆長, 利用最近在目标檢測領域新湧現的各種訓練trick和基于anchor的各種網絡進行訓練, 最終把baseline提高了5.8%, 恐怖如斯, 以下我們盤點一下作者所用到的論文及其主要思想.
a. Bag of tricks
來自于<Bag of Freebies for Training Object Detection Neural Networks>
https://arxiv.org/pdf/1902.04103.pdf
該文章提出了一種用于目标檢測任務的視覺相幹(visually coherent)圖像混合(mixup)方法,還詳細探讨了關于學習率排程、權重衰減和同步 BatchNorm等訓練trick, 最終證明了其方法的有效性, 不修改網絡架構、損失函數, 不增加任何推理成本,在現有模型的基礎上實作了 5% 的絕對精度提升。
b.聯合訓練anchor free branch 和 anchor based branch
來自于<Feature Selective Anchor-Free Module for Single-Shot Object Detection>
https://arxiv.org/pdf/1903.00621.pdf
該文章作者指出在目标檢測中anchor機制總是将ground truth box比對到最接近的anchor boxes,也就是配置設定到了某一個特征層, 這是sub-optimal的. 是以避開anchor, 增加輕量的anchor free分支讓網絡去選擇特征層, 使得每一個ground truth box比對到最佳的特征層. 單獨使用anchor-free分支效果與單獨使用anchor-base基本持平, 隻高了0.2%,組合anchor-based+anchor-free,能明顯提升檢測效果,AP由35.9%提升到37.2%
c.anchoring guiding機制
來自于<Region Proposal by Guided Anchoring>
https://arxiv.org/pdf/1901.03278.pdf
現階段目标檢測方法很多都使用了anchor機制, 通過預先定義好的長寬比和大小在空間位置上進行采樣産生proposal。該文章作者提出了Guided Anchoring, 利用語義特征引導anchor, Guidied Anchoring 不僅預測感興趣的object的center位置, 而且預測不同空間位置處的大小和長寬比
d.IoU loss
來自<UnitBox: An Advanced Object Detection Network>2016
https://arxiv.org/pdf/1608.01471.pdf
這是一篇比較老的文章, ASFF在原有的平滑L1 loss基礎上使用了額外的IoU loss, IoU loss在UnitBox中首次被提出,并證明了其有效性
2.自适應空間特征融合
a.motivation:
用特征金字塔檢測物體時, 存在一個啟發性式特征選擇機制, 大的intance對應高層的feature map, 小的instance對應低層的feature map. 當一個某一特征層的執行個體屬于positive sample, 這意味着在其他特征層上相應的那部分區域将被是為背景. 這種不同level特征之間的沖突、這種不一緻會幹擾訓練時的梯度計算,降低了特征金字塔的有效性。
(意思大概是, 在這個level的feature上instance你告訴模型它positive, 另一個level上相應的這部分卻告訴模型negative, 模型風中淩亂了)
在此基礎上, 作者提出了一個新穎且有效的方法, 即自适應性空間特征融合(ASFF), 以這種方法去解決在單階段目标檢測特征金字塔中存在的這種不一緻問題. ASFF能夠讓網絡去學習如何在空間上過濾其他層的無用資訊, 隻保留有用資訊去combination.
b.advantage:
1) 搜尋最優融合的操作過程是可微分的,可以友善地在反向傳播中學習
2)ASFF與backbone無關,适用于所有具有特征金字塔結構的單階段檢測器
3) 實作簡單,增加的計算量很小
c.Apative Fusion

注意:上圖中,從level1、2、3到ASFF1、2、3之間的連結是全連接配接。
(1)
融合前需要對feature map進行resize, 例如, 如果現在要将level 1、level 2、level3融合成ASFF-1, 首先需要對level 2、level 3進行下采樣, size一樣了再融合. 作者就是通過上采樣、下采樣和池化的操作将level1,2,3變成同樣size便于下步融合操作
代表從level n的特征resize到level l 後(i,j)處的特征向量
以上公式的意思就是, level1,2,3 resize後的feature map 在每個(i,j)與 各自的權重矩陣
的(i,j)處相乘再相加, 得到融合後的ASFF-L
且滿足
限制條件, 這個限制條件通過
1*1卷積後得到的
再softmax來滿足
輸出
就是圖中的ASFF-1、ASFF-2、ASFF-3, 它們作為prediction的輸入
d.consistency property
剛剛提到motivation中作者指出特征金字塔目标檢測中存在不一緻問題, 這部分作者給出了ASFF的一緻性屬性證明
在YOLOv3中, 以resize前的level 1 feature map上的(x,y)點為例, 梯度可以這樣被計算: (沒寫
)
(3)
因為在特征金字塔不同層的變換中我們隻使用了上采樣、下采樣(pooling)等, 我們可以簡單的将這個過程的梯度視為約等于1
即
這樣我們就可以将最開始的式子化簡為:
(4)
對于在YOLOv3、RetinaNet上兩種較為常見的融合操作(sum、concat), 隻有element-wise sum and concatenation操作, 是以有
式子又可以被化簡為:
(5)
假設根據比對機制, level 1位置(i,j)是一個object的中心,
是來自正樣本的梯度。其他層對應的位置被視為背景, 是以
是來自負樣本的梯度. 這種不一緻性會幹擾
梯度, 并降低feature map level 1的訓練效率
解決這個問題的典型方法是設其他level map上相關位置為忽略區域, 即
, 這種方法雖然消除了level 1 map上的沖突, 但
之間的相關性會在一些局部最優的level上cause more inferior predictions as false positives( 如何了解?? 我的了解是會讓level2 map、level3 map都變差, 沒那麼容易區分在哪個level上positive)
那麼這個問題在ASFF上如何解決呢? 由式(1)和式(4)可得:
(6)
這裡的
, 利用這三個系數,如果
,則可以很好地協調梯度的不一緻。可以通過标準的反向傳播算法學習融合參數,是以,經過這樣調整的訓練過程可以産生有效的系數, 與此同時
也被保留, 避免産生false positives
二、experiment results
參考:
FSAF https://blog.csdn.net/diligent_321/article/details/88384588
釋出于 2020-03-13
原文連結:https://zhuanlan.zhihu.com/p/112969358
ASFF:目标檢測自适應特征融合方式
Adaptively Spatial Feature Fusion的自适應特征融合方式
在目前的目标檢測算法中,為了充分利用高層特征的語義資訊和底層特征的細粒度特征,采用最多也是較好的特征融合方式一般是FPN架構方式,但是無論是類似于YOLOv3還是RetinaNet他們多用concatenation或者element-wise這種直接銜接或者相加的方式,論文作者認為這樣并不能充分利用不同尺度的特征。是以提出一種新的融合方式來替代concat或element-wise。
以ASFF-3為例,圖中的綠色框描述了如何将特征進行融合,其中X1,X2,X3分别為來自level,level2,level3的特征,與為來自不同層的特征乘上權重參數α3,β3和γ3并相加,就能得到新的融合特征ASFF-3,如下面公式所示:
因為采用相加的方式,是以需要相加時的level1~3層輸出的特征大小相同,且通道數也要相同,需要對不同層的feature做upsample或downsample并調整通道數。
對于權重參數α,β和γ,則是通過resize後的level1~level3的特征圖經過1×1的卷積得到的。并且參數α,β和γ經過concat之後通過softmax使得他們的範圍都在[0,1]内并且和為1:
總結,其實這種融合方式的思想在很多算法中都有展現,比如注意力模型,圖像修複算法,利用權重參數來調整特征融合的貢獻大小。
————————————————
版權聲明:本文為CSDN部落客「豆豆小朋友小筆記」的原創文章,遵循CC 4.0 BY-SA版權協定,轉載請附上原文出處連結及本聲明。
原文連結:https://blog.csdn.net/qq_40728805/article/details/103524193
如果這篇文章幫助到了你,你可以請作者喝一杯咖啡