一 概述
在資料庫方面,對于非DBA的程式員來說,事務與鎖是一大難點,針對該難點,本篇文章試圖采用圖文的方式來與大家一起探讨。
“淺談SQL Server 事務與鎖”這個專題共分兩篇,上篇主講事務及事務一緻性問題,并簡略的提及一下鎖的種類和鎖的控制級别。
下篇主講SQL Server中的鎖機制,鎖控制級别和死鎖的若幹問題。
二 事務
1 何為事務
預覽衆多書籍,對于事務的定義,不同文獻不同作者對其雖有細微差别卻大緻統一,我們将其抽象概括為:
事務:指封裝且執行單個或多個操作的單個工作單元,在SqlServer中,其定義表現為顯示定義和隐式定義兩種方式。 基于如上的定義,我們可以将事務解剖拆分為如下幾個點:
(1)事務是單個工作單元,這一定義,才使事務具有ACID屬性
(2)事務是封裝操作的,如封裝基本的CRUD操作
1 --事務
2 Begin Tran
3 SELECT * FROM UserInfo
4 INSERT INTO UserInfo VALUES('Alan_beijing',35)
5 UPDATE UserInfo SET Age=31 WHERE UserName='Alan_beijing'
6 DELETE UserInfo WHERE UserName='Alan_beijing'
7 Commit Tran (3)事務在封裝操作時,可以封裝單個操作,也可以封裝多個操作(封裝多個操作時,應注意與批處理的差別)
(4)在SqlServer中,事務的定義分為顯示定義和隐式定義兩種方式
顯示定義:以Begin Tran作為開始,其中送出事務為Commit Tran,復原事務為RollBack Tran,如我們在一個事務中插入兩條操作語句
1 --顯示定義事務
2 Begin Tran
3 INSERT INTO UserInfo VALUES('Alan_shanghai',30)
4 INSERT INTO UserInfo VALUES('Alan_beijing',35)
5 Commit Tran 隐式定義:如果不顯示定義事務,SQL Server 預設把每個語句當作一個事務來處理(執行完每個語句之後就自動送出事務)
2 事務的ACID屬性
事務作為單個工作單元,該定義使其具有ACID屬性,ACID屬性指原子性(Atomicity)、一緻性(Consisitency)、隔離性(Isolation)和持久性(Durability)。
(1)原子性(Atomicity)
原子性指事務必須是原子工作單元,即對于事務的封裝操作,要麼全部執行,要麼全都不執行。如下情況均會導緻事務的撤銷或復原。。。
a.事務送出之前,系統發生故障或重新啟動,SQL Server将會撤銷在事務中進行的所有操作;
b.事務進行中遇到錯誤,SQL Server通常會自動復原事務,但也有少數例外;
c.一些不太嚴重的錯誤不會引發事務的自動復原,如主鍵沖突,鎖逾時等;
d.可以使用錯誤處理代碼來捕獲一些錯誤,并采取相應的操作,如把錯誤記錄在日志中,再復原事務等;
(2)一緻性(Consisitency)
一緻性主要指資料一緻性,即主要對象是資料。從宏觀上來說,指某一段時間區間,資料要保持一緻性狀态,從微觀上來說,某個時間點資料要保持一緻性狀态,我們舉個例子,
假若有兩個事務A和B對同一張表進行操作,A向表中寫資料,B向資料表中讀取資料,可以猜測,B讀取的資料大緻有三種粗粒度可能:
第一種可能:A還沒向資料表中寫入資料的狀态;
第二種可能:A已向資料表中寫入部分資料,但還未寫完的狀态;
第三種可能:A已向資料表中寫完資料;
如此,造成了事務的不一緻性。
關于事務一緻性,可能會發生 丢失更新,髒讀,不可重複讀和幻讀等問題,下文會詳細論述這些事務一緻性問題。
(3)隔離性(Isolation)
隔離性指當兩個及其以上事務對同一邊界資源進行操作時,要控制好每個事務的邊界,控制好資料通路機制,確定事務隻能通路處于期望的一緻性級别下的資料。
在SQL Server中,一般采用鎖機制來控制,下文中,我們會詳細論述。
(4)持久性(Durability)
我們對資料表進行操作時,一般會按照先後順序執行如下兩步:
第一步:将對資料表操作寫入到磁盤上資料庫的事務日志中(持久還到磁盤事務日志中);
第二步:完成第一步後,再将對資料表操作寫入到磁盤上資料庫的資料分區中(持久化到磁盤上資料庫分區中);
關于如上兩步,我們來想想可能發生的問題:
問題1:完成如上第一步之前,系統發生故障(如系統異常,系統重新開機),資料庫引擎會怎麼做?
由于未完成第一步,送出指令還未記錄到磁盤的事務日志中,此時事務并未持久化,系統發生故障後,SQL Server
會檢查每個資料庫的事務日志,進行恢複處理(恢複處理一般分為重做階段和撤銷階段),此時的恢複處理為重做階段,即送出指令還未記錄到磁盤的事務日志中,
資料庫引擎會撤銷這些事務所做的所有修改,這個過程也成為復原。
問題2:完成如上第一步但還未完成第二步,系統發生故障(如系統異常,系統重新開機),資料庫引擎會怎麼做?
完成第一步後,送出指令已記錄到磁盤的事務日志中,無論資料操作是否被寫入到磁盤的資料分區,此時事務已持久化,系統發生故障後,SQL Server
會檢查每個資料庫的事務日志,進行恢複處理(恢複處理一般分為重做階段和撤銷階段),此時的恢複處理為重做階段,即由于資料修改還沒有運用到資料分區的事務,
資料庫引擎會重做這些事務所做的所有修改,這個過程也成為前滾。
三 事務的隔離級别和隔離級别産生的一緻性問題
1 未送出讀(READ UNCOMMITTED)
未送出讀(READ UNCOMMITTED)指讀取未送出的資料,此時産生的資料不一緻性,我們稱為資料髒讀。
1.1 未送出讀為什麼會産生資料髒讀
未送出讀是最低級的隔離級别,在這個隔離級别運作的事務,讀操作是不需要請求共享鎖的,如果讀操作不需要共享鎖,就不會産生與持有排它鎖的事務操作發生沖突,
那麼也就是說,在這個事務隔離級别,讀操作可以與寫操作同時進行,互不排斥,讀操作可以讀取寫操作未送出的修改,進而造成資料的不一緻性,這種情況,我們稱
資料髒讀。
1.2 圖解資料髒讀
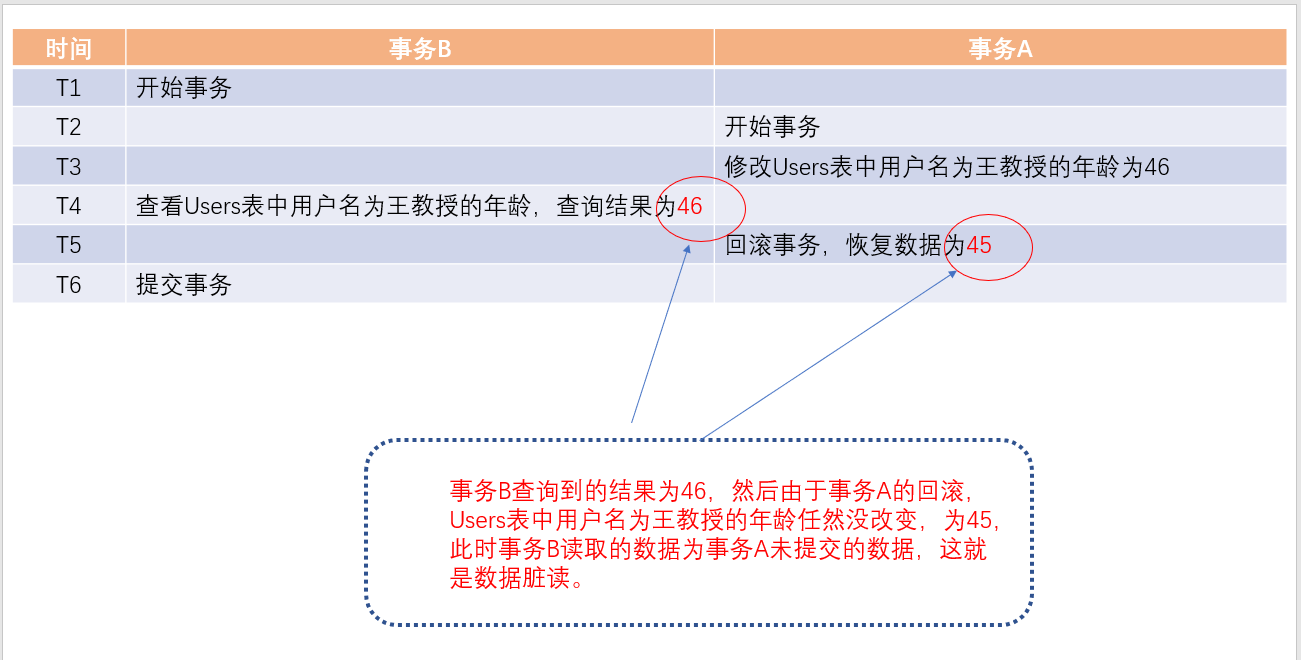
1.3 SQL示範資料髒讀

2 已送出讀(READ COMMITTED)
已送出讀(READ COMMITTED)指隻能讀取已送出事務的資料,是防止資料髒讀的最低隔離級别,也是SQL Server預設的隔離級别,它要求讀操作必須獲得共享鎖後
才能進行操作,防止讀取未送出的修改,雖然已送出讀能防止産生資料髒讀,但卻不可避免不可重複讀資料一緻性問題。
2.1 為什麼已送出讀能夠防止資料髒讀
已送出讀隻允許讀取事務已送出的資料,它要求讀操作必須獲得共享鎖才能盡心操作,而讀操作的共享鎖與寫操作的排他鎖是互斥的,兩者互斥會發生沖突,是以讀操作
在讀取資料時,必須等待寫操作完成後,才能擷取共享鎖,然後才能讀取資料,此時讀取的資料是已經送出結束的資料,是以就防止了資料髒讀的問題。
2.2 SQL示範已送出讀
2.3 為什麼已送出讀會産生不可重複讀問題
我們知道,雖然已送出讀能獲得共享鎖,然而,讀操作一完成,就會立即釋放資源上的共享鎖(該操作不會在事務持續期間一緻保留共享鎖),如此就會産生一個問題,
即在一個事務處理内部對相同資料資源讀操作之間,沒有共享鎖會鎖定該資源,導緻其他事務可以在兩個讀操作之間更改資料資源,讀操作因而可能每次得到不同的
取值,這種現象稱為資料的不可重複讀。
2.4 圖解不可重複讀
3 可重複讀(REPEATABLE READ)
為了防止不可重複讀現象,SQL Sever中采用隔離級别更新的方式,即将已送出讀更新為可重複讀。在可重複讀隔離級别下,事務中的讀操作不僅能獲得共享鎖,
而且獲得的共享鎖一直保持到事務完成為止, 在該事務完成之前,其他事務不可能獲得排他鎖來修改這一資料,如此,便實作了可重複讀,防止了不可重複讀造
成的資料不一緻性。可重複讀不僅能解決不可重複讀資料不一緻性問題,還能解決丢失更新問題。然而,可重複讀也存在問題,那就是死鎖和幻讀等問題。
3.1 SQL示範可重複讀
3.2 何為丢失更新?
在比可重複讀低的隔離級别中,兩個事務在讀取資料之後就不再持有該資源的任何鎖,此時,兩個事務都能更新這個值,
進而發生最後事務更新的值覆寫前面事務更新的值,進而造成資料的丢失,這稱為丢失更新。
3.3 圖解丢失更新
4 可序列化(SERIALIZABLE)
4.1 何為幻讀?
我們知道,在可重複讀隔離級别下,讀事務持有的共享鎖一直保持到該事務完成為止,但是事務隻鎖定查詢第一次運作時找到的那些資料資源(如,行),
而不會鎖定查詢結果範圍以外的其他行(其實,控制事務時,有資料庫架構級别,表,頁和行等)。是以,在同一事務中進行第二次讀取之前,若其他事
務插入新行,并且新行能滿足讀操作的查詢過濾條件,那麼這些新行也會出現在第二次讀操作傳回的結果中,這些新行稱為幻影子,也叫做幻讀。
4.2 圖解幻讀
4.3 如何解決幻讀?
SQL SERVER中,更進階别的可序列化(SERIALIZABLE)能夠解決該問題。
4.4 何為可序列化(SERIALIZABLE)?
大多數時候,可序列化(SERIALIZABLE)隔離級别的處理方式和可重複都得處理方式是類似的,隻不過,可序列化(SERIALIZABLE)隔離級别
增加了一個新的内容——邏輯上,這個隔離級别會讓讀操作鎖定滿足查詢搜尋條件的鍵的整範圍,這就意味着讀操作不僅鎖定了滿足查詢搜尋
條件的現有的那些行,還鎖定了未來可能滿足查詢搜尋條件的行。
5 SNAPSHOT
略。
四 事務的隔離級别總結
下表總結了每種隔離級别與邏輯一緻性問題,檢測沖突和行版本控制之間關系
五 鎖定
1 兩種并發控制模型
關于并發控制模型,主要有兩種,即悲觀控制模型和樂觀控制模型。
(1)悲觀控制模型: 該模型假設總是存在多個事務對同一資源操作(讀/寫),即假定沖突總是會發生。在SQL Server中,采用事務
隔離級别來控制(也可叫做采用鎖來控制)。一般在事務發生沖突前進行控制,也叫事前控制;
(2)樂觀控制模型:該模型與悲觀控制模型是對立的,即該模型總是假設系統中并不存在或較少存在多個事務對同一資源操作(讀/寫)
,即假定沖突是不會發生的或很少發生的。在SQL Server中,采用行版本控制來處理。一般在事務發生沖突後進行控制,也叫事後
控制;
2 何為鎖定及鎖定的種類
2.1 何為鎖定
鎖定,指在并發操作時,確定資料的一緻性所采用的一種手段。在SQL Server中,采用鎖機制與事務隔離級别來控制資料的一緻性,
2.2 鎖定的種類
常用的四大類鎖包括:共享鎖,意向鎖,更新鎖和排他鎖。
(1)共享鎖:在SQL SERVER中,當事務要讀取資料時,需要擷取共享鎖。
(2)意向鎖:在SQL SERVER中,準确來說,意向鎖并不是一種獨立的鎖,其主要作用在于擷取鎖的控制粒度(如,頁,表,行等)。
(3)更新鎖:在SQL SERVER中,準确來說,更新鎖并不是一種獨立的鎖,而是由共享鎖和排它鎖組成的混合鎖,其隔離級别高于共享鎖,
低于排他鎖,更新鎖能夠預防鎖更新而産生的死鎖。
(4)排它鎖:在SQL SERVER中,當事務要寫資料、更細資料和删除資料時,需要擷取排他鎖。
3 鎖的控制粒度
在SQL SERVER中,鎖可以控制表,頁和行等資源。
六 參考文獻
【01】Microsoft SqlServer 2008技術内幕:T-SQL 語言基礎
【02】Microsoft SqlServer 2008技術内幕:T-SQL 查詢
七 服務區
有喜歡的朋友,可以看一下,不喜歡的的朋友,勿噴,謝謝!!
八 版權區
- 感謝您的閱讀,若有不足之處,歡迎指教,共同學習、共同進步。
- 部落客網址:http://www.cnblogs.com/wangjiming/。
- 極少部分文章利用讀書、參考、引用、抄襲、複制和粘貼等多種方式整合而成的,大部分為原創。
- 如您喜歡,麻煩推薦一下;如您有新想法,歡迎提出,郵箱:[email protected]。
- 可以轉載該部落格,但必須著名部落格來源。