利用Python編寫簡單網絡爬蟲執行個體2
by:授客 QQ:1033553122
實驗環境
python版本:3.3.5(2.7下報錯
實驗目的
擷取目标網站“http://www.51testing.com/html/index.html”中特定url,通過分析發現,目标url同其它url的關系如下
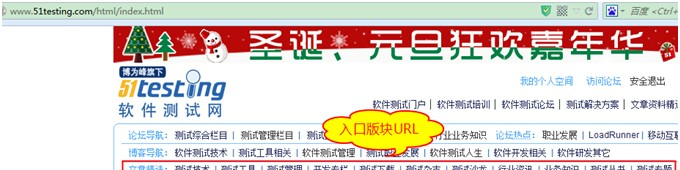

目标url存在子頁面中的文章中,随機分布,我們要把它找出來
python腳本
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from urllib.request import *
import gzip, re
from io import BytesIO
from html.parser import HTMLParser
#
爬蟲類
class Reptile:
"""to download web pages"""
def __init__(self):
self.url_set = set() #
用于存儲已下載下傳過的頁面url
self.data = ""
下載下傳網頁
def get_page(self, url, headers):
request = Request(url, headers=headers)
request.add_header('Accept-encoding', 'gzip') #下載下傳經過gzip方式壓縮後的網頁,減少網絡流量
try:
response = urlopen(request) #
發送請求封包
if response.code == 200: #
請求成功
page = response.read() #
讀取經壓縮後的頁面
if response.info().get("Content-Encoding") == "gzip":
page_data = BytesIO(page)
gzipper = gzip.GzipFile(fileobj = page_data)
self.data = gzipper.read()
else:
print("gzip unused")
self.data = page_data #
網頁未采用gzip方式壓縮,使用原頁面
except Exception:
pass
self.url_set.add(url)
return self.data
擷取網站入口版塊的url
def get_board_url(self, url_set, include):
board_url_set = set() #
用于存放版塊url
while len(url_set) > 0:
url = url_set.pop()
if re.findall(include, url):
board_url_set.add(url)
return board_url_set
入口版塊
轉換前URL:http://www.51testing.com/?action_category_catid_90.html
入口版塊的子版塊,轉換前URL:http://www.51testing.com/?action-category-catid-91
轉換後URL:http://www.51testing.com/html/90/category-catid-90.html
入口版塊及其子版塊url轉換
def convert_board_url(self, url_set, if_sub=False):
tmp_url_set = set()
for url in url_set:
str1 = re.findall("[?].+[\d]+", url)
str2 = re.findall("[?].+[-|_]+", url) #
存放url中需要被替換的字元串
if str1[0][-2:].isdigit():
var = str1[0][-2:]
var = str1[0][-1:]
replace_str = "html/"+var+"/category-catid-"
url_new = url.replace("".join(str2), replace_str)
if if_sub:
如果為子版塊,需要添加.html結尾字元串
url_new
= url_new + ".html"
tmp_url_set.add(url_new)
return tmp_url_set
翻頁頁面,轉換前URL:http://www.51testing.com/?action-category-catid-91-page-2
轉換後URL:http://www.51testing.com/html/91/category-catid-91-page-2.html
轉換子版塊下子頁面的url
def convert_sub_page_url(self, url_set):
str1 = re.findall("[?].+-catid-[\d]+", url)
str2 = re.findall("[?].+[-|_]catid", url) #
var = str1[0][-1:]
replace_str = "html/"+var+"/category-catid"
url_new = url_new + ".html"
擷取web頁面url下的文章url
def get_title_url(self, url_set, include):
title_url_set = set() #
用于存放文章url
title_url_set.add(url)
return title_url_set
文章,轉換前URL:
轉換後URL:http://www.51testing.com/?action-viewnews-itemid-1262758
轉換文章url:http://www.51testing.com/html/58/n-1262758.html
def conver_tilte_url(self, url_set):
replace_str = "html/"+var+"/n-"
return tmp_url_set
解析器類
class MyHtmlParser(HTMLParser):
def reset(self):
HTMLParser.reset(self) #
注意順序
self.url_set = set()
def handle_starttag(self, tag, attrs):
#self.url = []
url_list = [value for key, value in attrs if "href" ==
key]
if url_list:
for url in url_list:
##############測試################
添加頭域,僞裝浏覽器通路網站,防止一些網站拒絕爬蟲通路
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1;
WOW64; rv:33.0) Gecko/20100101 Firefox/33.0"}
init_url =
"http://www.51testing.com/html/index.html"
構造解析器
parser = MyHtmlParser(strict = False)
下載下傳網頁
print("program is downloading the frist url
page")
reptile = Reptile()
page = reptile.get_page(init_url, headers)
print("processing the first url page")
解析網頁(擷取url)
parser.feed(str(page))
擷取入口版塊url
pattern =
"http://www.51testing.com/[?]action[_|-]category[_|-]catid[_|-][\d]+[.]html"
include = re.compile(pattern)
board_url_set = reptile.get_board_url(parser.url_set,
include)
轉換入口版塊url
board_url_set_new =
reptile.convert_board_url(board_url_set)
擷取每個入口版塊下的子版塊url("更多"頁面)
"http://www.51testing.com/[?]action[_|-]category[_|-]catid[_|-][\d]+$"
sub_board_url_set = set()
board_index = 1
for board_url in board_url_set_new:
page = reptile.get_page(board_url, headers)
print("getting subboard urls in the %dth web board page" %
board_index)
tmp_url_set = reptile.get_board_url(parser.url_set,
board_index = board_index + 1
sub_board_url_set = sub_board_url_set ^ tmp_url_set
轉換入口版塊的子版塊的url
sub_board_url_set_new =
reptile.convert_board_url(sub_board_url_set, True)
#for url in sub_board_url_set_new:
#
print(url)
擷取子版塊的子頁面url(點選數字頁号翻頁後的"頁面",預設為前10頁)
"http://www.51testing.com/?action-category-catid-[\d]+-page-[\d]$"
sub_page_url_set = set()
for sub_page_url in sub_board_url_set_new:
page = reptile.get_page(sub_page_url, headers)
print("getting sub page urls in the %dth web page" %
sub_page_url_set = sub_page_url_set ^ tmp_url_set
#for url in sub_page_url_set:
print(url)
轉換子版塊下的子頁面url
sub_page_url_set =
reptile.convert_sub_page_url(sub_page_url_set)
擷取所有web頁面
web_page_set = sub_board_url_set_new ^
sub_page_url_set
擷取頁面文章
title_url_set = set()
title_index = 1
for page_url in web_page_set:
page = reptile.get_page(page_url, headers)
擷取每個web頁面下文章url
"http://www.51testing.com/[?]action-viewnews-itemid-[\d]+"
print("getting all title urls in the %dth web board" %
tmp_url_set = reptile.get_title_url(parser.url_set,
title_url_set = title_url_set ^ tmp_url_set
title_url_set_new =
reptile.conver_tilte_url(title_url_set)
擷取每篇文章下的目标url并寫入檔案
target_index = 1
filepath = "d:/url2.txt"
for title_url in title_url_set_new:
print("processing the %dth title url" % title_index)
page = reptile.get_page(title_url, headers)
儲存目标url
with open(filepath, "a") as f:
while len(parser.url_set) > 0:
url = parser.url_set.pop()
"http://bbs.51testing.com/treasure/treasure.php[?]trenum=[0-9]{5}"
flag = re.findall(include, url)
if flag:
print("find target! saving the %dth target url in the %dth title
page" % (target_index, title_index))
f.write("the %dth url: %s" % (target_index, url))
target_index = target_index + 1
f.write("\n")
title_index = title_index + 1
print("----------------complete-------------------")
結果:
聲明:僅供學習研究使用,請勿用于其它非法用途
作者:授客
QQ:1033553122
全國軟體測試QQ交流群:7156436
Git位址:https://gitee.com/ishouke
友情提示:限于時間倉促,文中可能存在錯誤,歡迎指正、評論!
作者五行缺錢,如果覺得文章對您有幫助,請掃描下邊的二維碼打賞作者,金額随意,您的支援将是我繼續創作的源動力,打賞後如有任何疑問,請聯系我!!!
微信打賞
支付寶打賞 全國軟體測試交流QQ群