此文已由作者肖凡授權網易雲社群釋出。
歡迎通路網易雲社群,了解更多網易技術産品營運經驗。
背景
考拉安全部技術這塊目前主要負責兩塊業務:一個是内審,主要是通過敏感日志管理平台搜集考拉所有背景系統的記錄檔,資料導入到es後,結合storm進行實時計算,主要有行為查詢、資料監控、事件追溯、風險大盤等功能;一個是業務風控,主要是下單、支付、優惠券、紅包、簽到等行為的風險控制,對抗的風險行為包括黃牛刷單、惡意占用庫存、機器領券、撸羊毛等。這兩塊業務其實有一個共通點,就是有大量需要進行規則決策的場景,比如内審中需要進行實時監控,當同一個人在一天時間内的導出操作超過多少次後進行告警,當登入時不是常用地登入并且裝置指紋不是該賬号使用過的裝置指紋時告警。而在業務風控中需要使用到規則決策的場景更多,由于涉及規則的保密性,這裡就不展開了。總之,基于這個出發點,安全部決定開發出一個通用的規則引擎平台,來滿足以上場景。
寫在前面
在給出整體架構前,想跟大家聊聊關于架構的一些想法。目前架構上的分層設計思想已經深入人心,大家都知道要分成controller,server,dao等,是因為我們剛接觸到編碼的時候,mvc的模型已經大行其道,早期的jsp裡面包含大量業務代碼邏輯的方式已經基本絕迹。但是這并不是一種面向對象的思考方式,而往往我們是以一種面向過程的思維去程式設計。舉個簡單例子,我們要實作一個網銀賬戶之間轉賬的需求,往往會是下面這種實作方式:
- 設計一個賬戶交易服務接口AccountingService,設計一個服務方法transfer(),并提供一個具體實作類AccountingServiceImpl,所有賬戶交易業務的業務邏輯都置于該服務類中。
- 提供一個AccountInfo和一個Account,前者是一個用于與展示層交換賬戶資料的賬戶資料傳輸對象,後者是一個賬戶實體(相當于一個EntityBean),這兩個對象都是普通的JavaBean,具有相關屬性和簡單的get/set方法。
- 然後在transfer方法中,首先擷取A賬戶的餘額,判斷是否大于轉賬的金額,如果大于則扣減A賬戶的餘額,并增加對應的金額到B賬戶。
這種設計在需求簡單的情況下看上去沒啥問題,但是當需求變得複雜後,會導緻代碼變得越來越難以維護,整個架構也會變的腐爛。比如現在需要增加賬戶的信用等級,不同等級的賬戶每筆轉賬的最大金額不同,那麼我們就需要在service裡面加上這個邏輯。後來又需要記錄轉賬明細,我們又需要在service裡面增加相應的代碼邏輯。最後service代碼會由于需求的不斷變化變得越來越長,最終變成别人眼中的“祖傳代碼”。導緻這個問題的根源,我認為就是我們使用的是一種面向過程的程式設計思想。那麼如何去解決這種問題呢?主要還是思維方式上需要改變,我們需要一種真正的面向對象的思維方式。比如一個“人”,除了有id、姓名、性别這些屬性外,還應該有“走路”、“吃飯”等這些行為,這些行為是天然屬于“人”這個實體的,而我們定義的bean都是一種“失血模型”,隻有get/set等簡單方法,所有的行為邏輯全部上升到了service層,這就導緻了service層過于臃腫,并且很難複用已有的邏輯,最後形成了各個service之間錯綜複雜的關聯關系,在做服務拆分的時候,很難劃清業務邊界,導緻服務化程序陷入泥潭。
對應上面的問題,我們可以在Account這個實體中加入本應該就屬于這個實體的行為,比如借記、貸記、轉賬等。每一筆轉賬都對應着一筆交易明細,我們根據交易明細可以計算出賬戶的餘額,這個是一個潛在的業務規則,這種業務規則都需要交由實體本身來維護。另外新增賬戶信用實體,提供賬戶單筆轉賬的最大金額計算邏輯。這樣我們就把原本全部在service裡面的邏輯劃入到不同的負責相關職責的“領域對象”當中了,service的邏輯變得非常清楚明了,想實作A給B轉賬,直接擷取A實體,然後調用A實體中的轉賬方法即可。service将不再關注轉賬的細節,隻負責将相關的實體組織起來,完成複雜的業務邏輯處理。
上面的這種架構設計方式,其實就是一種典型的“領域驅動設計(DDD)”思想,在這裡就不展開說明了(主要是自己了解的還不夠深入,怕誤導大家了)。DDD也是目前非常熱門的一種架構設計思想了,它不能減少你的代碼量,但是能使你的代碼具有很高的内聚性,當你的項目變得越來越複雜時,能保持架構的穩定而不至于過快的腐爛掉,不了解的同學可以檢視相關資料。要說明的是,沒有一種架構設計是萬能的、是能解決所有問題的,我們需要做的是吸收好的架構設計思維方式,真正架構落地時還是需要根據實際情況選擇合适的架構。
整體架構設計
上面說了些架構設計方面的想法,現在我們回到規則引擎平台本身。我們抽象出了四個分層,從上到下分别為:服務層、引擎層、計算層和存儲層,整個邏輯層架構見下圖:
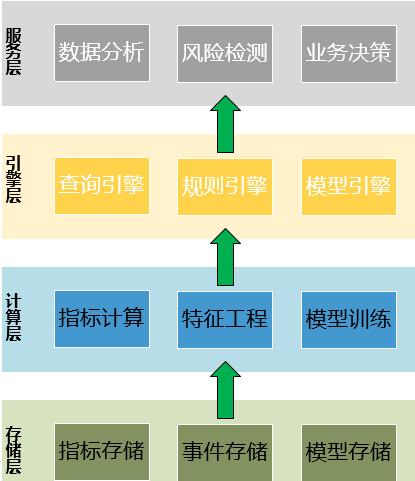
- 服務層:服務層主要是對外提供服務的入口層,提供的服務包括資料分析、風險檢測、業務決策等,所有的服務全部都是通過資料接入子產品接入資料,具體後面講
- 引擎層:引擎層是整個平台的核心,主要包括了執行規則的規則引擎、還原事件現場和聚合查詢分析的查詢引擎以及模型預測的模型引擎
- 計算層:計算層主要包括了名額計算子產品和模型訓練子產品。名額會在規則引擎中配置規則時使用到,而模型訓練則是為模型預測做準備
- 存儲層:存儲層包括了名額計算結果的存儲、事件資訊詳情的存儲以及模型樣本、模型檔案的存儲
在各個分層的邏輯架構劃定後,我們就可以開始分析整個平台的業務功能子產品。主要包括了事件接入子產品、名額計算子產品、規則引擎子產品、營運中心子產品,整個業務架構如下圖:

1.事件接入中心
事件接入中心主要包括事件接入子產品和資料管理子產品。資料接入子產品是整個規則引擎的資料流入口,所有的業務方都是通過這個子產品接入到平台中來。提供了實時(dubbo)、準實時(kafka)和離線(hive)三種資料接入方式。資料管理子產品主要是進行事件的中繼資料管理、标準化接入資料、補全必要的字段,如下圖:
2.名額計算子產品
名額計算子產品主要是進行名額計算。一個名額由主次元、從次元、時間視窗等組成,其中主次元至少有一個,從次元最多有一個。如下圖:
舉個例子,若有這樣一個名額:“最近10分鐘,同一個賬号在同一個商家的下單金額”,那麼主次元就是下單賬号+商家id,從次元就是訂單金額。可以看到,這裡的主次元相當于sql裡面的group by,從次元相當于count,數值累加相當于sum。從關于名額計算,有幾點說明下:
- key的構成。我們的名額存儲是用的redis,那麼這裡會涉及到一個key該如何建構的問題。我們目前的做法是:key=名額id+版本号+主次元值+時間間隔序号。
- 名額id就是名額的唯一标示;
- 版本号是名額對象的版本,每次更新完名額都會更新對應的版本号,這樣可以讓就的名額一次全部失效;
- 主次元值是指目前事件對象中,主次元字段對應的值,比如一個下單事件,主次元是使用者賬号,那麼這裡就是對應的類似[email protected],如果有多個主次元則需要全部組裝上去;
- 如果主次元的值出現中文,這樣直接拼接在key裡面會有問題,可以采用轉義或者md5的方式進行。
- 時間間隔序号是指目前時間減去名額最後更新時間,得到的內插補點再除以采樣周期,得到一個序号。這麼做主要是為了實作名額的滑動視窗計算,下面會講
3.規則引擎子產品
計劃開始做規則引擎時進行過調研,發現很多類似的平台都會使用drools。而我們從一開始就放棄了drools而全部使用groovy腳本實作,主要是有以下幾點考慮:
- drools相對來說有點重,而且它的規則語言不管對于開發還是營運來說都有學習成本
- drools使用起來沒有groovy腳本靈活。groovy可以和spring完美結合,并且可以自定義各種元件實作插件化開發。
- 當規則集變得複雜起來時,使用drools管理起來有點力不從心。
當然還有另外一種方式是将drools和groovy結合起來,綜合雙方的優點,也是一種不錯的選擇,大家可以嘗試一下。
規則引擎子產品是整個平台的核心,我們将整個子產品分成了以下幾個部分:
規則引擎在設計中也碰到了一些問題,這裡給大家分享下一些心得:
- 使用插件的方式加載各種元件到上下文中,極大的友善了功能開發的靈活性。
- 使用預加載的方式加載已有的規則,并将加載後的對象緩存起來,每次規則變更時重新load整條規則,極大的提升了引擎的執行效率
- 計數器引入AtomicLongFieldUpdater工具類,來減少計數器的記憶體消耗
- 靈活的上下文使用方式,友善定制規則執行的流程(規則執行順序、同步異步執行、跳過某些規則、規則集短路等),靈活定義傳回結果(可以傳回整個上下文,可以傳回每條規則的結果,也可以傳回最後一條規則的結果),這些都可以通過設定上下文來實作。
- groovy的方法查找政策,預設是從metaClass裡面查找,再從上下文裡找,為了提升性能,我們重寫了metaClass,修改了這個查詢邏輯:先從上下文裡找,再從metaClass裡面找。
規則配置如下圖所示:
未來規劃
後面規則引擎平台主要會圍繞下面幾點來做:
- 名額存儲計劃從redis切換到hbase。目前的名額計算方式會導緻緩存key的暴漲,擷取一個名額值可能需要N個key來做累加,而換成hbase之後,一個名額就隻需要一條記錄來維護,使用hbase的列族來實作滑動視窗的計算。
- 規則的灰階上線。當一條新規則建立後,如果不進行灰階的測試,直接上線是可能會帶來災難的。後面再規則上線流程中新增灰階上線環節,整個引擎會根據配置的灰階比例,複制一定的流量到灰階規則中,并對灰階規則的效果進行展示,達到預期效果并穩定後才能審批上線。
- 事件接入的自動化。dubbo這塊可以采用泛化調用,http接口需要統一調用标準,消息需要統一格式。有了統一的标準就可以實作事件自動接入而不需要修改代碼上線,這樣也可以保證整個引擎的穩定性。
- 模型生命周期管理。目前模型這塊都是通過在猛犸平台上送出jar包的方式,離線跑一個model出來,沒有一個統一的平台去管控整個模型的生命周期。現在杭研已經有類似的平台了,後續需要考慮如何介入。
- 資料展示優化。現在整個平台的數字化做的比較弱,沒法形成資料驅動業務。而風控的營運往往是需要大量的資料去驅動規則的優化的,比如規則門檻值的調試、規則命中率、風險大盤等都需要大量資料的支撐。
網易雲免費體驗館,0成本體驗20+款雲産品!
更多網易技術、産品、營運經驗分享請點選。
相關文章:
【推薦】 TiDB和MongoDB分片叢集架構比較
【推薦】 淺談代碼結構的設計
【推薦】 6本網際網路技術暢銷書免費送(資料分析、深度學習、程式設計語言)!