摘要:伴随着微服務架構被宣傳得如火如荼,一些概念也被推到了我們面前。服務熔斷、服務降級,好高大上的樣子,以前望塵莫及,今日終于揭開它神秘面紗。
服務雪崩效應的定義很簡單,是一種因服務提供者的不可用導緻服務調用者的不可用,并将不可用逐漸放大的過程。
可以結合下圖進行了解:
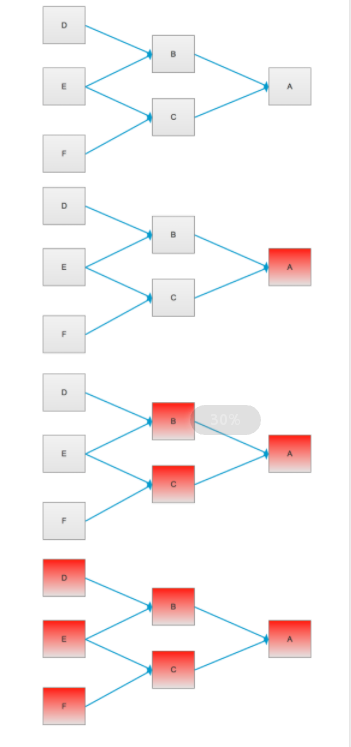
服務雪崩
上圖中,A作為基礎的服務提供者,為B和C提供服務,D、E、F是B和C服務的調用者,當A不可用時,将引起B和C的不可用,并将這種不可用放大到D、E、F,進而可能導緻整個系統的不可用,服務雪崩的産生可能導緻分布式系統的癱瘓。
服務雪崩效應的産生一般有三個流程,服務提供者不可用 -> 重試加大流量 -> 服務調用者不可用
服務提供者不可用的出現的原因有很多,可能是因為伺服器的當機或者網絡故障,也可能是因為程式存在的Bug,也有可能是大量的請求導緻服務提供者的資源受限無法及時響應,還有可能是因為緩存擊穿造成服務提供者超負荷運作等等,畢竟沒有人能保證軟體的完全正确性。
在服務提供者不可用發生之後,使用者可能無法忍受長時間的等待,不斷地發送相同的請求,服務調用者重新調用服務提供者,同時服務提供者中可能存在對異常的重試機制,這些都會加大對服務提供者的請求流量。然而此時的服務提供者已經是一艘破船,它也無能無力,無法傳回有效的結果。
最後是服務調用者因為服務提供者的不能用導緻了自身的崩潰。當服務調用者使用同步調用的時候,大量的等待線程将會耗盡線程池中的資源,最終導緻服務調用者的當機,無法響應使用者的請求,服務雪崩效應就此發生了。
斷路器
在分布式系統中,不同服務之間發生的調用非常常見,當服務提供者不可用時就很有可能發生服務雪崩的效應,導緻整個系統的不可用。是以為了預防這種請求的發生,可以通過斷路器模式進行預防(類比電路中的斷路器,在電路過大的時候自動斷開,防止電線過熱損害整條電路)。
斷路器模式背後的思想很簡單,将遠端函數調用包裝到一個斷路器對象中,用于監控函數調用過程的失敗。一旦該函數調用的發生失敗的次數在一段時間内到達一定的閥值,那麼這個斷路器将會跳閘,然後接下來時間裡對該被保護函數調用的線程将會被斷路器直接傳回一個錯誤,而不再發生該函數的真實調用。這樣子就避免了服務調用者在服務提供者不可用時發送請求,進而減少線程池中資源的消耗,保護了服務調用者。

斷路器時序圖
雖然上面的斷路器在打開的時候避免了被保護的函數調用,但是當情況恢複正常時,需要外部幹預來重置斷路器,使得函數調用可以重新發生。是以合理的斷路器應該具備以下的開關轉化邏輯,它需要一個機制來控制它的重新閉合,圖6-3中是通過一個重置時間來決定。
斷路器狀态圖
- 關閉狀态: 斷路器處于關閉狀态,統計調用失敗次數,在一段時間内到達一定的閥值後斷路器打開。
- 打開狀态: 斷路器處于打開狀态,對函數調用直接傳回失敗錯誤,不發生真正的函數調用。設定了一個重置時間窗,在重置時間窗結束後,斷路器來到半開狀态。
- 半開狀态: 斷路器處于半開狀态,此時允許進行函數調用,當調用都成功了(或者成功到達一定的比例),關閉斷路器,否則認為服務沒有恢複,重新打開斷路器。
斷路器的打開能保證服務調用者在調用異常服務時,快速傳回結果,避免大量的同步等待,減少服務調用者的資源消耗。并且斷路器能在打開的一段時間後繼續偵測請求執行結果,提供斷路器關閉的可能,恢複服務的調用。
服務降級操作
斷路器是為了隔斷服務調用者和異常服務提供者,防止了服務雪崩的現象,是一種保護的措施。而服務降級的意思是在整體資源不夠的時候,适當的放棄部分服務,将主要的資源投放到核心服務中,待渡過難關之後,再把關閉的服務重新開機回來。
在Hystrix中,當服務間調用發生問題時,它将采用備用的fallback方法代替主方法執行并傳回結果,這就進行了服務降級,同時觸發了斷路器的邏輯。當調用服務失敗次數在一段時間内超過了斷路器的閥值時(此時一直調用fallback中的邏輯傳回結果),斷路器将打開,此時将不再調用函數,而是快速失敗,直接執行fallback邏輯,服務降級,減少服務調用者的資源消耗,保護服務調用者中的線程資源。
資源隔離
在貨船中,為了防止漏水和火災的擴散,一般會将貨倉進行分割,避免了一個貨倉出事導緻整艘船沉沒的悲劇。同樣的,在Hystrix中,也采用了這樣的艙壁模式,将系統中的服務提供者隔離起來,一個服務提供者延遲升高或者失敗,并不會導緻整個系統的失敗,同時也能夠控制調用這些服務的并發度。
- 線程與線程池
Hystrix中通過将調用服務線程與服務通路的執行線程分隔開來,調用線程能夠空出來去做其他的工作而不至于被服務調用的執行的阻塞過長的時間。
在Hystrix中使用獨立的線程池對應每一個服務提供者,來隔離和限制這些服務,于是,某個服務提供者的高延遲或者飽和資源受限隻會發生在該服務提供者對應的線程池中。
如上圖中,Dependency I的調用失敗或者高延遲僅會導緻自身對應的線程池中的5個線程的阻塞,并不會影響其他服務提供者的線程池。系統完全與服務提供者請求隔離開來,即使服務提供者對應的線程完全耗盡,并不會影響系統中的其他請求。
注意在對應服務提供者的線程池被占滿時,Hystrix會進入了fallback邏輯,快速失敗,保護服務調用者的資源穩定。
- 信号量
除了線程池外,Hystrix還可以通過信号量(計數器)來限制單個服務提供者的并發量。如果通過信号量來控制系統負載,将不再允許設定逾時控制和異步化調用,這就表示在服務提供者出現高延遲,其調用線程将會被阻塞,直至服務提供者的網絡請求逾時,如果對服務提供者的穩定性有足夠的信心,可以通過信号量來控制系統的負載。
總結
我們在這篇文章介紹了熔斷、服務雪崩、服務降級等概念。在處理微服務容錯時,這些都是常用的技術,我們需要首先了解其概念。
點選關注,第一時間了解華為雲新鮮技術~