一、序言
NoSQL是Not Only SQL的縮寫,而不是Not SQL,指的是非關系型的資料庫,它不一定遵循傳統資料庫的一些基本要求,比如說遵循SQL标準、ACID屬性、表結構等等。相比傳統資料庫,叫它分布式資料管理系統更貼切,資料存儲被簡化更靈活,重點被放在了分布式資料管理上。
随着網際網路web2.0網站的興起,傳統的關系資料庫在應付web2.0網站,特别是超大規模和高并發的SNS類型的web2.0純動态網站已經顯得力不從心,暴露了很多難以克服的問題,而非關系型的資料庫則由于其本身的特點得到了非常迅速的發展。
二、大資料時代
随着網際網路 web2.0 網站的興起,非關系型的資料庫成了一個極其熱門的新領域,非關系資料庫産品的發展非常迅速。而傳統的關系資料庫在應付 web2.0 網站,特别是超大規模和高并發的SNS類型的web2.0純動态網站已經顯得力不從心,暴露了很多難以克服的問題:
1、High performance - 對資料庫高并發讀寫的需求
web2.0 網站要根據使用者個性化資訊來實時生成動态頁面和提供動态資訊,是以基本上無法使用動态頁面靜态化技術,是以資料庫并發負載非常高,往往要達到每秒上萬次讀寫請求。關系資料庫應付上萬次SQL查詢還勉強頂得住,但是應付上萬次SQL寫資料請求,硬碟IO就已經無法承受了。其實對于普通的BBS網站,往往也存在對高并發寫請求的需求。
2、Huge Storage - 對海量資料的高效率存儲和通路的需求
對于大型的SNS網站,每天使用者産生海量的使用者動态,以國外的Friendfeed為例,一個月就達到了2.5億條使用者動态,對于關系資料庫來說,在一張2.5億條記錄的表裡面進行SQL查詢,效率是極其低下乃至不可忍受的。
3、High Scalability && High Availability- 對資料庫的高可擴充性和高可用性的需求
在基于web的架構當中,資料庫是最難進行橫向擴充的,當一個應用系統的使用者量和通路量與日俱增的時候,你的資料庫卻沒有辦法像web server和app server那樣簡單的通過添加更多的硬體和服務節點來擴充性能和負載能力。對于很多需要提供24小時不間斷服務的網站來說,對資料庫系統進行更新和擴充是非常痛苦的事情,往往需要停機維護和資料遷移,為什麼資料庫不能通過不斷的添加伺服器節點來實作擴充呢?
三、關系資料庫的瓶頸
1.資料結構化,資料的橫向擴充能力底下。
(1)受業務規則影響,需求變動導緻分庫分表的維護複雜。
(2)系統資料通路層代碼需要修改。
(3)Slave實時性的保障,對于實時性很高的場合可能需要做一些處理。
(4)高可用性問題,Master就是那個緻命點,容易産生單點故障。所有的資料處理 都是由Master來進行配置設定處理,若Master出現故障,導緻整個系統崩潰。
(5)MMM叢集可以解決Master-Slave中的單個Master讀寫的緻命缺陷,但是其 擴充性差,一次隻能一個Master可以寫入,隻能解決有限資料量下的可用性。
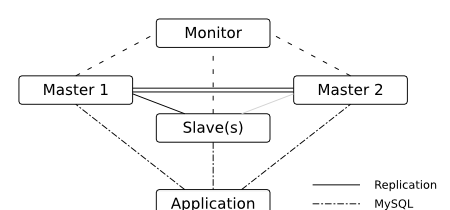
MMM叢集方案
2.量資料的高效率存儲和通路的需求滿足能力低
(1)存儲記錄數量有限,橫向可可擴充能力有限,縱向資料可承受能力也是有限的。
(2)對大資料的查詢,SQL查詢效率極低,在資料量達到一定的程度,查詢時間會成 指數級别增長。
四、NoSQL的優勢
1.易擴充
NoSQL資料庫種類繁多,但是一個共同的特點都是去掉關系資料庫的關系型特性。資料之間無關系,這樣就非常容易擴充。也無形之間,在架構的層面上帶來了可擴充的能力。甚至有多種NoSQL之間的整合。
2.靈活的資料模型
NoSQL無需事先為要存儲的資料建立字段,随時可以存儲自定義的資料格式。而在關系資料庫裡,增删字段是一件非常麻煩的事情。如果是非常大資料量的表,增加字段簡直就是一個噩夢。
3.高可用
NoSQL在不太影響性能的情況,就可以友善的實作高可用的架構。比如Cassandra,HBase模型,通過複制模型也能實作高可用。
4.大資料量,高性能
NoSQL資料庫都具有非常高的讀寫性能,尤其在大資料量下,同樣表現優秀。這得益于它的無關系性,資料庫的結構簡單。
五、NoSQL在大資料中的應用
1.NoSQL在hadoop中運用
在大資料處理系統的架構中,目前首選的就是由Apache基金會所開發hadoop,Hadoop實作了一個分布式檔案系統(Hadoop Distributed File System),簡稱HDFS。HDFS有高容錯性的特點,并且設計用來部署在低廉的(low-cost)硬體上;而且它提供高傳輸率(high throughput)來通路應用程式的資料,适合那些有着超大資料集(large data set)的應用程式。下圖為hadoop的構架圖:

從hadoop的構架圖中可以看出,它具有這種處理大資料的能力一方面來自自身的算法設計,另一方面就是來源于它的架構原理,在架構原理圖中,可以清楚的看到NoSQL在資料讀取中的作用,由此可以看出NoSQL在大資料進行中的優勢。值得一提的是hadoop中使用的是Hbase這種NoSQL資料庫,具有實時、分布式、高維等特性。
2.Sina App Engine(簡稱SAE)(新浪雲計算平台)
是新浪研發中心于2009年8月開始内部開發,并在2009年11月3日正式推出第一個Alpha版本的國内首個公有雲計算平台,SAE是新浪雲計算戰略的核心組成部分。下圖是NoSQl資料庫在SAE中的應用,其中KVDB在分布式key/value存儲服務上起着重要的作用。
3.NoSQL在淘寶資料架構中的運用
淘寶每天能承受巨大的實時交易與互動資料,那它的背後是怎樣設計與架構的呢?在淘寶的資料處理架構中使用了hadoop作為資料處理工具,采用NoSQl作為資料存儲間質,從分利用NoSQl在大資料進行中的優勢。下圖為淘寶的資料架構圖。
六、常用的NoSQL資料庫
按照資料模型儲存性質将目前NoSQL分為四種:
1.Key-value stores鍵值存儲, 儲存keys+BLOBs (二進制大對象Binary Large OBjects)
2.Table-oriented 面向表, 主要有Google的BigTable和Cassandra.
3.Document-oriented面向文本, 文本是一種類似XML文檔,MongoDB 和 CouchDB
4.Graph-oriented 面向圖論. 如Neo4J.