每篇一句
用正确的廢話做指導思想是脫離實際的,用謙卑的心态來市場照鏡子才是可取之法
前言
前面通過三篇文章介紹了
HandlerMethodArgumentResolver
這個參數解析器以及它的所有内置實作,相信看過的小夥伴對它的加載、初始化、處理原理等等已能夠做到了心中有數了。
Spring MVC
内置注冊了灰常多的處理器給我們的使用,不客氣說幾乎
100%
的case我們都是足夠用了的。但既然我們已經了解到了
HandlerMethodArgumentResolver
它深層的作用原理,那麼本文就通過自定義參數處理器,來做到屏蔽(隔離)基礎實作、更高效的編寫業務編碼(提效是本文的關注點)。
使用場景
關于它的應用場景可以非常多,本文我總結出最為常見、好了解的兩個應用場景作為舉例說明:
- 擷取目前登陸人(當然使用者)的基本資訊
- 調整(相容)資料結構
場景一:
在
Controller
層擷取目前登陸人的基本資訊(如id、名字…)是一個必須的、頻繁的功能需求,這個時候如果團隊内沒有提供相關封裝好的方法來調用,你便可看到大量的、重複的擷取目前使用者的代碼,這就是各位經常吐槽的垃圾代碼~
一般團隊的做法是:提供
BaseController
,在基類裡面提供擷取目前使用者的功能方法,這樣業務控制器
Controller
隻需要繼承它就有這能力了,使用起來确實也還挺友善的。但是是否還思考過這種通過繼承的方式它是有弊端的–>我隻想擷取目前登陸人我就得繼承一個父類?這是不是設計太重了點?更壞的情況是如果此時我已經有父類了呢?
面對我提出的問題,本文針對性的提供一個新的、更加輕量的解決思路:自定義
HandlerMethodArgumentResolver
來實作擷取目前登入使用者的解決方案。實施步驟如下:
1、自定義一個參數注解(注解并不是100%必須的,可完全根據類型來決策)
/**
* 用于擷取目前登陸人資訊的注解,配合自定義的參數處理器使用
*
* @see CurrUserArgumentResolver
*/
@Target({ElementType.PARAMETER})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface CurrUser {
}
// 待封裝的Vo
@Getter
@Setter
@ToString
public class CurrUserVo {
private Long id;
private String name;
}
2、自定義參數解析器
CurrUserArgumentResolver
并完成注冊
public class CurrUserArgumentResolver implements HandlerMethodArgumentResolver {
// 隻有标注有CurrUser注解,并且資料類型是CurrUserVo/Map/Object的才給與處理
@Override
public boolean supportsParameter(MethodParameter parameter) {
CurrUser ann = parameter.getParameterAnnotation(CurrUser.class);
Class<?> parameterType = parameter.getParameterType();
return (ann != null &&
(CurrUserVo.class.isAssignableFrom(parameterType)
|| Map.class.isAssignableFrom(parameterType)
|| Object.class.isAssignableFrom(parameterType)));
}
@Override
public Object resolveArgument(MethodParameter parameter, ModelAndViewContainer container, NativeWebRequest webRequest, WebDataBinderFactory binderFactory) throws Exception {
HttpServletRequest request = webRequest.getNativeRequest(HttpServletRequest.class);
// 從請求頭中拿到token
String token = request.getHeader("Authorization");
if (StringUtils.isEmpty(token)) {
return null; // 此處不建議做異常處理,因為校驗token的事不應該屬于它來做,别好管閑事
}
// 此處作為測試:new一個處理(寫死的)
CurrUserVo userVo = new CurrUserVo();
userVo.setId(1L);
userVo.setName("fsx");
// 判斷參數類型進行傳回
Class<?> parameterType = parameter.getParameterType();
if (Map.class.isAssignableFrom(parameterType)) {
Map<String, Object> map = new HashMap<>();
BeanUtils.copyProperties(userVo, map);
return map;
} else {
return userVo;
}
}
}
// 注冊進Spring元件内
@Configuration
@EnableWebMvc
public class WebMvcConfig extends WebMvcConfigurerAdapter {
@Override
public void addArgumentResolvers(List<HandlerMethodArgumentResolver> argumentResolvers) {
argumentResolvers.add(new CurrUserArgumentResolver());
}
}
3、書寫測試例子
@Controller
@RequestMapping
public class HelloController {
@ResponseBody
@GetMapping("/test/curruser")
public Object testCurrUser(@CurrUser CurrUserVo currUser) {
return currUser;
}
@ResponseBody
@GetMapping("/test/curruser/map")
public Object testCurrUserMap(@CurrUser Map<String,Object> currUser) {
return currUser;
}
@ResponseBody
@GetMapping("/test/curruser/object")
public Object testCurrUserObject(@CurrUser Object currUser) {
return currUser;
}
}
請求:
/test/curruser或者/test/curruser/object
這兩個請求得到的答案是一緻的且符合預期,結果如下截圖:
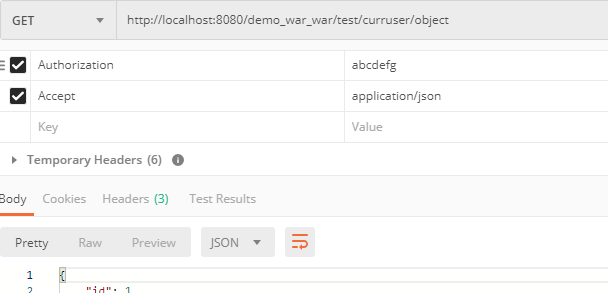
但是,但是,但是若通路
/test/curruser/map
,它的結果如下:

so參數類型是Map類型,自定義的參數解析器
CurrUserArgumentResolver
并沒有生效,為什麼呢???
帶着這個疑問,接下來我說說對此非常重要的使用細節:
如何使用
Spring
容器内的
Bean
?
在本例中,為了友善,我在
CurrUserArgumentResolver
裡寫死的自己
new
的一個
CurrUserVo
作為傳回。實際應用場景中,此部分肯定是需要根據
token
去通路
DB
/
Redis
的,是以就需要使用到
Spring
Bean
。
有的小夥伴就想當然了,在本例上直接使用
@Autowired HelloService helloService;
來使用,經測試發現這是注入不進來的,
helloService
值為null。那麼本文就教你正确的使用姿勢:
-
姿勢一:把自定義的參數解析器也放進容器
這是一種十分快捷、見效的解決方案。
@Configuration
@EnableWebMvc
public class WebMvcConfig extends WebMvcConfigurerAdapter {
@Bean
public CurrUserArgumentResolver currUserArgumentResolver(){
return new CurrUserArgumentResolver();
}
@Override
public void addArgumentResolvers(List<HandlerMethodArgumentResolver> argumentResolvers) {
argumentResolvers.add(currUserArgumentResolver());
}
這樣,你在
CurrUserArgumentResolver
就可以
順理成章
的注入想要的元件了,形如這樣:
public class CurrUserArgumentResolver implements HandlerMethodArgumentResolver {
@Autowired
HelloService helloService;
@Autowired
StringRedisTemplate stringRedisTemplate;
...
}
這種方案的優點是:在
Spring
容器内它幾乎能解決大部分類似問題,在元件不是很多的情況下,推薦新手使用,因為無需過多的了解
Spring
内部機制便可輕松使用。
- 姿勢二:借助
AutowireCapableBeanFactory
給對象賦能
本着
"減輕"
"負擔"
"手動"
Spring
Bean
@Configuration
@EnableWebMvc
public class WebMvcConfig extends WebMvcConfigurerAdapter {
@Autowired
private ApplicationContext applicationContext;
@Override
public void addArgumentResolvers(List<HandlerMethodArgumentResolver> argumentResolvers) {
CurrUserArgumentResolver resolver = new CurrUserArgumentResolver();
// 利用工廠給容器外的對象注入所需元件
applicationContext.getAutowireCapableBeanFactory().autowireBean(resolver);
argumentResolvers.add(resolver);
}
}
本姿勢的技巧是利用了
AutowireCapableBeanFactory
巧妙完成了給外部對象賦能,進而即使自己并不是容器内的Bean,也能自由注入、使用容器内
Bean
的能力(同樣可以随意使用
@Autowired
注解了~)。
這種方式是侵入性最弱的,是我推薦的方式。當然這需要你對
Spring
容器有一定的了解才能運用自如,做到心中有數才行,否則不建議你使用~
可以和内置的一些注解/類型一起使用嗎?(參數類型是Map類型?)
作為一個
"合格"
的
coder
,理應發出如題這樣的疑問。
譬如上例我這麼寫,你可以猜猜是什麼結果:
@ResponseBody
@GetMapping("/test/curruser")
public Object testCurrUser(@CurrUser @RequestParam CurrUserVo currUser) {
return currUser;
}
表面上看起來木有毛病,但請求:
/test/curruser?currUser=fsx
。報錯如下:
Resolved [org.springframework.web.method.annotation.MethodArgumentConversionNotSupportedException: Failed to convert value of type 'java.lang.String' to required type 'com.fsx.validator.CurrUserVo';
nested exception is java.lang.IllegalStateException: Cannot convert value of type 'java.lang.String' to required type 'com.fsx.validator.CurrUserVo': no matching editors or conversion strategy found]
調試源碼可以發現它最終使用的參數解析器是:
RequestParamMethodArgumentResolver
,而并非我們自定義的
CurrUserArgumentResolver
。so可得出結論:我們自定義的參數解析器的優先級是低于Spring内置的。
那麼到底是什麼樣的優先級規則呢?我這裡不妨給指出如下,供以大家學習:
1、首先就得從
RequestMappingHandlerAdapter
說起,它對參數解析器的加載(初始化)順序:
RequestMappingHandlerAdapter:
@Override
public void afterPropertiesSet() {
// 顯然,也是允許你自己通過setArgumentResolvers()方法手動添加的~~~
// 加入你調用過set方法,這裡就不會執行啦~~~~~(一般不建議手動set)
if (this.argumentResolvers == null) {
List<HandlerMethodArgumentResolver> resolvers = getDefaultArgumentResolvers();
this.argumentResolvers = new HandlerMethodArgumentResolverComposite().addResolvers(resolvers);
}
...
}
private List<HandlerMethodArgumentResolver> getDefaultArgumentResolvers() {
List<HandlerMethodArgumentResolver> resolvers = new ArrayList<>();
// Annotation-based argument resolution
// 加載處理所有内置注解的解析器們
resolvers.add(new RequestParamMethodArgumentResolver(getBeanFactory(), false));
resolvers.add(new RequestParamMapMethodArgumentResolver());
resolvers.add(new PathVariableMethodArgumentResolver());
...
// Type-based argument resolution
// 比如request、response等等這些的解析器們
resolvers.add(new ServletRequestMethodArgumentResolver());
...
// Custom arguments
// 加載自定義的解析器們(我們自定義的在這裡會被加載進來)
if (getCustomArgumentResolvers() != null) {
resolvers.addAll(getCustomArgumentResolvers());
}
// Catch-all
// 加載這兩個用于兜底
resolvers.add(new RequestParamMethodArgumentResolver(getBeanFactory(), true));
resolvers.add(new ServletModelAttributeMethodProcessor(true));
return resolvers;
}
2、
RequestMappingHandlerAdapter
這個
Bean
配置處如下:
WebMvcConfigurationSupport:
@Bean
public RequestMappingHandlerAdapter requestMappingHandlerAdapter() {
RequestMappingHandlerAdapter adapter = createRequestMappingHandlerAdapter();
// 内容協商管理器
adapter.setContentNegotiationManager(mvcContentNegotiationManager());
// 消息轉換器們
adapter.setMessageConverters(getMessageConverters());
// ConfigurableWebBindingInitializer:配置資料綁定、校驗的相關配置項
adapter.setWebBindingInitializer(getConfigurableWebBindingInitializer());
// 參數解析器、傳回值解析器
adapter.setCustomArgumentResolvers(getArgumentResolvers());
adapter.setCustomReturnValueHandlers(getReturnValueHandlers());
...
}
WebMvcConfigurationSupport
應該沒有不熟悉它的了,它用于開啟
WebMVC
的配置支援~
從這個源碼(配置順序)中可以很清晰的得出答案:為何本例加了
@RequestParam
注解就通路就報錯了;同樣也解釋了為何入參不能是
Map
(但Object類型是可以的~)。
在介紹場景二之前,我先介紹一個類:
PropertyNamingStrategy
PropertyNamingStrategy
它表示序列化/反序列化過程中:Java屬性到序列化key的一種命名政策。
預設情況下從字元串反序列為一個
Java
對象,要求需要完全一樣才能反序列指派成功。但了解了這些政策之後,可以幫你帶來更好的相容性,下面以最為常用的兩個JSON庫為例分别講解~
庫對應的類叫Gson
,功能類似。因為我個人使用較少,是以此處忽略它~FieldNamingStrategy
fastjson中
fastjson在
1.2.15
版本(2016年6月)中提供了這個功能,它以枚舉的形式管理:
public enum PropertyNamingStrategy {
CamelCase, // 駱駝:
PascalCase, // 帕斯卡:
SnakeCase, // 蛇形:
KebabCase; // 烤肉串:
// 提供唯一一個執行個體方法:轉換translate
public String translate(String propertyName) {
switch (this) {
case SnakeCase: { ... }
case KebabCase: { ... }
case PascalCase: { ... }
case CamelCase: { ... }
}
}
}
針對此4種政策,給出使用用例如下:
public static void main(String[] args) {
String propertyName = "nameAndAge";
System.out.println(PropertyNamingStrategy.CamelCase.translate(propertyName)); // nameAndAge
System.out.println(PropertyNamingStrategy.PascalCase.translate(propertyName)); // NameAndAge
// 下面兩種的使用很多的情況:下劃線
System.out.println(PropertyNamingStrategy.SnakeCase.translate(propertyName)); // name_and_age
System.out.println(PropertyNamingStrategy.KebabCase.translate(propertyName)); // name-and-age
}
繼續示範使用
Fastjson
序列化/反序列化的時候的示例:
public static void main(String[] args) {
DemoVo vo = new DemoVo();
vo.setDemoName("fsx");
vo.setDemoAge(18);
vo.setDemoNameAndAge("fsx18");
PropertyNamingStrategy strategy = PropertyNamingStrategy.SnakeCase;
// 序列化配置對象
SerializeConfig config = new SerializeConfig();
config.propertyNamingStrategy = strategy;
// 反序列化配置對象
ParserConfig parserConfig = new ParserConfig();
parserConfig.propertyNamingStrategy = strategy;
// 序列化對象
String json = JSON.toJSONString(vo, config);
System.out.println("序列化vo對象到json -> " + json);
// 反序列化對象
vo = JSON.parseObject(json, DemoVo.class, parserConfig);
System.out.println("反序列化json到vo -> " + vo);
}
運作列印:
序列化vo對象到json -> {"demo_age":18,"demo_name":"fsx","demo_name_and_age":"fsx18"}
反序列化json到vo -> Main.DemoVo(demoName=fsx, demoAge=18, demoNameAndAge=fsx18)
若政策是
SnakeCase
,它是支援下劃線
_
到駝峰格式的
Java
屬性的互相轉換的。若使用另外三種,我把結果摘錄如下:
CamelCase:
序列化vo對象到json -> {"demoAge":18,"demoName":"fsx","demoNameAndAge":"fsx18"}
反序列化json到vo -> Main.DemoVo(demoName=fsx, demoAge=18, demoNameAndAge=fsx18)
PascalCase:
序列化vo對象到json -> {"DemoAge":18,"DemoName":"fsx","DemoNameAndAge":"fsx18"}
反序列化json到vo -> Main.DemoVo(demoName=fsx, demoAge=18, demoNameAndAge=fsx18)
KebabCase:
序列化vo對象到json -> {"demo-age":18,"demo-name":"fsx","demo-name-and-age":"fsx18"}
反序列化json到vo -> Main.DemoVo(demoName=fsx, demoAge=18, demoNameAndAge=fsx18)
FastJson
預設使用
CamelCase
題外話:除了上面那樣分别在序列化時臨時制定序列化、反序列化政策外,還可以用如下方式指定:
全局指定政策
SerializeConfig.getGlobalInstance().propertyNamingStrategy = PropertyNamingStrategy.PascalCase;
@JSONType指定
@JSONType(naming = PropertyNamingStrategy.SnakeCase)
private static class DemoVo {
@JSONField(name = "name")
private String demoName;
private Integer demoAge;
private Object demoNameAndAge;
}
若沒有指定name屬性,那就會使用@JSONField
政策~PropertyNamingStrategy
jackson中
除了
fastjson
,作為全球範圍内更為流行的
jackson
自然也是支援此些政策的。
// was abstract until 2.7 在2.7版本之前一直是抽象類
public class PropertyNamingStrategy implements java.io.Serializable {
public static final PropertyNamingStrategy SNAKE_CASE = new SnakeCaseStrategy();
public static final PropertyNamingStrategy UPPER_CAMEL_CASE = new UpperCamelCaseStrategy();
public static final PropertyNamingStrategy LOWER_CAMEL_CASE = new PropertyNamingStrategy();
public static final PropertyNamingStrategy KEBAB_CASE = new KebabCaseStrategy();
// 上面幾個政策都是@since 2.7,這個基于@since 2.4
public static final PropertyNamingStrategy LOWER_CASE = new LowerCaseStrategy();
// 提供的API方法如下:
public String nameForField(MapperConfig<?> config, AnnotatedField field, String defaultName);
public String nameForGetterMethod(MapperConfig<?> config, AnnotatedMethod method, String defaultName);
public String nameForSetterMethod(MapperConfig<?> config, AnnotatedMethod method, String defaultName);
public String nameForConstructorParameter(MapperConfig<?> config, AnnotatedParameter ctorParam, String defaultName);
// 所有政策都使用靜态内部類來實作(隻需要實作translate方法即可)
public static class SnakeCaseStrategy extends PropertyNamingStrategyBase
public static class UpperCamelCaseStrategy extends PropertyNamingStrategyBase
...
}
下面結合它的注解
@JsonNaming
來示範它的使用:
@Getter
@Setter
@ToString
// 此注解隻能标注在類上
@JsonNaming(value = PropertyNamingStrategy.SnakeCaseStrategy.class)
private static class DemoVo {
private String demoName;
private Integer demoAge;
@JsonProperty("diyProp")
private Object demoNameAndAge;
}
public static void main(String[] args) throws IOException {
DemoVo vo = new DemoVo();
vo.setDemoName("fsx");
vo.setDemoAge(18);
vo.setDemoNameAndAge("fsx18");
// 序列化對象
ObjectMapper objectMapper = new ObjectMapper();
String json = objectMapper.writeValueAsString(vo);
System.out.println("序列化vo對象到json -> " + json);
// 反序列化對象
vo = objectMapper.readValue(json,DemoVo.class);
System.out.println("反序列化json到vo -> " + vo);
}
列印輸出結果:
序列化vo對象到json -> {"demo_name":"fsx","demo_age":18,"diyProp":"fsx18"}
反序列化json到vo -> Main.DemoVo(demoName=fsx, demoAge=18, demoNameAndAge=fsx18)
顯然基于字段的注解它的優先級是高于@JsonProperty
@JsonNaming
除此之外,
jackson
還提供了更多實用注解,有興趣的可以自行去了解
我個人意見:
jackson
可能是由于功能設計得太過于全面了,使用起來有反倒很多不便之處,學習成本頗高。因為個人覺得還是我天朝的
Fastjson
好用啊~
說明:這些政策在異構的語言互動時是很有用的,因為各種語言命名規範都不盡相同,有了它們就可以有很好的相容性。
如:.net命名都是大寫開頭形如
DemoName
表示屬性名
如:js/python喜歡用下劃線形全小寫如
demo_name
場景二:
在微服務場景中有個特别常見的現象:跟第三方服務做對接時(如
python
老系統),你不乏會遇到如下兩個痛點:
- 對方系統是以下劃線形式命名的(和Java命名規範相悖)
- 對方系統的參數json串層次較深,而對你有用的僅僅是深處的一小部分
例如這個參數串:
{
"data": {
"transport_data": {
"demo_name": "fsx",
"demo_age": 18
},
"secret_info": {
"code": "fkldshjfkldshj"
}
},
"code": "200",
"msg": "this is a message"
}
對你真正有用的隻有
demo_name
和
demo_age
兩個值,怎麼破???
我相信絕大部分小夥伴都這麼做:按照此結構先定義一個
DTO
全部接收回來(字段命名也用下劃線方式命名),然後再一個個處理。若這麼做雖然簡單,我覺得還是有如下兩個不妥的地方:
- Java屬性名也必須用下劃線命名,看起來影響了命名體系(其實就是看着不爽,哈哈)
- 按照參數這種複雜結構書寫,使得我們關注點分散,不能聚焦到真真關心的那一塊資料上
針對這些痛點,廢話不多說,直接上我的處理方案:
1、定義一個模型(隻寫我自己關注的屬性)
@Getter
@Setter
@ToString
public class TranUserVo {
private String demoName;
private Long demoAge;
}
定義的模型非常之簡單,不僅隻關心我要的資料,而且還是标準的java駝峰命名,沒必要去遷就别的語言而喪失自己優雅性,否則容易把自己弄得四不像(萬一又接python,又接.net呢?)~
2、自定義一個參數解析器并且注冊上去
public class TranUserArgumentResolver implements HandlerMethodArgumentResolver {
// 隻處理這個類型,不需要注解
@Override
public boolean supportsParameter(MethodParameter parameter) {
Class<?> parameterType = parameter.getParameterType();
return TranUserVo.class.isAssignableFrom(parameterType);
}
@Override
public Object resolveArgument(MethodParameter parameter, ModelAndViewContainer container, NativeWebRequest webRequest, WebDataBinderFactory binderFactory) throws Exception {
HttpServletRequest request = webRequest.getNativeRequest(HttpServletRequest.class);
HttpMethod httpMethod = HttpMethod.valueOf(request.getMethod());
// 本例為了簡單,示範get的情況(這裡使用key為:demoKey)
if (httpMethod == HttpMethod.GET) {
String value = request.getParameter("demoKey");
JSONObject transportData = (JSONObject) ((JSONObject) JSON.parseObject(value).get("data")).get("transport_data");
// 采用命名政策,轉換TranUserVo執行個體對象再傳回
// 序列化配置對象
ParserConfig config = new ParserConfig();
config.propertyNamingStrategy = PropertyNamingStrategy.SnakeCase;
TranUserVo tranUserVo = transportData.toJavaObject(TranUserVo.class, config, 0);
return tranUserVo;
} else { // 從body提裡拿
// ...
return null;
}
}
}
// 注冊此自定義的參數解析器
@Override
public void addArgumentResolvers(List<HandlerMethodArgumentResolver> argumentResolvers) {
argumentResolvers.add(new TranUserArgumentResolver());
}
對此部分我說明一點:對于json到對象的解析,理應還加上 @Valid
測試用例:
@ResponseBody
@GetMapping("/test/tranuser")
public Object testCurrUser(TranUserVo tranUser) {
return tranUser;
}
/test/tranuser?demoKey=上面那一大長串json串
,得到的結果就是預期的結果喽:
完美~
說明:這種長傳現在需要使用post/put傳遞,本文隻是為了簡化示範,是以使用了 GET
總結
我認為,自定義參數解析器
HandlerMethodArgumentResolver
最重要不是它本身的實作,而是它的指導思想:分離關注,業務解耦。當然本文我摘出來的兩個使用場景案例隻是冰山一角,各位需要舉一反三,才能融會貫通。
既然我們可以自定義參數處理器
HandlerMethodArgumentResolver
,自然也就可以自定義傳回值處理器
HandlerMethodReturnValueHandler
喽,作為課後作業,有興趣者不妨一試,還是非常有作用的。特别在處理
"老項目"
的相容性上非常好使,或許能讓你大放異彩~