确定優化目标
跟CPU和I/O方面的性能優化一樣,優化前先考慮網絡性能優化的目标是什麼?
換句話說觀察到的網絡性能名額,要達到多少才合适呢?
實際上雖然網絡性能優化的整體目标,是降低網絡延遲(如RTT)和提高吞吐量(如BPS和PPS)
但具體到不同應用中,每個名額的優化标準可能會不同,優先級順序也大相徑庭
就拿上一節提到的NAT網關來說,由于其直接影響整個資料中心的網絡出入性能
是以NAT網關通常需要達到或接近線性轉發,也就是說PPS是最主要的性能目标
再如對于資料庫、緩存等系統,快速完成網絡收發,即低延遲,是主要的性能目标
而對于Web服務來說,則需要同時兼顧吞吐量和延遲
是以為了更客觀合理地評估優化效果
首先應該明确優化的标準,即要對系統和應用程式進行基準測試,得到網絡協定棧各層的基準性能
Linux網絡協定棧是需要掌握的核心原理,它是基于TCP/IP協定族的分層結構
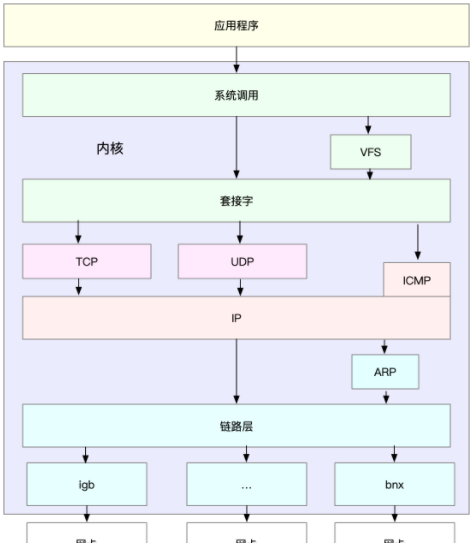
明白了這一點,在進行基準測試時就可以按照協定棧的每一層來測試
由于底層是其上方各層的基礎,底層性能也就決定了高層性能
是以要清楚,底層性能名額,其實就是對應高層的極限性能
首先是網絡接口層和網絡層,它們主要負責網絡包的封裝、尋址、路由以及發送和接收
每秒可處理的網絡包數PPS,就是它們最重要的性能名額(特别是在小包的情況下)
可以用核心自帶的發包工具pktgen ,來測試PPS的性能
再向上到傳輸層的TCP和UDP,它們主要負責網絡傳輸
對它們而言吞吐量(BPS)、連接配接數以及延遲,就是最重要的性能名額
可以用iperf或netperf ,來測試傳輸層的性能
不過要注意網絡包的大小,會直接影響這些名額的值
是以,通常需要測試一系列不同大小網絡包的性能
最後再往上到了應用層,最需要關注的是吞吐量(BPS)、每秒請求數以及延遲等名額
用wrk、ab等工具來測試應用程式的性能
這裡要注意的是,測試場景要盡量模拟生産環境,這樣的測試才更有價值
比如可以到生産環境中,錄制實際的請求情況,再到測試中回放
網絡性能工具
-
第一個次元從網絡性能名額出發更容易把性能工具同系統工作原理關聯起來,對性能問題有宏觀認識和把握
這樣當想檢視某個性能名額時,就能清楚知道,可以用哪些工具

43-套路篇:網絡性能優化的幾個思路(上)
-
第二個次元,從性能工具出發
這可以更快上手使用工具,迅速找出想要觀察的性能名額
特别是在工具有限的情況下,更要充分利用好手頭的每一個工具,用少量工具也要盡力挖掘出大量資訊
43-套路篇:網絡性能優化的幾個思路(上)
網絡性能優化
總的來說,先要獲得網絡基準測試報告,然後通過相關性能工具,定位出網絡性能瓶頸
再接下來的優化工作,就是水到渠成的事情了
當然還是那句話,要優化網絡性能,肯定離不開Linux系統的網絡協定棧和網絡收發流程的輔助
可以結合下面這張圖再回憶一下這部分的知識
應用程式優化
應用程式通常通過套接字接口進行網絡操作
由于網絡收發通常比較耗時,是以應用程式的優化,主要就是對網絡I/O和程序自身的工作模型的優化
從網絡I/O的角度來說,主要有下面兩種優化思路
-
第一種是最常用的I/O多路複用技術epoll,主要用來取代select和poll
這其實是解決C10K問題的關鍵,也是目前很多網絡應用預設使用的機制
-
第二種是使用異步I/O(Asynchronous I/O AIO)
AIO允許應用程式同時發起很多I/O操作,而不用等待這些操作完成
等到I/O完成後,系統會用事件通知的方式,告訴應用程式結果
不過,AIO的使用比較複雜,需要小心處理很多邊緣情況
從程序的工作模型來說,也有兩種不同的模型用來優化
-
第一種,主程序+多個worker子程序
其中主程序負責管理網絡連接配接,而子程序負責實際的業務處理
這也是最常用的一種模型
-
第二種,監聽到相同端口的多程序模型
在這種模型下,所有程序都會監聽相同接口
并且開啟SO_REUSEPORT選項,由核心負責,把請求負載均衡到這些監聽程序中去
除了網絡 I/O 和程序的工作模型外,應用層的網絡協定優化,也是至關重要的一點
常見的幾種優化方法
-
使用長連接配接取代短連接配接,可以顯著降低TCP建立連接配接的成本
在每秒請求次數較多時, 這樣做的效果非常明顯
- 使用記憶體等方式,來緩存不常變化的資料,可以降低網絡I/O次數,同時加快應用程式的響應速度
- 使用Protocol Buffer等序列化的方式,壓縮網絡I/O的資料量,可以提高應用程式的吞吐
- 使用DNS緩存、預取、HTTPDNS等方式,減少DNS解析的延遲,也可以提升網絡I/O的整體速度
套接字
套接字可以屏蔽掉Linux核心中不同協定的差異,為應用程式提供統一的通路接口
每個套接字,都有一個讀寫緩沖區
-
讀緩沖區,緩存了遠端發過來的資料
如果讀緩沖區已滿,就不能再接收新的資料
-
寫緩沖區,緩存了要發出去的資料
如果寫緩沖區已滿,應用程式的寫操作就會被阻 塞。
是以,為了提高網絡的吞吐量,你通常需要調整這些緩沖區的大小
- 增大每個套接字的緩沖區大小net.core.optmem_max
- 增大套接字接收緩沖區大小net.core.rmem_max和發送緩沖區大小net.core.wmem_max
- 增大TCP接收緩沖區大小net.ipv4.tcp_rmem和發送緩沖區大小net.ipv4.tcp_wmem
至于套接字的核心選項,參考下表
有幾點需要注意
-
tcp_rmem和tcp_wmem的三個數值分别是min,default,max
系統會根據這些設定自動調整TCP接收/發送緩沖區的大小
-
udp_mem的三個數值分别是min,pressure,max
系統會根據這些設定,自動調整UDP發送緩沖區的大小
當然,表格中的數值隻提供參考價值,具體應該設定多少,還需要根據實際的網絡狀況來确定
比如,發送緩沖區大小,理想數值是吞吐量 * 延遲,這樣才可以達到最大網絡使用率
除此之外,套接字接口還提供了一些配置選項,用來修改網絡連接配接的行為
- 為TCP連接配接設定TCP_NODELAY後,就可以禁用Nagle算法
- 為TCP連接配接開啟TCP_CORK後,可以讓小包聚合成大包後再發送(注意會阻塞小包的發送)
- 使用SO_SNDBUF和SO_RCVBUF ,可以分别調整套接字發送緩沖區和接收緩沖區的大小
小結
在優化網絡性能時,可以結合Linux系統的網絡協定棧和網絡收發流程
然後從應用程式、套接字、傳輸層、網絡層再到鍊路層等進行逐層優化
當然其實分析定位網絡瓶頸,也是基于這些進行的
定位出性能瓶頸後,就可以根據瓶頸所在的協定層進行優化
比如應用程式和套接字的優化思路
- 在應用程式中,主要優化I/O模型、工作模型以及應用層的網絡協定
- 在套接字層中,主要優化套接字的緩沖區大小
轉載請注明出處喲~
https://www.cnblogs.com/lichengguo