1. 什麼是 Fork/Join 架構
Fork/Join 架構是 Java7 提供了的一個用于并行執行任務的架構, 是一個把大任務分割成若幹個小任務,最終彙總每個小任務結果後得到大任務結果的架構 。
它的主要思想是:分而治之。
我們再通過 Fork 和 Join 這兩個單詞來了解下 Fork/Join 架構,Fork 就是把一個大任務切分為若幹子任務并行的執行,Join 就是合并這些子任務的執行結果,最後得到這個大任務的結果。
比如:計算 1+2+... +10000,可以分割成 10 個子任務,每個子任務分别對 1000 個數進行求和,最終彙總這 10 個子任務的結果。
Fork/Join 的運作流程圖如下:
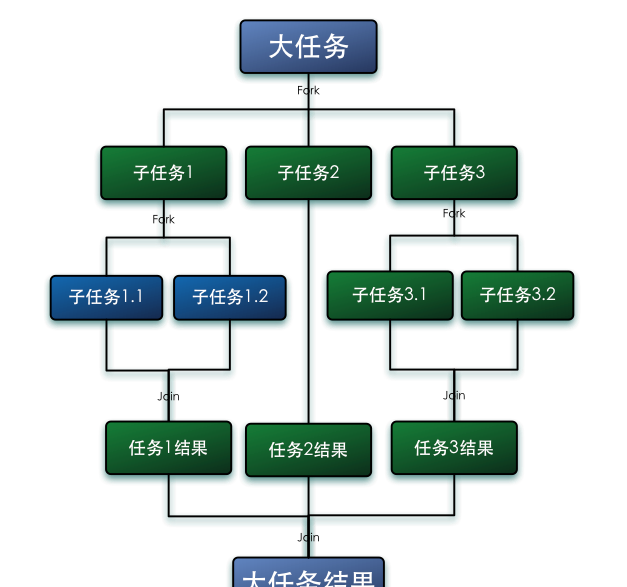
Fork/Join任務的原理:判斷一個任務是否足夠小,如果是,直接計算,否則,就分拆成幾個小任務分别計算。這個過程可以反複“裂變”成一系列小任務。
2. 工作竊取算法
工作竊取(work-stealing)算法是指某個線程從其他隊列裡竊取任務來執行。工作竊取的運作流程圖如下:

為什麼 ForkJoin 會存在工作竊取呢?因為我們将任務進行分解成多個子任務的時候。每個子任務的處理時間都不一樣。
例如分别有子任務 A \ B 。如果子任務 A 的 1ms 的時候已經執行,子任務 B 還在執行。那麼如果我們子任務 A 的線程等待子任務 B 完畢後在進行彙總,那麼子任務 A 線程就會在浪費執行時間,最終的執行時間就以最耗時的子任務為準。而如果我們的子任務A執行完畢後,處理子任務 B 的任務,并且執行完畢後将任務歸還給子任務 B。這樣就可以提高執行效率。而這種就是工作竊取。
工作竊取算法的優點是充分利用線程進行并行計算,并減少了線程間的競争,其缺點是在某些情況下還是存在競争,比如雙端隊列裡隻有一個任務時。并且消耗了更多的系統資源,比如建立多個線程和多個雙端隊列。
3. Fork/Join 架構的介紹
我們已經很清楚 Fork/Join 架構的需求了,那麼我們可以思考一下,如果讓我們來設計一個 Fork/Join 架構,該如何設計?這個思考有助于你了解 Fork/Join 架構的設計。
1)Fork/Join 架構的設計分為兩步:
- 第一步分割任務。首先我們需要有一個 fork 類來把大任務分割成子任務,有可能子任務還是很大,是以還需要不停的分割,直到分割出的子任務足夠小。
- 第二步執行任務并合并結果。分割的子任務分别放在雙端隊列裡,然後幾個啟動線程分别從雙端隊列裡擷取任務執行。子任務執行完的結果都統一放在一個隊列裡,啟動一個線程從隊列裡拿資料,然後合并這些資料。
2)Fork/Join 使用兩個類來完成以上兩件事情:
- ForkJoinTask:我們要使用 ForkJoin 架構,必須首先建立一個 ForkJoin 任務。它提供在任務中執行 fork() 和 join() 操作的機制,通常情況下我們不需要直接繼承 ForkJoinTask 類,而隻需要繼承它的子類,Fork/Join 架構提供了以下兩個子類:
- RecursiveAction:用于沒有傳回結果的任務。
- RecursiveTask :用于有傳回結果的任務。
- ForkJoinPool :ForkJoinTask 需要通過 ForkJoinPool 來執行,任務分割出的子任務會添加到目前工作線程所維護的雙端隊列中,進入隊列的頭部。當一個工作線程的隊列裡暫時沒有任務時,它會随機從其他工作線程的隊列的尾部擷取一個任務。
4. 使用 Fork/Join 架構
使用 Fork/Join 架構計算:1+2+3+……+100000000。
使用 Fork/Join 架構首先要考慮到的是如何分割任務,如果我們希望每個子任務最多執行 10000 個數的相加,那麼我們設定分割的門檻值是 10000,由于是 100000000 個數字相加,是以會不停的分割,第一次先分割成兩部分,即 1~50000000 和 50000001~100000000,第二次繼續将 1~50000000 分割成 1~25000000 和 25000001~50000000 ,将50000001~100000000 分割成 50000001~75000000 和 75000001~100000000 ……,一直分割,直到 開始和 結束的的差小于等于 10000 。
4-1. 建立 ForkJoin 任務
使用 ForkJoin 架構,必須首先建立一個 ForkJoin 任務。
public class ForkJoinDemo extends RecursiveTask<Long> {
private long start; // 開始值
private long end; // 結束值
private long temp = 10000L; // 門檻值
public ForkJoinDemo(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
// 條件成立:任務量沒有超過臨界值時計算;
if ((end - start) < temp) {
Long sum = 0L;
for (long i = start; i <= end; i++) {
sum += i;
}
return sum;
} else { // 條件不成立:拆分任務
long middle = (end + start) / 2; // 中間值
// 進行遞歸
ForkJoinDemo fork_1 = new ForkJoinDemo(start, middle);
// fork_1.fork(); // fork直接這樣使用會導緻有一個線程變成boss線程。執行時間會變長。
ForkJoinDemo fork_2 = new ForkJoinDemo(middle + 1, end);
// fork_2.fork(); // fork直接這樣使用會導緻有一個線程變成boss線程。執行時間會變長。
// 執行子任務,應該使用invokeAll(left,right);這樣代碼效率成倍提升
invokeAll(fork_1,fork_2);
// 傳回結果
return fork_1.join() + fork_2.join();
}
}
} 4-2. 使用 ForkJoinPool 執行任務
task 要通過 ForkJoinPool 來執行,分割的子任務也會添加到目前工作線程的雙端隊列中,進入隊列的頭部。
當一個工作線程中沒有任務時,會從其他工作線程的隊列尾部擷取一個任務(工作竊取)。
public class Test {
public static void main(String[] args) throws ExecutionException, InterruptedException {
long start = System.currentTimeMillis();
// 這是Fork/Join架構的線程池
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask<Long> submit = pool.submit(new ForkJoinDemo(0L, 1_0000_0000L));
// 送出任務
Long sum = submit.get();
long end = System.currentTimeMillis();
System.out.println("sum = " + sum + " ,耗時:" + (end - start) + " 毫秒");
}
} 執行結果:
sum = 5000000050000000 ,耗時:837 毫秒
三種送出任務到 ForkJoinPool 的方法:
- execute():異步執行,沒有任何傳回 。
- invoke(): 同步執行,調用之後需要等待任務完成,才能執行後面的代碼 。
- submit(): 異步執行,當調用get方法的時候會阻塞,完成時傳回一個future對象用于檢查狀态以及運作結果。
ForkJoinPool commonPool = ForkJoinPool.commonPool(); 為公共池提供一個引用,使用預定義的公共池減少了資源消耗,因為這阻礙了每個任務建立一個單獨的線程池。
5. Fork/Join 架構的異常處理
ForkJoinTask 在執行的時候可能會抛出異常,但是我們沒辦法在主線程裡直接捕獲異常,是以 ForkJoinTask 提供了 isCompletedAbnormally() 方法來檢查任務是否已經抛出異常或已經被取消了,并且可以通過 ForkJoinTask 的 getException 方法擷取異常 。使用如下代碼:
if(task.isCompletedAbnormally()){
System.out.println(task.getException());
} getException 方法傳回 Throwable 對象,如果任務被取消了則傳回 CancellationException。如果任務沒有完成或者沒有抛出異常則傳回 null。
6. 注意點
使用 ForkJoin 将相同的計算任務通過多線程的進行執行。進而能提高資料的計算速度。
在 google 的中的大資料處理架構 mapreduce 就通過類似 ForkJoin 的思想。通過多線程提高大資料的處理。但是我們需要注意:
- 使用這種多線程帶來的資料共享問題,在處理結果的合并的時候如果涉及到資料共享的問題,我們盡可能使用 JDK 為我們提供的并發容器。
- 在使用 JVM 的時候我們要考慮 OOM 的問題,如果我們的任務處理時間非常耗時,并且處理的資料非常大的時候。會造成 OOM。
- ForkJoin 也是通過多線程的方式進行處理任務。那麼我們不得不考慮是否應該使用 ForkJoin 。因為當資料量不是特别大的時候,我們沒有必要使用 ForkJoin 。因為多線程會涉及到上下文的切換。是以資料量不大的時候使用串行比使用多線程快。