第十二課:目标監測(Object detection)
3.1 目标定位(Object localization)
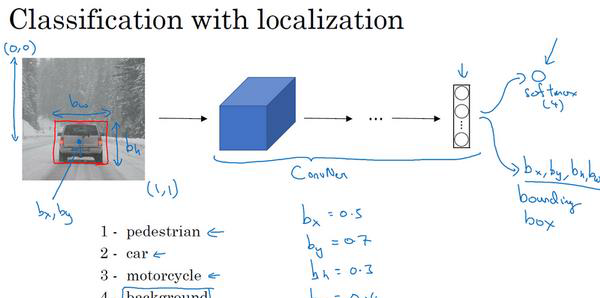

解釋上圖:
對于目标監測的輸出y,第一個參數$P_c$如果圖檔中有目标,比如行人,車或者自行車,則輸出1,如果是背景則輸出0.接下來的四個參數用來定位,具體定義在第一張圖檔中已經給出了。最後幾個參數$C_1,C_2,C_3$表示分别是行人,車,自行車,如果是自行車,則輸出$C_3$為1,其他為0.
其損失函數如上圖所示。
3.2 特征點檢測(Landmark detection)
特征點檢測通過在最後一層添加輸出變量,如圖所示,圖二标記了64個特征點,然後讓其在最後一層輸出,如上面的網絡最後一層,第一個參數表示是否識别到了人臉,後面的參數表示特征的具體坐标位置,根據這樣我們可以判斷出人的表情變化,或者判斷人的姿态,比如是行走還是在奔跑等等。
3.3 目标檢測(Object detection)
基于滑動視窗的目标檢測算法
讓方框在圖中從左上角按照一定步長進行周遊找到目标位置
缺點:計算量比較大,當步長太大,誤差比較大。
3.4 滑動視窗的卷積實作(Convolutional implementation of sliding windows)
解釋:滑動視窗的卷積實作就是從左上角開始,以固定步長進行周遊,這裡的步長是由最大池化的次元決定的,如圖步長為2,然後得到一個$2*2*400$的輸出全連接配接層,其中藍色框代表左上角的矩形視窗,綠色框代表右上角,以此類推。
如上圖,如果以$14*14$進行滑動視窗卷積,可以得到最終$8*8$的輸出層,這裡面的每一個方框對應相對位置的矩形框。
優點:效率高
缺點:不能準确預測矩形框的位置。
3.5 Bounding Box預測(Bounding box predictions)
Yolo算法效率比較高,因為它用了卷積,同時能夠精确輸出标準框,關于原理似懂非懂。
大概過程就是,先給訓練集打标簽(工作量巨大),如上圖,每個框輸出8個特征向量,具體含義本周第一課已經講過了,可以确定出目标的位置。
上面這個圖是關于四個參量的表示方法,其中$b_h,b_w$表示反了,注意下。。。表示方法也和前面目标定位那塊是一樣的。
Redmon, Joseph, et al. "You Only Look Once: Unified, Real-Time Object Detection." (2015):779-788.(原來大佬的yolo論文)
3.6 交并比(Intersection over union)
判斷對象檢測算法運作是否良好?
交并比用來表示打标簽的框與預測框的交集與并集之比,如果兩個框重合,則交并比為1.
交并比來衡量兩個邊界框重疊的相對大小
3.7 非極大值抑制(Non-max suppression)
非極大值抑制的方法作用:確定算法對每個對象隻檢測一次。
如上圖所示,對于預測的輸出,假設就是針對汽車,去掉了之前的$C_1,C_2,C_3$,将$P_c$表示為機率,先去掉機率小于0.6的,然後找到最大的機率作為輸出的預測,然後抛棄掉與最大機率框的交并比大于0.5的框,這就是非極大值抑制。
3.8 Anchor Boxes
Anchor Boxes:用來解決一個格子中有多個對象的問題。
對象在目标标簽中的編碼方式:(grid cell,anchor box),表示實際邊界框與anchor box的交并比越高,則就選擇較高的anchor box。
對于一個格子中有兩個圖像的問題:設定輸出有16個 向量,比如本題,前8個表示行人,後8個表示汽車。
通常一個格子中很少有三個對象。
3.9 YOLO算法(将前面學習的綜合起來)
在訓練階段,對于每個框得到固定的輸出,對于有汽車的框,注意輸出。
預測過程如下:
1.對于每個格子,都得到兩個輸出預測邊界框;
2.去掉機率很低的預測;
3.對于每個類别單獨運作非極大值抑制。
3.10 候選區域(選修)(Region proposals)
講了個R-CNN,了解
OVER!