背景
随着微服務技術的發展和普及,複雜的單體應用被逐漸地拆分成多個簡單的服務。随着各應用系統不斷地被拆解,服務的規模以及服務間調用關系的複雜度也不斷地擴大,在這種複雜的調用關系和龐大的服務規模下,問題的排查和優化的性能,不管是研發同學或者運維同學來說無疑是盲人摸象。
Google在2010年釋出的一篇名為《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,論文中提出了一個分布式鍊路追蹤的概念,它提到:每次請求都生成唯一的ID,跨執行個體請求的的時候将這個ID傳遞到對端,同時記錄每一個方法的開始時間和結束時間,最終這次請求通過追蹤ID進行串聯,形成一張有向無環圖,圖中的每個節點都代表個方法,圖中的關系代表方法的執行順序和關系。
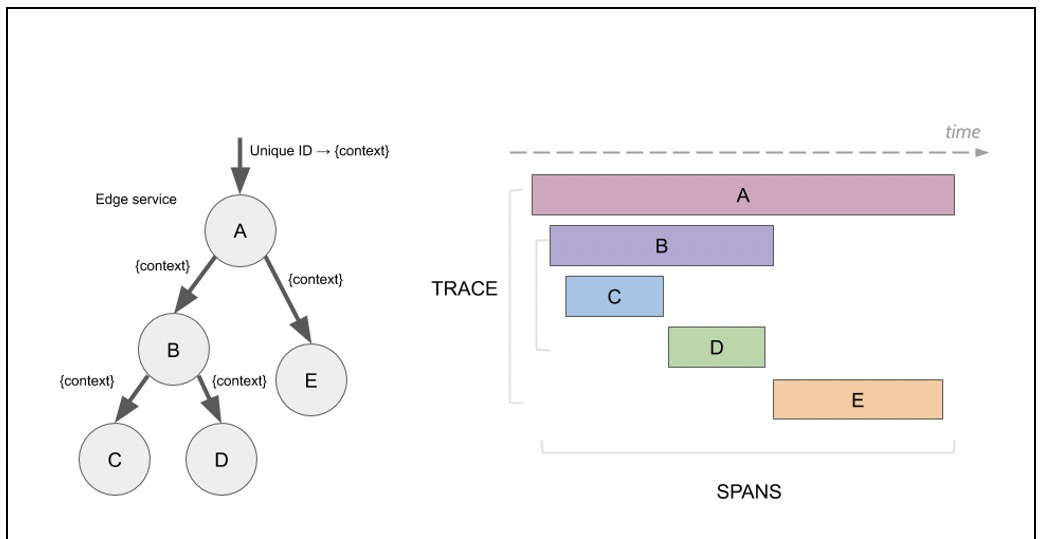
上面這圖,左邊是微服務下一次請求的執行過程,右邊是最終産生的Trace圖,開發同學或者運維同學通過這張圖可以直覺地看出一次請求所經過的所有應用,方法以及調用關系,快速定位業務故障和性能瓶頸。監控系統對于快速定位分析問題非常重要,大量的開源和商業解決方案不斷湧現,比如Jaeger,Open Telemetry, Apache SkyWalking,Zipkin等開源方案和LightStep,AppDynamics,New relics等APM廠商。
Jaeger簡介
Jaeger是Uber開發的分布式追蹤系統。 2017年4月份開源,9月進入CNCF孵化;2019年10月正式從CNCF畢業,成為了CNCF頂級項目。下圖是Jaeger的架構圖, 兩種結構大緻相同,差別在于collector和DB之間加Kafka做緩沖,用來解決峰值流量過載問題。Jaeger同時支援多種後端存儲,目前支援的資料存儲包括:記憶體,Badger,Cassandra,Elasticsearch,GRPC插件。

Jaeger的高可靠方案
Jaeger作為一個可觀察性/監控系統的組成部分,是開發和運維同學定位和發現業務系統問題的重要資料來源,而作為SRE,我們一定要保證監控系統比業務系統活的更久。一旦監控系統先于業務系統down掉,監控完全沒有價值。可以說監控是業務異常分析最後的一道屏障,它相比于其他系統來說,對于高可用和高性能更加敏感。
而Jaeger作為一個開源項目,它本身隻提供解決方案,并不會提供部署規模的評估方案和服務如何保證高可用的方案,這需要運維同學基于對服務高可用的經驗和對業務系統規模的調研的給出具體部署方案。這種情況下怎麼去提供高可用和高性能的後端服務?誰去為監控系統提供最後一層保障?
首先我們從部署架構分析Jaeger系統在高可用上需要着重優化的點(這裡我們以上圖右側社群最新的方案為例):
- Jaeger Client和Agent都是随應用直接部署到伺服器上,相對來說穩定性較強,隻需要保證Agent到後端網絡的品質即可。
- 新的部署模式為了解決流量突增的問題,增加了Kafka隊列作為緩沖,但我們注意不是說隻要有Kafka就能應對,我們還需要考慮Kafka本身能否有足夠的資源來動态擴容;同樣Collector的轉發能力、Flink的流計算能力和Ingester的導入能力也需要随着流量突增而動态擴容。
- 部署方案中Kafka和DB(ES、Cassandra等)是帶狀态的服務,需要用多副本的方式去部署,保證可靠性。
- 此外,為了保證查詢效率(尤其在報錯突增的情況下),在大資料量的時候還需要對ES、Cassandra進行調優,這裡涉及的工作會更多。
- Jaeger的後端系統涉及的元件比較多,還需要額外部署一套監控,用來監控Jaeger後端的穩定性和性能問題,配置好告警,及時去處理這些突發情況。
上述這些工作實施起來相比簡單部署一套Jaeger的工作量大非常多,而且後面還要持續投入人力在運維和管理這套系統中,是以最簡單的方式還是有服務化的産品來直接使用。
SLS作為Jaeger的後端
其實Jaeger的高可用最核心的部分是Jaeger後端(包括Collector、Kafka、Flink、DB、Query、UI),我們最好的方式是尋找一個能夠相容Jaeger的後端系統,提供高可靠、高性能的能力。
而SLS最近釋出的Trace服務恰巧可以完美解決這個問題。SLS最大的一個特點就是高性能、彈性和免運維,讓使用者輕松應對激增流量或者規模評估不準确的問題,SLS服務本身提供99.9%的可用性以及11個9的資料可靠性。
一般情況下,我們希望用兩種不同的方式來替換Jaeger的後端:
- 原生的資料用Jaeger SDK産生,查詢模式繼續使用Jaeger的UI,這樣對于應用開發同學來說繼續沿用之前的使用模式
- 原生的資料用Jaeger SDK産生,使用查詢使用SLS提供的Trace UI,相比Jaeger UI,SLS的Trace功能要強大的多,包括Trace名額計算、Dependency分析、自定義分析等,相關的功能介紹可以參考: SLS Trace1.0介紹 、 SLS Trace1.1介紹
接入方式
SLS的Trace服務為各個開源的鍊路追蹤提供易于各個開源軟體接入的後端服務,統一的資料模型和性能分析能力。SLS可以完全相容Jaeger的部署模式,目前提供了兩種接入方式,分别應對上述的兩類需求:
- 原生Jaeger接入方式,隻是把SLS當做Jaeger的後端存儲,使用上還可以用原來的Jaeger UI(當然也可以登入到SLS使用SLS的Trace功能)
- 簡化版Jaeger接入方式,隻是使用Jaeger的資料接入,後續所有功能都使用SLS自身提供的Trace功能
原生Jaeger接入方式
原生Jaeger接入方式是采用了混合模式,Jeager UI作為前端,SLS作為存儲後端。已習慣Jaeger頁面操作的使用者,多了一種接入方式。
以下是原生Jeager接入步驟,更詳細的參數配置和容器部署方式請參考
github- 登陸 SLS控制台 ,并建立用于存儲Span的Project
- SLS執行個體清單 ,并建立一個Trace執行個體。注: Project選擇上一步建立的Project
- 進入 Jaeger下載下傳頁面 ,下載下傳并解壓Jaeger包
- 啟動Agent。下面執行的指令以MacOS為例。
./agent-darwin --collector.host-port=localhost:14267
- 啟動Jaeger Collector
export SPAN_STORAGE_TYPE=aliyun-log-otel && \
./collector-darwin \
--aliyun-log.project=<PROJECT> \
--aliyun-log.endpoint=<ENDPOINT> \
--aliyun-log.access-key-id=<ACCESS_KEY_ID> \
--aliyun-log.access-key-secret=<ACCESS_KEY_SECRET> \
--aliyun-log.span-logstore=<SPAN_LOGSTORE> \
--aliyun-log.init-resource-flag=false
- 啟動UI
./query-darwin \
--aliyun-log.span-dep-logstore=<SPAN_DEP_LOGSTORE> \
--aliyun-log.init-resource-flag=false \
--query.static-files=./jaeger-ui-build/build/
下面是各參數較長的描述
| 參數名 | 描述 |
| PROJECT | 指定用于存儲 Span 的 Project |
| ENDPOINT | 指定用于存儲 Span 的 Project 所在的 Endpoint。 其格式為 |
| ACCESS_KEY_ID | 指定使用者辨別 Access Key ID |
| ACCESS_KEY_SECRET | 指定使用者辨別 Access Key Secret |
| SPAN_LOGSTORE | 指定用于存儲 Span 的 Logstore,名稱為 |
| SPAN_DEP_LOGSTORE | 指定用于存儲Service調用關系的Logstore,名稱為 |
簡化版Jaeger接入方式
簡化版的資料提供了兩種接入方式:Jaeger直發模式和Jaeger轉發模式。直發模式部署簡單,需要每個Agent都有連接配接SLS的能力;轉發模式支援更進階的流控和和下面分别介紹這兩種方式。
直發模式
直發模式是通過在jaeger agent端配置上SLS位址,将Trace直接發送SLS後端,該方式最大的好處就是不用部署Jaeger Collector執行個體。以下是直發模式下啟動參數指令。
./jaeger-agent --reporter.grpc.host-port=${ENDPOINT} --reporter.grpc.tls.enabled=true --agent.tags=sls.otel.project=${PROJECT},sls.otel.instanceid=${INSTANCE},sls.otel.akid=${ACCESS_KEY_ID},sls.otel.aksecret=${ACCESS_SECRET}
以下是各個參數的較長的描述:
| 參數 | |
| 阿裡雲賬号AccessKey ID。 建議您使用隻具備日志服務Project寫入權限的RAM使用者的AccessKey(包括AccessKey ID和AccessKey Secret)。 | |
| ACCESS_SECRET | 阿裡雲賬号AccessKey Secret。 建議您使用隻具備日志服務Project寫入權限的RAM使用者的AccessKey。 |
| 日志服務Project名稱。 | |
| INSTANCE | Trace服務執行個體名稱。 |
接入位址,格式為 |
轉發模式
轉發模式通過OpenTelemetry Collector統一收集jaeger-agent傳入的Span資料,并将Trace資料統一發送到後端。下面是轉發模式的部署步驟:
- 下載下傳Collector
OpenTelemetry Collector下載下傳位址:
https://github.com/open-telemetry/opentelemetry-collector-contrib/releases/tag/v0.30.0- 新增配置檔案
新增config.yaml配置檔案,并根據實際情況修改配置内容,配置中的參數解釋參考直發模式中的參數解釋。
receivers:
jaeger:
protocols:
grpc:
endpoint: 0.0.0.0:6831
thrift_binary:
endpoint: 0.0.0.0:6832
thrift_compact:
endpoint: 0.0.0.0:6833
thrift_http:
endpoint: 0.0.0.0:6834
exporters:
logging/detail:
loglevel: debug
alibabacloud_logservice/sls-trace:
endpoint: "{ENDPOINT}"
project: "{PROJECT}"
logstore: "{LOGSTORE}"
access_key_id: "{ACCESS_KEY_ID}"
access_key_secret: "{ACCESS_KEY_SECRET}"
service:
pipelines:
traces:
receivers: [jaeger]
exporters: [alibabacloud_logservice/sls-trace]
# for debug
#exporters: [logging/detail,alibabacloud_logservice/sls-trace]
- 運作Collector
啟動指令如下:
./otelcontribcol_linux_amd64 --config="PATH/TO/config.yaml"
SLS Trace功能速覽
Trace依賴分析可以自動計算并生成Trace的依賴拓撲,相比Jaeger增加了非常多的名額計算,包括QPS、錯誤率、平均延遲、PXX延遲等。
Trace清單顯示所上傳的Span的概覽資訊,同時搜尋框支援基于Span的Attribute、Tag、延遲時間等條件進行組合搜尋。
Trace詳情頁面展示了各個方法執行的耗時,調用關系以及span的資訊。
兩種接入方式對比
上述兩種方式都可以完成Jaeger Trace資料的接入和使用,下面我們總結一下兩種方式的一些異同點。
| 原生Jeager接入方式 | ||
| 可靠性 | 較強,需要保證Query UI服務的穩定性 | 強 |
| 資料處理能力 | ||
| 部署複雜度 | 較低,需要額外部署一套Query UI的服務 | 低,除了接入之外,無需部署任何元件 |
| 定位和發現故障能力 | 一般(也可以使用SLS提供的Trace UI)
|
|
| 使用習慣 | 保留了jaeger的頁面,無需調整使用者習慣 | 需要調整使用者習慣 |
整體而言,簡化版本的jaeger接入更勝一籌,因為作為一個監控系統,監控系統是需要讓使用者快速地定位和發現故障,是以定位和發現故障的能力需要首先考慮,通過檢視service和Span級别的Metric,可以快速的過濾一些出現異常的service和Span,再通過基于Span的屬性的多條件查詢能力,快速的定位和發現異常的Trace,進而快速的分析和定位問題所在。
總結
Jaeger作為OpenTracing協定的代表實作,在CNCF也是頂級的Project,還是非常受歡迎的Project。但如果你的公司正在建立設一套Trace系統,那不建議使用Jaeger的方案,因為最近OpenTracing已經和OpenCensus合并成了OpenTelemetry,後續Trace的統一标準是OpenTelemetry方案。是以還是建議大家直接去使用原生的OpenTelemetry的Trace。相關的介紹可以參考:《
OpenTelemetry統一方案》、《
OpenTelemetry Trace方案》。