20 世紀50 年代中期到80 年代初期的感覺器,20世紀80 年代初期至21世紀初期的專家系統,以及最近十年的深度學習技術,分别是三次熱潮的代表性産物
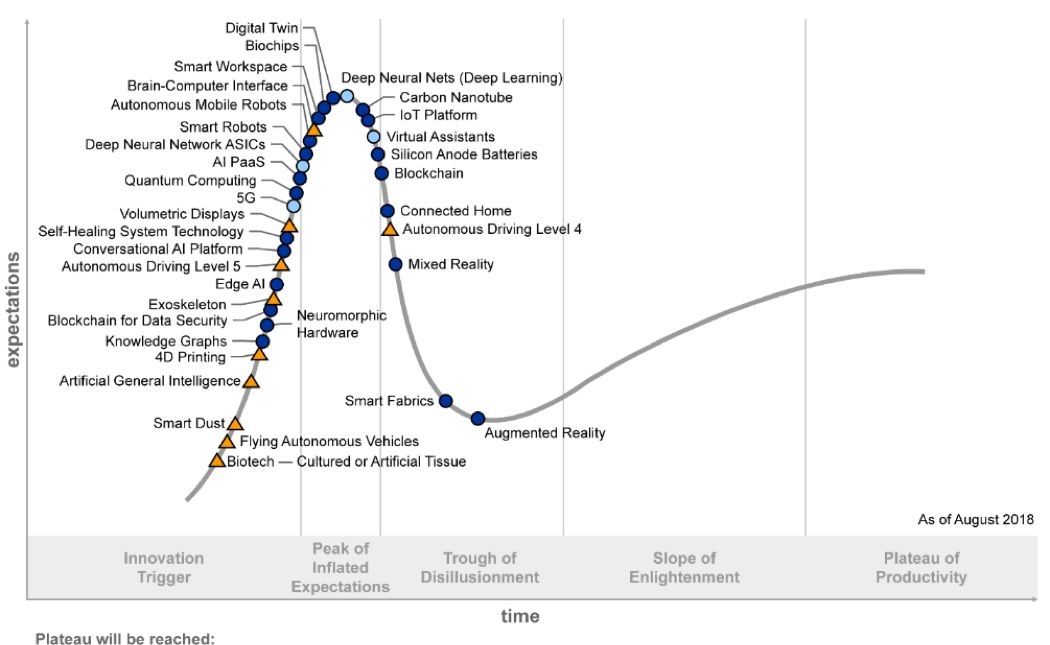
Gartner2018技術成熟度曲線,Gartner每年釋出的技術趨勢曲線,聚焦未來5到10年間,可能産生巨大競争力的新興技術
人工智能技術遠未達到媒體所宣傳的神通廣大,無所不能。從圖1中的技術發展現狀也可一窺端倪。AlphaGo可以戰勝最好的人類棋手,但卻不可能為你端一杯水。著名機器人學者Hans Moravec早前說過:機器人覺得容易的,對于人類來講将是非常難的;反之亦然。
人可以輕松做到聽說讀寫,但對于複雜計算很吃力;而機器人很難輕松做到用手抓取物體、以及走上坡路,但可以輕而易舉地算出空間火箭的運作軌道。人類可以通過日積月累的學習,輕松完成各種動作,但對于機器人來講完成這些簡單的動作難如登天。專家們稱此理論為“莫拉維克悖論”(Moravec's Paradox)。機器學習專家、著名的計算機科學和統計學家 Michael I. Jordan近日在《哈佛資料科學評論》上發表文章,也認為現在被稱為AI的許多領域,實際上是機器學習,而真正的 AI 革命尚未到來。
業界一緻認為,AI的三要素是算法,算力和資料
從計算,到感覺,再到認知,是大多數人都認同的人工智能技術發展路徑。那麼認知智能的發展現狀如何?
首先,讓我們看一下什麼是認知智能。複旦大學肖仰華教授曾經提到,所謂讓機器具備認知智能是指讓機器能夠像人一樣思考,而這種思考能力具體展現在機器能夠了解資料、了解語言進而了解現實世界的能力,展現在機器能夠解釋資料、解釋過程進而解釋現象的能力,展現在推理、規劃等等一系列人類所獨有的認知能力上
對于看、聽、說、動作而言,感覺智能已經可以達到非常好的效果。而對于推理、情感、聯想等能力,還需要更強的認知能力的展現

虛拟生命基本能力範疇
虛拟生命發展階段
虛拟生命1.0,可以看做是聊天機器人的更新版本。本階段最重要的特點是單點技術的整合,并能作為整體和人類進行互動。從功能上來看,仍然是被動互動為主,但可以結合對使用者的認知,進行使用者畫像和主動推薦。
我們目前正在處于虛拟生命的1.0階段。在這個階段,多輪對話、開放域對話、上下文了解、個性化問答、一緻性和安全回複等仍然是亟待解決的技術難題。同時,虛拟生命也需要找到可落地的場景,做好特定領域的技術突破。
虛拟生命2.0,是目前正在努力前行的方向,在這個階段,多模态技術整合已完全成熟,虛拟生命形态更為多樣性,具備基于海量資料的聯合推理及聯想,對自我和使用者都有了全面的認知,并可快速進行人格定制。實作這個階段可能需要3-5年。
虛拟生命3.0, 初步達到強人工智能,具備超越人類的綜合感覺能力,并擁有全面的推理、聯想和認知,具備自我意識,并能達到人類水準的自然互動。随着技術的進步,我們期待在未來十年至三十年實作虛拟生命的3.0。
語言是主要以發聲為基礎來傳遞資訊的符号系統,是人類重要的交際工具和存在方式之一。作用于人與人的關系時,是表達互相反應的中介;作用于人和客觀世界的關系時,是認識事物的工具;作用于文化時,是文化資訊的載體(來源:維基百科)。語言與邏輯相關,而人類的思維邏輯最為完善
自底向上,自然語言處理需要通過對字、詞、短語、句子、段落、篇章的分析,使得計算機能夠了解文本的意義
比如和機器人對話的過程中,對于音樂話題的了解,就需要用到命名實體識别、實體連結等技術。舉一個簡單的例子,“我真的非常喜歡傑倫的雙截棍”,就需要判斷傑倫是一個人名,連結到知識庫中“周傑倫”這樣一個歌手實體,并且“雙截棍”是一個歌名而不是一種器械。同時,還可以進行情感判斷,是一個正面的“喜歡”的情感。
傳統的自然語言處理技術,還是以統計學和機器學習為主,同時需要用到大量的規則。近十年來,深度學習技術的興起,也帶來了自然語言處理技術的突破。這一切還需要從語言的表示開始說起。
衆所周知,計算機擅長處理符号,是以,自然語言需要被轉化為一個機器友好的形式,使得計算機能夠快速處理。一個很典型的表示方法是詞彙的獨熱(one-hot)表示,也就是相當于每個詞在詞彙表裡都有一個特定的位置。比如說有一個10000個詞的詞彙表,而“國王”是詞彙表裡的第500個詞,那麼“國王”就可以表示為一個一維向量,隻有第500個位置是1,其他9999個位置都是0。但這種表示方法的問題很多,對語義相近但組成不同的詞或句子如“國王”和“女王”,利用獨熱表示的向量内積,無法準确的判斷兩者之間的相似度。
2013年,Tomas Mikolov等人在谷歌開發了一個基于神經網絡的詞嵌入(word embedding)學習方法Word2Vec,不但大大縮短了詞彙的表示向量的長度,而且能夠更好的展現語義資訊。通過這種嵌入方法可以很好的解決“國王”-“男人”=“女王”-“女人”這類問題。感興趣的讀者可以參考網際網路上大量的關于詞嵌入的資料。
計算機能夠快速處理自然語言之後,傳統的機器學習方法也進一步被深度學習所颠覆。相關算法在近年來的疊代速度非常快。以語言模型(Language Model)預訓練方法為例,代表性方法有Transformer,ELMo,Open AI GPT,BERT,GPT2以及最新的XLNet。其中,Transformer于2017年6月被提出。ELMo的發表時間是2018年2月,重新整理了當時所有的SOTA(State Of The Art)結果。
不到4個月,Open AI在6月,基于Transformer釋出了GPT方法,重新整理了9個SOTA結果。又過了4個月,橫空出世的BERT又重新整理了11個SOTA結果。2019年2月,Open AI釋出的GPT2,包含15億參數,重新整理了11項任務的SOTA結果。而2019年6月,CMU 與谷歌大腦提出了全新 XLNet,在 20 個任務上超過了 BERT 的表現,并在 18 個任務上取得了目前最佳效果。
除了算法和算力的進步,還有一個重要的原因在于,以前的自然語言處理研究,更多的是監督學習,需要大量的标注資料,成本高且品質難以控制,而以BERT為代表的深度學習方法,直接在無标注的文本上做出預訓練模型。在人類曆史上,無監督資料是海量的,也就代表着這些模型的提升空間還有很大。2019年7月11日,Google AI發表論文,就利用了驚人的250億平行句對的訓練樣本。其應用效果我們也拭目以待。
嘗試用技術模拟人類的真實對話,在開放領域就是個僞命題。因為在人類的對話過程中,一句話中所表達出的資訊,不隻是文字本身,還包括世界觀、情緒、環境、上下文、語音、表情、對話者之間的關系等。
比如說“今天天氣不錯”,在早晨擁擠的電梯中和同僚說,在秋遊的過程中和驢友說,走在大街上的男女朋友之間說,在傾盆大雨中對同伴說,很可能代表完全不同的意思。在人類對話中需要考慮到的因素包括:說話者和聽者的靜态世界觀、動态情緒、兩者的關系,以及上下文和所處環境等
而且,以上這些都不是獨立因素,整合起來,才能真正反映一句話或者一個詞所蘊含的意思。這就是人類語言的奇妙之處。同時,人類在互動過程中,并不是等對方說完一句話才進行資訊處理,而是随着說出的每一個字,不斷的進行腦補,在對方說完之前就很可能了解到其所有的資訊。再進一步,人類有很強的糾錯功能,在進行多輪互動的時候,能夠根據對方的回報,修正自己的了解,達到雙方的資訊同步。
在上一節中,我們也提到,自然語言處理技術很難解決推理問題。而推理是認知智能的重要組成部分。比如說對于問題“姚明的老婆的女兒的國籍是什麼?”,一個可行的解決方案,就是通過大規模百科知識圖譜來進行推理查詢。
知識圖譜被認為是從感覺智能通往認知智能的重要基石。一個很簡單的原因就是,沒有知識的機器人不可能實作認知智能。圖靈獎獲得者,知識工程創始人Edward Feigenbaum曾經提到:“Knowledge is the power in AI system”。張钹院士也提到,“沒有知識的AI不是真正的AI”。
拿上一節提到的GPT-2算法來看,即使其文章續寫能力讓人贊歎,也隻是再次證明了足夠大的神經網絡配合足夠多的訓練資料,就能夠産生強大的記憶能力。但邏輯和推理能力,仍然是無法從記憶能力中自然而然的出現的。學界和企業界都寄希望于知識圖譜解決知識互連和推理的問題。那麼什麼是知識圖譜?簡單來說,就是把知識用圖的形式組織起來。可能這樣說還不夠明白,我們舉例子分别說下什麼是知識,什麼是圖譜。
所謂知識,是資訊的抽象,舉一個簡單的例子來說,226.1厘米,229厘米,都是客觀存在的孤立的資料。此時,資料不具有任何的意義,僅表達一個事實存在。而“姚明臂展226.1厘米”, “姚明身高229厘米”,是事實型的陳述,屬于資訊的範疇。對于知識而言,是在更高層面上的一種抽象和歸納,把姚明的身高、臂展,及姚明的其他屬性整合起來,就得到了對于姚明的一個認知,也可以進一步了解姚明的身高是比普通人更高的。
維基百科給出的關于知識的定義是:知識是人類在實踐中認識客觀世界(包括人類自身)的成果,它包括事實、資訊的描述或在教育和實踐中獲得的技能。知識是人類從各個途徑中獲得得經過提升總結與凝練的系統的認識。
圖譜的英文是graph,直譯過來就是“圖”的意思。在圖論(數學的一個研究分支)中,圖(graph)表示一些事物(objects)與另一些事物之間互相連接配接的結構。一張圖通常由一些結點(vertices或nodes)和連接配接這些結點的邊(edge)組成。Sylvester在1878年首次提出了“圖”這一名詞[7]。如果我們把姚明相關的“知識”用“圖譜”建構起來
知識圖譜是實作通用人工智能(Artificial General Intelligence)的重要基石。從感覺到認知的跨越過程中,建構大規模高品質知識圖譜是一個重要環節,當人工智能可以通過更結構化的表示了解人類知識,并進行互聯,才有可能讓機器真正實作推理、聯想等認知功能。而建構知識圖譜是一個系統工程
自頂向下的政策為專家驅動,根據應用場景和領域,利用經驗知識人工為知識圖譜定義資料模式,在定義本體的過程中,首先從最頂層的概念開始,然後逐漸進行細化,形成結構良好的分類學層次結構;在定義好資料模式後,再将實體逐個對應到概念中。
自底向上的政策為資料驅動,從資料源開始,針對不同類型的資料,對其包含的實體和知識進行歸納組織,形成底層的概念,然後逐漸往上抽象,形成上層的概念,并對應到具體的應用場景中。
知識圖譜可以輔助各種智能場景下的應用。谷歌在2012年最早提出“Knowledge Graph”的概念,并将知識圖譜用到搜尋中,使得“搜尋能直接通往答案”。知識圖譜還能輔助智能問答、決策推理等應用場景。
最後,建構知識圖譜的成本仍然較高。Heiko Paulheim在其文章《How much is a Triple? Estimating the Cost of Knowledge Graph Creation》中,給出了幾個典型的知識圖譜的建構成本。其中,上世紀80年代開始的也是最早的知識圖譜項目CYC,平均建構一條陳述句和斷言的成本是5.71美元,而随着自然語言處理和機器學習技術的進步,DBpedia建構每一條的成本降低到了1.85美分。即便如此,在真正工程化落地的時候,牽扯到多源資料的清洗整合,一個知識圖譜項目的成本還是居高不下。
自然語言處理與知識圖譜結合可以實作一定程度的推理,而知識圖譜和深度學習結合可以實作一定程度的可解釋性,自然語言處理和深度學習結合,誕生了BERT等強大的語言模型