一、背景
Flink 1.13 已于近期正式釋出,超過 200 名貢獻者參與了 Flink 1.13 的開發,送出了超過 1000 個 commits,完成了若幹重要功能。其中,PyFlink 子產品在該版本中也新增了若幹重要功能,比如支援了 state、自定義 window、row-based operation 等。随着這些功能的引入,PyFlink 功能已經日趨完善,使用者可以使用 Python 語言完成絕大多數類型Flink作業的開發。接下來,我們詳細介紹如何在 Python DataStream API 中使用 state & timer 功能。
二、state 功能介紹
作為流計算引擎,state 是 Flink 中最核心的功能之一。
- 在 1.12 中,Python DataStream API 尚不支援 state,使用者使用 Python DataStream API 隻能實作一些簡單的、不需要使用 state 的應用;
- 而在 1.13 中,Python DataStream API 支援了此項重要功能。
state 使用示例
如下是一個簡單的示例,說明如何在 Python DataStream API 作業中使用 state:
from pyflink.common import WatermarkStrategy, Row
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors import NumberSequenceSource
from pyflink.datastream.functions import RuntimeContext, MapFunction
from pyflink.datastream.state import ValueStateDescriptor
class MyMapFunction(MapFunction):
def open(self, runtime_context: RuntimeContext):
state_desc = ValueStateDescriptor('cnt', Types.LONG())
# 定義value state
self.cnt_state = runtime_context.get_state(state_desc)
def map(self, value):
cnt = self.cnt_state.value()
if cnt is None:
cnt = 0
new_cnt = cnt + 1
self.cnt_state.update(new_cnt)
return value[0], new_cnt
def state_access_demo():
# 1. 建立 StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# 2. 建立資料源
seq_num_source = NumberSequenceSource(1, 100)
ds = env.from_source(
source=seq_num_source,
watermark_strategy=WatermarkStrategy.for_monotonous_timestamps(),
source_name='seq_num_source',
type_info=Types.LONG())
# 3. 定義執行邏輯
ds = ds.map(lambda a: Row(a % 4, 1), output_type=Types.ROW([Types.LONG(), Types.LONG()])) \
.key_by(lambda a: a[0]) \
.map(MyMapFunction(), output_type=Types.TUPLE([Types.LONG(), Types.LONG()]))
# 4. 将列印結果資料
ds.print()
# 5. 執行作業
env.execute()
if __name__ == '__main__':
state_access_demo() 在上面的例子中,我們定義了一個 MapFunction,該 MapFunction 中定義了一個名字為 “cnt_state” 的 ValueState,用于記錄每一個 key 出現的次數。
說明:
- 除了 ValueState 之外,Python DataStream API 還支援 ListState、MapState、ReducingState,以及 AggregatingState;
- 定義 state 的 StateDescriptor 時,需要聲明 state 中所存儲的資料的類型(TypeInformation)。另外需要注意的是,目前 TypeInformation 字段并未被使用,預設使用 pickle 進行序列化,是以建議将 TypeInformation 字段定義為 Types.PICKLED_BYTE_ARRAY() 類型,與實際所使用的序列化器相比對。這樣的話,當後續版本支援使用 TypeInformation 之後,可以保持後向相容性;
- state 除了可以在 KeyedStream 的 map 操作中使用,還可以在其它操作中使用;除此之外,還可以在連接配接流中使用 state,比如:
ds1 = ... # type DataStream
ds2 = ... # type DataStream
ds1.connect(ds2) \
.key_by(key_selector1=lambda a: a[0], key_selector2=lambda a: a[0]) \
.map(MyCoMapFunction()) # 可以在MyCoMapFunction中使用state 可以使用 state 的 API 清單如下:
| 操作 | 自定義函數 | |
|---|---|---|
| KeyedStream | map | MapFunction |
| flat_map | FlatMapFunction | |
| reduce | ReduceFunction | |
| filter | FilterFunction | |
| process | KeyedProcessFunction | |
| ConnectedStreams | CoMapFunction | |
| CoFlatMapFunction | ||
| KeyedCoProcessFunction | ||
| WindowedStream | apply | WindowFunction |
| ProcessWindowFunction |
state 工作原理
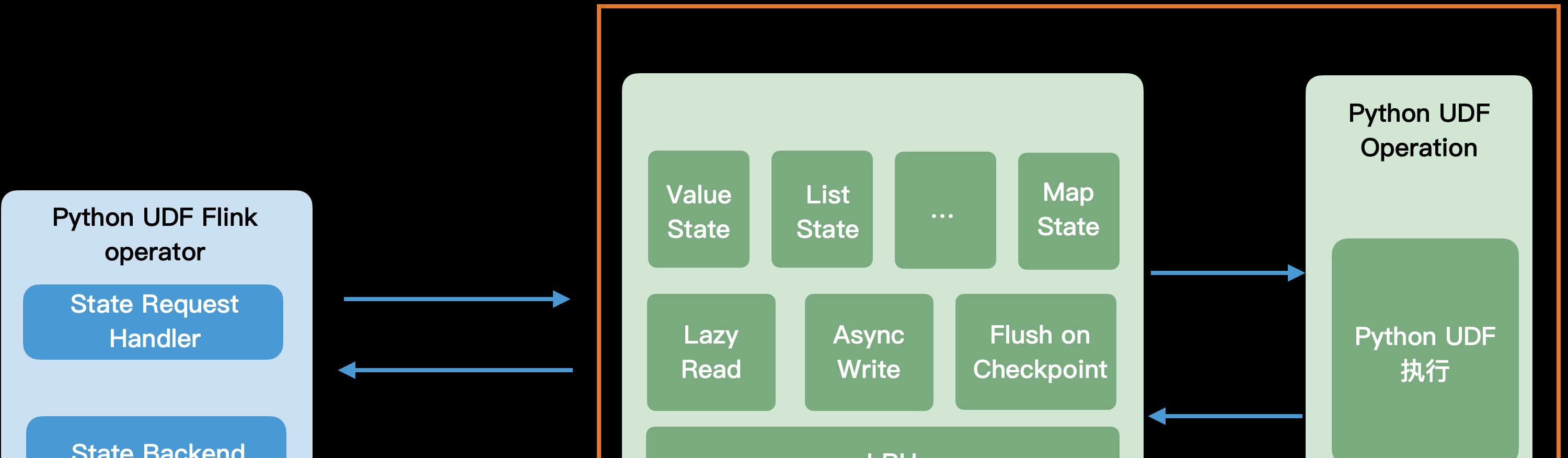
上圖是 PyFlink 中,state 工作原理的架構圖。從圖中我們可以看出,Python 自定義函數運作在 Python worker 程序中,而 state backend 運作在 JVM 程序中(由 Java 算子來管理)。當 Python 自定義函數需要通路 state 時,會通過遠端調用的方式,通路 state backend。
我們知道,遠端調用的開銷是非常大的,為了提升 state 讀寫的性能,PyFlink 針對 state 讀寫做了以下幾個方面的優化工作:
-
Lazy Read:
對于包含多個 entry 的 state,比如 MapState,當周遊 state 時,state 資料并不會一次性全部讀取到 Python worker 中,隻有當真正需要通路時,才從 state backend 讀取。
-
Async Write:
當更新 state 時,更新後的 state,會先存儲在 LRU cache 中,并不會同步地更新到遠端的 state backend,這樣做可以避免每次 state 更新操作都通路遠端的 state backend;同時,針對同一個 key 的多次更新操作,可以合并執行,盡量避免無效的 state 更新。
-
LRU cache:
在 Python worker 程序中維護了 state 讀寫的 cache。當讀取某個 key 時,會先檢視其是否已經被加載到讀 cache 中;當更新某個 key 時,會先将其存放到寫 cache 中。針對頻繁讀寫的 key,LRU cache 可以避免每次讀寫操作,都通路遠端的 state backend,對于有熱點 key 的場景,可以極大提升 state 讀寫性能。
-
Flush on Checkpoint:
為了保證 checkpoint 語義的正确性,當 Java 算子需要執行 checkpoint時,會将 Python worker中的寫 cache 都 flush 回 state backend。
其中 LRU cache 可以細分為二級,如下圖所示:

- 二級 cache 為 global cache,二級 cache 中的讀 cache 中存儲着目前 Python worker 程序中所有緩存的原始 state 資料(未反序列化);二級 cache 中的寫 cache 中存儲着目前 Python worker 程序中所有建立的 state 對象。
- 一級 cache 位于每一個 state 對象内,在 state 對象中緩存着該 state 對象已經從遠端的 state backend 讀取的 state 資料以及待更新回遠端的 state backend 的 state 資料。
工作流程:
- 當在 Python UDF 中,建立一個 state 對象時,首先會檢視目前 key 所對應的 state 對象是否已經存在(在二級 cache 中的 “Global Write Cache” 中查找),如果存在,則傳回對應的 state 對象;如果不存在,則建立新的 state 對象,并存入 “Global Write Cache”;
- state 讀取:當在 Python UDF 中,讀取 state 對象時,如果待讀取的 state 資料已經存在(一級 cache),比如對于 MapState,待讀取的 map key/map value 已經存在,則直接傳回對應的 map key/map value;否則,通路二級 cache,如果二級 cache 中也不存在待讀取的 state 資料,則從遠端的 state backend 讀取;
- state 寫入:當在 Python UDF 中,更新 state 對象時,先寫到 state 對象内部的寫 cache 中(一級 cache);當 state 對象中待寫回 state backend 的 state 資料的大小超過指定門檻值或者當遇到 checkpoint 時,将待寫回的 state 資料寫回遠端的 state backend。
state 性能調優
通過前一節的介紹,我們知道 PyFlink 使用了多種優化手段,用于提升 state 讀寫的性能,這些優化行為可以通過以下參數配置:
| 配置 | 說明 |
|---|---|
| python.state.cache-size | Python worker 中讀 cache 以及寫 cache 的大小。(二級 cache)需要注意的是:讀 cache、寫 cache是獨立的,目前不支援分别配置讀 cache 以及寫 cache 的大小。 |
| python.map-state.iterate-response-batch-size | 當周遊 MapState 時,每次從 state backend 讀取并傳回給 Python worker 的 entry 的最大個數。 |
| python.map-state.read-cache-size | 一個 MapState 的讀 cache 中最大允許的 entry 個數(一級 cache)。當一個 MapState 中,讀 cache 中的 entry 個數超過該門檻值時,會通過 LRU 政策從讀 cache 中删除最近最少通路過的 entry。 |
| python.map-state.write-cache-size | 一個 MapState 的寫 cache 中最大允許的待更新 entry 的個數(一級 cache)。當一個 MapState 中,寫 cache 中待更新的 entry 的個數超過該門檻值時,會将該 MapState 下所有待更新 state 資料寫回遠端的 state backend。 |
需要注意的是,state 讀寫的性能不僅取決于以上參數,還受其它因素的影響,比如:
-
輸入資料中 key 的分布:
輸入資料的 key 越分散,讀 cache 命中的機率越低,則性能越差。
-
Python UDF 中 state 讀寫次數:
state 讀寫可能涉及到讀寫遠端的 state backend,應該盡量優化 Python UDF 的實作,減少不必要的 state 讀寫。
-
checkpoint interval:
為了保證 checkpoint 語義的正确性,當遇到 checkpoint 時,Python worker 會将所有緩存的待更新 state 資料,寫回 state backend。如果配置的 checkpoint interval 過小,則可能并不能有效減少 Python worker 寫回 state backend 的資料量。
-
bundle size / bundle time:
目前 Python 算子會将輸入資料劃分成多個批次,發送給 Python worker 執行。當一個批次的資料處理完之後,會強制将 Python worker 程序中的待更新 state 寫回 state backend。與 checkpoint interval 類似,該行為也可能會影響 state 寫性能。批次的大小可以通過 python.fn-execution.bundle.size 和 python.fn-execution.bundle.time 參數控制。
三、timer 功能介紹
timer 使用示例
除了 state 之外,使用者還可以在 Python DataStream API 中使用定時器 timer。
import datetime
from pyflink.common import Row, WatermarkStrategy
from pyflink.common.typeinfo import Types
from pyflink.common.watermark_strategy import TimestampAssigner
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.functions import KeyedProcessFunction, RuntimeContext
from pyflink.datastream.state import ValueStateDescriptor
from pyflink.table import StreamTableEnvironment
class CountWithTimeoutFunction(KeyedProcessFunction):
def __init__(self):
self.state = None
def open(self, runtime_context: RuntimeContext):
self.state = runtime_context.get_state(ValueStateDescriptor(
"my_state", Types.ROW([Types.STRING(), Types.LONG(), Types.LONG()])))
def process_element(self, value, ctx: 'KeyedProcessFunction.Context'):
# retrieve the current count
current = self.state.value()
if current is None:
current = Row(value.f1, 0, 0)
# update the state's count
current[1] += 1
# set the state's timestamp to the record's assigned event time timestamp
current[2] = ctx.timestamp()
# write the state back
self.state.update(current)
# schedule the next timer 60 seconds from the current event time
ctx.timer_service().register_event_time_timer(current[2] + 60000)
def on_timer(self, timestamp: int, ctx: 'KeyedProcessFunction.OnTimerContext'):
# get the state for the key that scheduled the timer
result = self.state.value()
# check if this is an outdated timer or the latest timer
if timestamp == result[2] + 60000:
# emit the state on timeout
yield result[0], result[1]
class MyTimestampAssigner(TimestampAssigner):
def __init__(self):
self.epoch = datetime.datetime.utcfromtimestamp(0)
def extract_timestamp(self, value, record_timestamp) -> int:
return int((value[0] - self.epoch).total_seconds() * 1000)
if __name__ == '__main__':
env = StreamExecutionEnvironment.get_execution_environment()
t_env = StreamTableEnvironment.create(stream_execution_environment=env)
t_env.execute_sql("""
CREATE TABLE my_source (
a TIMESTAMP(3),
b VARCHAR,
c VARCHAR
) WITH (
'connector' = 'datagen',
'rows-per-second' = '10'
)
""")
stream = t_env.to_append_stream(
t_env.from_path('my_source'),
Types.ROW([Types.SQL_TIMESTAMP(), Types.STRING(), Types.STRING()]))
watermarked_stream = stream.assign_timestamps_and_watermarks(
WatermarkStrategy.for_monotonous_timestamps()
.with_timestamp_assigner(MyTimestampAssigner()))
# apply the process function onto a keyed stream
watermarked_stream.key_by(lambda value: value[1])\
.process(CountWithTimeoutFunction()) \
.print()
env.execute() 在上述示例中,我們定義了一個 KeyedProcessFunction,該 KeyedProcessFunction 記錄每一個 key 出現的次數,當一個 key 超過 60 秒沒有更新時,會将該 key 以及其出現次數,發送到下遊節點。
除了 event time timer 之外,使用者還可以使用 processing time timer。
timer 工作原理
timer 的工作流程是這樣的:
- 與 state 通路使用單獨的通信信道不同,當使用者注冊 timer 之後,注冊消息通過資料通道發送到 Java 算子;
- Java 算子收到 timer 注冊消息之後,首先檢查待注冊 timer 的觸發時間,如果已經超過目前時間,則直接觸發;否則的話,将 timer 注冊到 Java 算子的 timer service 中;
- 當 timer 觸發之後,觸發消息通過資料通道發送到 Python worker,Python worker 回調使用者 Python UDF 中的的 on_timer 方法。
需要注意的是:由于 timer 注冊消息以及觸發消息通過資料通道異步地在 Java 算子以及 Python worker 之間傳輸,這會造成在某些場景下,timer 的觸發可能沒有那麼及時。比如當使用者注冊了一個 processing time timer,當 timer 觸發之後,觸發消息通過資料通道傳輸到 Python UDF 時,可能已經是幾秒中之後了。
四、總結
在這篇文章中,我們主要介紹了如何在 Python DataStream API 作業中使用 state & timer,state & timer 的工作原理以及如何進行性能調優。接下來,我們會繼續推出 PyFlink 系列文章,幫助 PyFlink 使用者深入了解 PyFlink 中各種功能、應用場景以及最佳實踐等。
另外,阿裡雲實時計算生态團隊長期招聘優秀大資料人才(包括實習 + 社招),我們的工作包括:
- 實時機器學習:支援機器學習場景下實時特征工程和 AI 引擎配合,基于 Apache Flink 及其生态打造實時機器學習的标準,推動例如搜尋、推薦、廣告、風控等場景的全面實時化;
- 大資料 + AI 一體化:包括程式設計語言一體化 (PyFlink 相關工作),執行引擎內建化 (TF on Flink),工作流及管理一體化(Flink AI Flow)。
如果你對開源、大資料或者 AI 感興趣,請發履歷到:[email protected]
此外,也歡迎大家加入 “PyFlink交流群”,交流 PyFlink 相關的問題。
活動推薦
阿裡雲基于 Apache Flink 建構的企業級産品-實時計算Flink版現開啟6月限時活動:
0元試用
實時計算Flink版(包年包月、10CU)即可有機會獲得 Flink 獨家定制T恤;另包3個月及以上還有85折優惠!
了解活動詳情:
https://www.aliyun.com/product/bigdata/sc