前言:又到春招季!作為國民級出行服務平台,高德業務快速發展,大量校招/社招名額開放,歡迎大家投遞履歷,詳情見文末。為幫助大家更了解高德技術,我們策劃了#春招專欄#的系列文章,組織各業務團隊的高年級同學以業務科普+技術應用實踐為主要内容為大家做相關介紹。
本文是#春招專欄#系列的第 3 篇,根據 高德視覺技術中心基礎研發部 負責人郝志會在AT技術講壇分享的《視覺技術在POI名稱自動化生成的實踐》内容整理而成,在不影響原意的情況下略作删節。
AT技術講壇(Amap Technology Tribune)是高德發起的一檔技術交流活動,每期圍繞一個主題,我們會邀請阿裡集團内外的專家以演講、QA、開放讨論的方式,與大家做技術交流。
郝志會所在團隊涉及到計算機視覺方面很多技術:包括目标的檢測、識别、分割,幾何重建、視覺定位,等等。
高德POI資料的采集
高德有7000萬以上的POI(Point of Interest,興趣點)資料。每年還會出現很多新增的POI,也會有一部分POI停止營業、關門倒閉。這些POI如何制作和更新?從采集方式來看會有很多擷取POI的方式,有一種重要而且直覺的采集方式,高德通過衆包方式采集街邊店鋪的圖像,利用計算機視覺技術(以及人工輔助)從圖像中提取POI資料。
下圖示範了一次衆包化采集過程。高德的采集人員從這條街走過,拍攝連續圖像。最後把圖像和GPS坐标,上傳給高德。
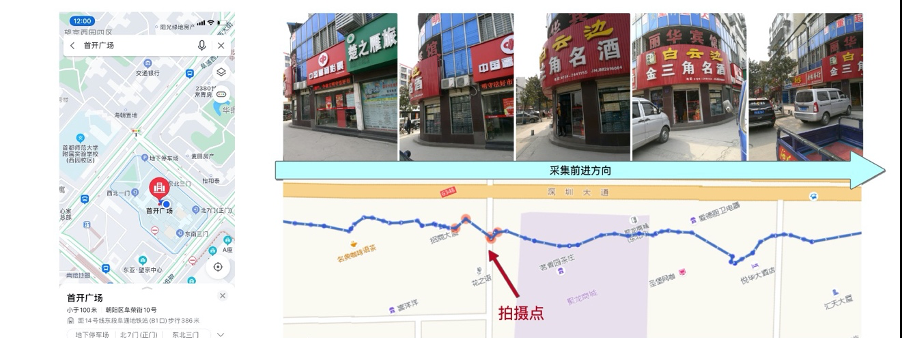
下圖是一個POI從采集到生産,再到使用的示意圖。輸入的是連續采集的圖像,對于生産環節,最重要的是計算每個POI的内容和位置。然後和母庫中的POI比對,确認這個POI是已經存在的,還是需要新增。從圖像中識别POI的名稱,計算坐标,都需要用到計算機視覺技術。
本文主要介紹的是名稱的部分。實際上,高德的POI生産不是全自動化的,而是人機結合的方式。當機器不能自動化,或者置信度較低時,交給人工作業。

高德的POI資料采集—生産—使用流程示意圖
POI資料豐富多彩的呈現形式,給自動化的處理過程帶來了挑戰,包括:文字的識别、是否為POI、文字之間關系、如何命名(定名)…
以下圖為例,從原始圖像,到自動生成POI的名稱,包含了以下幾項關鍵的計算機視覺技術:自然場景文字識别、文本屬性判定和結構化處理、名稱自動生成…
自然場景文字識别
文字識别,簡單說,就是從一張圖檔中,找到裡面的文本,給出正确的字元。從文字識别問題的發展過程來看,它包含了不同的子問題。
首先,大家比較熟悉的名詞是OCR,中文翻譯過來是光學字元識别。原意是利用光學掃描器,将印刷體文字讀成二進制資料,再識别成ascii碼字元,輸出出來。
OCR問題曆史比較悠久,上個世紀80、90年代,就有不少研究論文,以及商業化産品。比如我們熟悉的深度學習創始人之一Yann Lecun,他在90年代初,就用神經網絡識别手寫的郵政編碼,被美國銀行商用化了。
随着文字識别技術的發展,它的應用範圍也變多了。除了印刷體、手寫體之外,任何一張普通的包含了文字的圖檔,是不是都可以識别出來呢?
在下圖中,中間一列的問題叫做born-digitial,也就是說文字是由電腦生成的,文字的字型、版式,相對比較固定。
第3列是自然場景的文字識别問題,稱為STR,也就是在真實存在的文字,比如店鋪名稱、路牌,這種文字識别問題,因為拍照的角度問題、光照問題、圖檔品質問題,應該說難度是最大的。也是現在學術界研究比較多的一種類型。
當然,現在的STR技術,會面臨很多的挑戰:包括字型問題、排版問題、多語言問題,以及由拍攝帶來的光照問題、模糊問題。
一個店鋪門匾上的文字,比其他場景的會更複雜,因為它要表達自己的特點,要讓你“過目不忘”,是以更容易出現各種藝術字、各種不同的裝飾效果。
而且,高德地圖要維護全國的POI資料,在不同城市上,它的地名、店鋪名、品牌名,本身是一個非常大的詞庫。
STR技術發展:傳統算法(before 2012)
先簡單介紹一下STR技術。
自然場景文字識别(STR)的發展大緻可以分為兩個階段,以2012年為分水嶺,之前是以傳統圖像算法為主;之後,進入了深度學習算法的階段。
2012年之前,文字識别的主流算法都依賴于傳統圖像處理技術和統計機器學習方法實作。分為文本行檢測、文字識别兩部分。
文本行檢測,一般是先預處理,利用二值化、連通域分析、MSER顯著性區域算子等算法,定位文字區域,提取文本行候選,然後通過分類,去除掉無效候選。
文字識别,一般是通過切割,找出字元/單詞的候選,再通過機器學習分類器,對每個字元/單詞進行分類。
傳統的文字識别方法,在簡單的場景下能達到不錯的效果,但是不同場景下都需要獨立設計各個子產品的參數。遇到複雜的場景,很難調整參數,得到泛化性能好的模型。
STR技術發展:深度學習算法(after 2012)
大概從2012年開始,跟其他的計算機視覺問題一樣,STR也進入了深度學習的階段。
上面講到的文本行檢測、文字識别兩個子問題,分别都有一些深度學習的模型來解決。下面列舉幾個比較典型的工作。
最左邊,是一個文本行檢測模型,華中科技大學的Textboxes++,它是在類似SSD的網絡結構的基礎上,對四邊形的四個頂點的坐标分别做回歸,以解決長寬比、旋轉這類問題。
中間是一個序列識别模型。可以說這是在深度學習階段以後,出現的一類新的解題方法。輸入一個字元序列的圖像,傳統的方案是必須要切割成單個字元,或者單詞,再對它們做分類,有了LSTM這種RNN模型,可以對前後特征序列做編碼,再通過引入CTC loss,就可以訓練一個完整的序列識别模型。
除了将文本行檢測、識别兩個環節改造成深度學習的方案以外,也有一些工作在試圖把兩者整合起來,形成一個end-to-end的方案。整合的目的是什麼呢?不難想象,如果能夠識别出文本的内容,理論上應該可以檢測的更準。比如,如果可以識别出“深度學”這3個字,那是不是可以通過某種網絡的回報信号告訴檢測器,後面應該還有一個“學習的習”字。
第三列是一個end-to-end的工作,他是把faster r-cnn和LSTM接到同一個網絡裡,在對每個proposal做分類和坐标回歸的同時,也做字元的識别。
高德的STR技術
高德在STR上的技術,其實也是分成文本行檢測、字元識别兩部分。
在實際工作中并沒有使用“端到端”的模型,因為這種分子產品的模型,更容易優化局部的效果,比如為某一個子產品增加樣本,或者換一個模型。
在字元識别的環節,可以看到高德是平行使用了兩種方案。上面的分支是單字元的檢測和識别,下面的分支是整個文本序列的識别。
高德的STR技術——文本行檢測
首先看文本行檢測。在早期的時候,大概2017年之前,使用語義分割模型,比如FCN、deeplab來分割文本行。
到2017年Mask R-CNN出現之後,Instance segmentation技術越來越成熟,我們發現執行個體分割在文本行檢測這個問題上的效果,也超過了語義分割模型。最重要的是,因為要單獨識别每個文本行,執行個體分割很自然地就解決了這個問題。
而語義分割,還要做大量的後處理,才能把不同的文本行區分開。
當然除了Mask R-CNN以外,我們也會使用其他的執行個體分割模型。
在實際的業務問題上,高德的文本行檢測的效果。不管是文本行密集、還是模糊的情況下,檢測的效果都達到了很高的水準。
高德的STR技術——文字識别
文字識别,高德實際上是用了兩個分支,單字元的檢測識别,以及序列的識别。最終識别結果,是這兩個分支的輸出的融合。
為什麼要用兩個分支?
可以看這個例子,對于“一二三四的一”,單字元是不容易準确地檢測到的,因為它很容易和背景混淆。
但是因為它位于文本行中間,通過整個序列是可以識别出來的。
那隻依靠序列識别,把單字元的分支去掉,是否可以?或者說會有什麼問題?這個留給同學們自己思考。
序列識别模型
早期的序列識别模型,主要是使用 LSTM + CTC loss,後來替換成了帶有attention layer的LSTM。引入了attention,可以使在每一個timestep輸出時,網絡對特征輸入更聚焦,預測的效果也更好。
通過這些方法,對于不同的字型、不同方向、甚至不同語言,識别效果都是不錯的。
Hard case的挖掘和生成
在實際的工作中,除了模型的設計和優化,也會面臨很多其他的問題。
一個比較大的問題是,漢字的字元很多。常用漢字有大概3000-5000個,但是在POI中看到的字元,會遠遠超過這個數字。
高德地圖有7000萬個POI,大家可以想想會是個什麼數字。
針對這個問題,我們有幾個不同的解決方案。比如可以從POI的名稱裡,找到感興趣的字元,再找到采集圖檔,再交給人工去标注。也可以通過電腦的字庫,加上一些渲染效果,合成一些樣本。
高德是從2016年左右,開始研發文字識别技術,到現在還在持續優化。為了檢驗技術能力,高德視覺技術團隊也參加過一些競賽。OCR領域比較大的一個競賽是 ICDAR,高德參加了2017年,2019年的文本行定位、字元識别的比賽,也有一些不錯的成績。
文本屬性判定和結構化處理
在對場景中的文字進行檢測和識别以後,需要判斷哪些文字和POI名稱有關。是以,需要判斷每個文本行的屬性;同時,臨近的多個文本行往往是有關系的,需要計算它們的關系,進行結構化的輸出。
文本屬性判定問題
這個問題是有挑戰性的。一個文本行是否為POI名稱,和它的文本内容、所處的位置,都有關系。以上圖為例,僅看“會員上網,2元/小時”,基本可以猜出來,這不是一個POI名稱。而同樣都是“百世快遞”,當它處在店鋪上方的牌匾上時,它大機率是一個POI名稱;當它處在快遞車身上時,它不是我們想制作的名稱。
文本屬性的判定,最直接的一個任務是降噪:将明顯無效的POI文本排除掉。高德使用了圖像和文本雙通道的卷積神經網絡,取得了比較明顯的降噪效果。
既然可以将文本行判定成POI名稱和噪聲兩個類别,擴充一下,還可以将POI名稱相關的文本分成多個屬性類别,包括主名稱、分店名、營業範圍、聯系方式等。在制作POI名稱時,人工會根據一定的工藝規範,選取其中一部分文本,也會根據這些文本的屬性,自動選取或舍棄,以及排序,最終生成POI名稱。
另外,高德也引入了牌匾的語義分割,确定每個牌匾獨立的邊界。有邊界的情況下,主名稱是唯一的。
名字自動生成
最後,看一下名稱自動生成的問題,以及解法。
在文字識别、屬性判定之後,怎樣自動生成POI名稱呢?人在掌握了作業工藝之後,可以根據挂牌推斷出這個店的正确名稱(這也是一個合格的挂牌的基本功能)。那麼,機器能否學習和掌握命名規則,進而根據挂牌生成名稱呢?
在現實世界中,這個問題的難度并不低。以下方的這個牌子為例,正确的POI名稱是什麼呢?
來看更多的例子:
名稱自動生成模型
如上,輸入的是多個文本行,輸出是這些文本行的标簽(是否被選擇作為最終名稱的一部分),以及順序。如果不考慮圖像資訊,這是個NLP問題。可以采用BERT模型訓練。把問題定義成一個雙任務的學習問題,包括分類任務和回歸任務。
把圖像資訊也加入到模型中。輸入是所有文本行的bounding box,使用一個Graph Attention Network将其編碼成特征,和BERT模型特征連接配接起來。最終提升了模型的學習能力。
進一步地,受到微軟的工作的啟發,高德也使用了VL-Bert模型。名稱生成的品質,最終提升到了95%。
這是名稱自動生成的一些效果。前3個例子,盡管排版各不相同,模型都能夠比較好地學習到名稱生成的規則。
當然,如圖中的bad case,當挂牌的版式不常見時,模型的預測會出現問題。這也是後面的優化方向。
關于高德視覺團隊
由分布在西雅圖、矽谷、北京等地的傑出科學家和工程師組成,是高德地圖視覺算法核心團隊。為地圖、導航和出行的新未來解決難題,探索創新技術。涵蓋圖像了解、視訊分析、多源融合等技術,面向地圖及高精地圖制作、定位、交通及預測、AR導航、輔助駕駛以及資訊娛樂等領域。是高德地圖高精尖技術發展的核心引擎。