KVM全稱是Kernel-based Virtual Machine,
目前開源的虛拟化技術包括XEN,KVM,QEMU
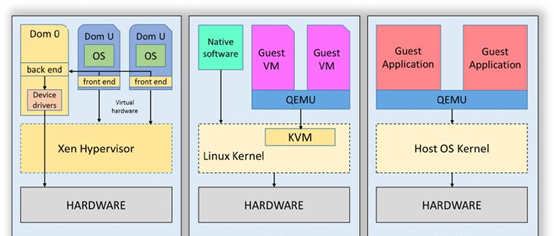
- 從上圖看Xen的特點是硬體模拟這塊直接由Xen Hypervisor程序完成,并且其是屬于半虛拟化,也就是說Dom U裡面的Guest OS需要一定改造
- 最右圖屬于使用QEMU的user mode emulation模式,不需要有Guest os,可運作user mode application,通過TCG進行指令級的動态翻譯(比如arm—x86),常用于指令集仿真場景。
- 中間即KVM模式,屬于全虛拟化,Guest OS的資源比如memory,irq等由qemu程序建立,qemu發起對KVM控制,調用cpu 切換到Guest OS運作。KVM屬于linux kernel針對虛拟化的實作,x86 arch下對應intel VT-x,AMD-v技術(即vmx與svm)。
接下來具體介紹下KVM,如下圖

從程序角度講qemu,host os,guest OS(這裡os程序指kernel),三者是三個程序,三者互相互動。在guest OS的視角察覺不到其他兩者(virtio這種半虛拟化除外)。如圖一個qemu process負責運作一個guest os。
三者的關系一般為:
- host os 通知qemu通過向其程序發送eventfd形式(qemu epoll it);
- qemu控制host os一般通過對其裝置節點/dev/kvm進行ioctl。
QEMU&KVM-1 memmory virtualization - guest os一般不直接與host os,qemu進行互動,在guest OS 程序的視角是察覺不到host os與qemu,guest os一般直接發起對guest memory通路,該memory的io行為由虛拟化硬體功能比如iommu可以直接捕獲。
kvm memory virtualization:
- 結合上圖先看右中部分,guest physical memory這塊對于QEMU程序其實是一段virtual memory region即qemu全局的address_space_memory,申請到這塊memory region會通過host os KVM子產品 ioctl KVM_SET_USER_MEMORY_REGION的方式遞交給HW EPT(Extension Page Table) MMU接管。
- 看圖中左下角部分當guest os 通路GPA時是由EPT轉換成HPA通路。EPT主要類似MMU的PageTable用來負責維護GVA->GPA->HPA的映射關系。(這裡針對intel VT-X)。
GVA:Guest Virtual Address GPA:Guest Physical Address
HPA:Host Physical Address
memory region init:
- 記憶體虛拟化的開始由qemu發起add memory region,該memory作為成guest os的physical memory使用,guest os image可以boot到該memory。
- 調用流程如下:有qemu的main函數調用qemu_init,接着通過ioctl将memory托管給kvm,在kernel mode裡,kvm建立mem slot,用于記錄memory 相關資料,HVA,GPA,size,dirty page bitmap等,并加入mem slot list,後續guest os 發生page fault過程會用到該資料。
memory io:
- 如圖在左側QOM init後層層調用,通過ioctl KVM_RUN,切換到kernel mode, 調用vmx_vmenter更新vmcs切換進入Guest os mode,運作Guest OS。當Guest OS發生memory通路會産生hadrware EPT VILOATION(類似page fault)這時發生vmx_vmexit切換到Host os mode,進入EPT VIOLATION異常處理流程擷取到通路内容,接着繼續切入Guest os繼續運作。
- VFIO device create
在使用者态将vfio分為container/group/device。通過打開dev/vfio 可以得到container,通過打來/dev/vfio/X 可以得到group。通過ioctl可以得到device
一個VM對應一個container,container可包含多個group,一個group可包含多個device
一般在pass through情況下container:group:device為1:1:1
具體VFIO介紹可參考
https://www.kernel.org/doc/Documentation/vfio.txt下面為VFIO device建立過程
QEMU中依次擷取到container,group,建立device,通過ioctl在linux KVM中建立VFIO裝置
- VFIO BAR 虛拟化
VFIO的pci裝置memory 虛拟化主要是PCI BAR space的虛拟化。包括MMU參與的BAR mmap将HVA(GPA)轉換成HPA,IOMMU參與的BAR remap将HVA轉換成GPA(HVA).
如下圖通過MMU+IOMMU即完成BAR GVA-->HPA的轉換,intel cpu中該IOMMU技術稱為VT-d
iommu driver位于linux-5.7.9/drivers/iommu/dmar.c。當guest 通路BAR時,會觸發iommu 中斷(類似于pagefault),進而通路到GPA(HVA)。
- VFIO-PCI BAR mmap
下圖是VFIO-PCI BAR mmap的過程,QEMU把已經建立的使用者空間的bar memory region,通過
mmap vfio device裝置節點/dev/vfio/xxx,映射到host kernel space,并做了pci_iomap, 對該region進行remap_pfn_range頁表映射,即配置好mmu。
- VFIO-PCI BAR remap
下圖為 BAR remaping過程,涉及到vfio driver,iommu driver
這裡說明下intel vt-x(EPT),vt-d (iommu) 是memory虛拟化的關鍵