磨刀不誤砍柴工,帶你搞定雲網絡系統性能測試
[TOC]
一、前言
在部署或管理網絡系統時,我們更多的是關心網絡的連通性,而對于其整體的性能往往考慮不多,或者即使考慮到性能、異常或穩定性的問題,但卻發現沒有合适的手段去測試或監控網絡健康狀況。在本文中,首先簡單介紹一下網絡性能測試名額重點會關注哪些名額、在開展性能測試時,如何預估系統性能以便合理的規劃和部署測試環境,然後會介紹基本的網絡連通性測試工具、網絡性能測試工具以及在開展性能測試時如何部署監控,更加直覺的統計性能名額等。因為社群中已經有非常完善的文檔,本文不再重複造輪子,隻是簡單地介紹并輔以幾個簡單demo執行個體,旨在雁過留聲,抛磚引玉。平時遇到問題時能夠提供一些解決方案或思路,歡迎各位大佬指教。
1.1 網絡性能測試名額
性能測試的目的是以性能名額預期為前提,對系統進行施壓,驗證系統在無資源性能瓶頸的情況下,是否能達到預期目标。對于不同的服務或應用場景,可能關注的名額側重點存在一定差異,對于底層系統網絡性能測試來說,通常會重點關注以下名額:
- 可用性,可用性是對一個系統最基本的要求,開展工作之前首先需要确認一下網絡連通性,正常的工具主要有ping、fping、telnet、curl等工具判斷網絡鍊路是否通暢。需要注意的是,由于ping是基于ICMP協定實作的,能ping通隻能說明網絡是能通的,不能說明具備對應的端口通路權限。通常情況下需要結合telnet、curl等工具來判斷網絡連通性及服務可用性。
- 帶寬BPS,每秒所能傳送的比特數。通常所說的帶寬指的是網絡中節點之間的極限帶寬,由于節點之間的鍊路通暢是不完全可見的,是以極限帶寬通常是由組成網絡的裝置能力所決定的。
- 吞吐量(throughput),網絡吞吐量是指在某個時刻,在網絡中的兩個節點之間,提供給網絡應用的剩餘帶寬,通過網絡吞吐量可以尋找出網絡瓶頸。吞吐量的衡量符合馬桶效應,比如,即使
client
server
100M
100M
10M
10M
- PPS(packet per second),表示以網絡包機關的傳輸速率。PPS通常用來評估網絡的轉發能力,而基于Linux伺服器的轉發,很容器受到網絡包大小的影響,通常選擇1bytes的資料包測試系統極限場景下的pps。
- 時延,表示從一端送出請求後直到收到遠端響應所需要的時間。這個名額在不同場景中可能會有不同含義。它可以表示建立連接配接需要的時間(比如TCP握手延遲),或者一個資料包往返所需時間(比如RTT)
- 丢包率,網絡丢包率是指測試中所丢失資料包數量占所發送資料包的比率,通常在吞吐量範圍内測試。丢包率主要與用戶端到網站伺服器之間每段路由的網絡擁塞程度有關。由于交換機和路由器的處理能力有限,當網絡流量過高來不及處理時就将一部分資料包丢棄造成丢包。由于TCP/IP網絡能夠自動實作重發,這樣發生丢包後不斷重發,将造成更大量的丢包。是以,網絡擁塞發生後經常會發生丢包率越來越高的現象,和馬路上的交通堵塞十分相似。
- 抖動率:抖動率是網絡延遲的變化量,它是由同一應用的任意兩個相鄰資料包在傳輸路由中經過網絡延遲而産生;計算方法:抖動率由相鄰資料包延遲時間差除以資料包序号差得到。
1.2 系統的網絡性能評估
系統的性能名額,一般情況下會在産品需求文檔中有較明确定義,QA同學以此為依據部署環境,開展測試任務。對于探索式的性能測試來講,通常需要QA同學橫向了解一下相關名額的合理範圍,例如需要測試指定網卡性能表現,帶寬跟實體網卡配置是直接關聯的,網卡确定後,帶寬也就确定了(實際帶寬受限于整個網絡鍊路中最小的那個子產品),為了更加有效的預估,可以參考說明文檔、競品公布的性能資料或者根據經驗值分析。比如測試網關的極限帶寬,假設網關節點網卡配置為兩張82599 10Gb網卡做bond1,那麼理論極限帶寬不會超過20Gb,加上實體損耗,實際評估的帶寬約為15Gb~18Gb之間,假設用戶端與服務端均采用相同規格實體機部署,單台實體機帶寬上限約為8Gb,要想獲得網關節點的真實極限帶寬,用戶端與服務端需要至少分别部署三台實體機。
二、 網絡連通性測試工具
在完成測試方案設計、評審以及環境部署之後,首先需要做的是測試服務可用性,相關的測試工具上文中已有提及,這裡主要簡單介紹ping正常的使用方法,其它工具如mtr、NMap、Netcat、fping、paping等可通過man指令檢視。
2.1.1 ping
首先簡單介紹一下ICMP協定,ICMP是(Internet Control Message Protocol)Internet控制封包協定。它是TCP/IP協定族的一個子協定,用于在IP主機、路由器之間傳遞控制消息。控制消息是指網絡通不通、主機是否可達、路由是否可用等網絡本身的消息。這些控制消息雖然并不傳輸使用者資料,但是對于使用者資料的傳遞起着重要的作用。ping指令是基于ICMP協定實作的。使用這個指令判斷網絡的連通性以及網速,也可實作域名解析,預設使用該指令會一直發送ICMP包直到使用者手動中止,可以使用以下常用參數控制資料包的傳輸:
-
-c
-
-W
-
-I
-
-s
在ping過程中按下
ctrl+|
會列印出目前的summary資訊,統計目前發送包數量、接收數量、丢包率等。示例,如下一台雲主機eth0配置了secondaryIP,需要測試一下網絡連通性
root@pytest-likailiang-1t3j9c-2:~# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether fa:16:3e:b7:b2:ca brd ff:ff:ff:ff:ff:ff
inet 172.16.1.2/24 brd 172.16.1.255 scope global eth0
valid_lft forever preferred_lft forever
inet 172.16.1.3/24 scope global secondary eth0
valid_lft forever preferred_lft forever
inet6 fe80::f816:3eff:feb7:b2ca/64 scope link
valid_lft forever preferred_lft forever
root@pytest-likailiang-1t3j9c-2:~# ping 192.168.1.70 -I 172.16.1.3 -c 10 -i 2 -w 10 -s 64
PING 192.168.1.70 (192.168.1.70) from 172.16.1.3 : 56(84) bytes of data.
64 bytes from 192.168.1.70: icmp_seq=1 ttl=63 time=1.51 ms
64 bytes from 192.168.1.70: icmp_seq=2 ttl=63 time=0.972 ms
2/2 packets, 0% loss, min/avg/ewma/max = 0.972/1.242/1.444/1.512 ms
64 bytes from 192.168.1.70: icmp_seq=3 ttl=63 time=0.766 ms
64 bytes from 192.168.1.70: icmp_seq=4 ttl=63 time=0.716 ms
64 bytes from 192.168.1.70: icmp_seq=5 ttl=63 time=0.681 ms
5/5 packets, 0% loss, min/avg/ewma/max = 0.681/0.929/1.204/1.512 ms
--- 192.168.1.70 ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 8010ms
rtt min/avg/max/mdev = 0.681/0.929/1.512/0.309 ms
root@pytest-likailiang-1t3j9c-2:~#
需要說明的是與ping要等待某一主機連接配接逾時或發回回報資訊不同,fping給一個主機發送完資料包後,馬上給下一個主機發送資料包,實作多主機同時ping。如果某一主機ping通,則此主機将被打上标記,并從等待清單中移除,如果沒ping通,說明主機無法到達,主機仍然留在等待清單中,等待後續操作。Fping程式類似于ping。Fping與ping不同的地方在于,fping可以在指令行中指定要ping的主機數量範圍,也可以指定含有要ping的主機清單檔案。
2.1.2 mtr
mtr(全稱 my traceroute,是一個把 ping 和 traceroute 合并到一個程式的網絡診斷工具,功能更強大。mtr預設發送ICMP資料包進行鍊路探測,使用者還可以通過-u參數來指定使用UDP資料包用于探測。相比traceroute隻會做一次鍊路跟蹤測試,mtr會對鍊路上的相關節點做持續探測并給出相應的統計資訊。mtr能避免節點波動對測試結果的影響,是以其測試結果更正确。
mtr有Linux和Windows兩種版本,在Windows系統下可以直接使用WinMTR工具,WinMTR是Windows下關于mtr的圖形化工具,
WinMTR下載下傳位址。WinMTR無需安裝,下載下傳完畢後,直接解壓運作即可。Linux環境下直接使用mtr指令即可,安裝及指令行操作參考:
安裝mtr工具
apt-get install mtr -y mtr (My traceroute)幾乎是所有 Linux 發行版本預裝的網絡測試工具,內建了 tracert 與 ping 這兩個指令的圖形界
root@slaver1:~# mtr -h
usage: mtr [--help] [--version] [-4|-6] [-F FILENAME]
[--report] [--report-wide] [--displaymode MODE]
[--xml] [--gtk] [--curses] [--raw] [--csv] [--json] [--split]
[--no-dns] [--show-ips] [-o FIELDS] [-y IPINFO] [--aslookup]
[-i INTERVAL] [-c COUNT] [-s PACKETSIZE] [-B BITPATTERN]
[-Q TOS] [--mpls]
[-a ADDRESS] [-f FIRST-TTL] [-m MAX-TTL] [-U MAX_UNKNOWN]
[--udp] [--tcp] [--sctp] [-P PORT] [-L LOCALPORT] [-Z TIMEOUT]
[-G GRACEPERIOD] [-M MARK] HOSTNAME
See the man page for details.
如上圖所示,mtr測試結果每列數值的說明如下:
root@slaver1:~# mtr -c 2 -r 114.114.114.114
Start: Wed Aug 19 15:35:05 2020
HOST: slaver1 Loss% Snt Last Avg Best Wrst StDev
1.|-- ??? 100.0 2 0.0 0.0 0.0 0.0 0.0
2.|-- ??? 100.0 2 0.0 0.0 0.0 0.0 0.0
3.|-- ??? 100.0 2 0.0 0.0 0.0 0.0 0.0
4.|-- ??? 100.0 2 0.0 0.0 0.0 0.0 0.0
5.|-- ??? 100.0 2 0.0 0.0 0.0 0.0 0.0
6.|-- 61.164.31.126 0.0% 2 1.7 2.8 1.7 3.9 1.4
7.|-- 220.191.200.207 0.0% 2 5.2 5.4 5.2 5.7 0.0
8.|-- 202.97.76.2 0.0% 2 11.5 11.6 11.5 11.7 0.0
9.|-- 222.190.59.206 0.0% 2 14.3 16.3 14.3 18.2 2.6
10.|-- 58.213.224.170 0.0% 2 27.6 22.1 16.5 27.6 7.9
11.|-- public1.114dns.com 0.0% 2 14.3 14.3 14.3 14.4 0.0
Host:節點IP位址和域名(按n鍵可以切換顯示);
Loss%:節點丢包率;
Snt:每秒發送資料包數,預設值是10,可以通過參數-c指定;
Last:最近一次的探測延遲值;
Avg:探測延遲的平均值;
Best:探測延遲的最小值;
Wrst:探測延遲到最大值;
StDev:标準偏內插補點,越大說明相應節點越不穩定。 更多内容參考
雲社群2.1.3 網貓netcat
NetCat是一個非常簡單的Unix工具,可以讀、寫TCP或UDP網絡連接配接,在linux和window環境下均可使用,社群文檔非常豐富,執行個體參考下文連結。
netcat
使用的基本形式為:
nc 參數 目的位址 端口 常用的參數說明如下:
-k 在目前連接配接結束後保持繼續監聽
-l 用作端口監聽,而不是發送資料
-n 不使用 DNS 解析
-N 在遇到 EOF 時關閉網絡連接配接
-p 指定源端口
-u 使用 UDP 協定傳輸
-v (Verbose)顯示更多的詳細資訊
-w 指定連接配接逾時時間
-z 不發送資料 執行個體參考:
Linux 中的 netcat 網絡工具簡介,
“瑞士軍刀”Netcat使用方法總結2.1.4 xxxping
ping指令是一個很好用并且常用的網絡測試工具,它是基于ICMP協定,但是出于網絡安全等因素,大部分網絡環境以及雲環境可能都會禁止ICMP協定,是以在工作中,我們必須掌握一些其他比較流行的網絡測試工具,比如tcpping、tcping、psping、hping、paping等幾款網絡測試工具。社群文檔比較豐富,這裡不再詳細介紹。
三 、 網絡性能測試工具
網絡性能測試工具這裡主要介紹兩個常用的工具iperf和netperf,相關的工具如wrk 、pktgen等後續會加以補充
3.1 iperf
3.1.1 iperf簡介
iperf(iperf3)是一個網絡性能測試工具,采用C/S(用戶端/伺服器端)架構模式,可以測試TCP和UDP帶寬、模拟網絡故障等。利用iperf這一特性,可以用來測試一些網絡裝置如路由器,防火牆,交換機等的性能,評估系統QOS。iperf分為兩種版本,Unix/Linux版和Windows版,Unix/Linux版更新比較快,版本最新。Windows版更新慢。Windows版的iperf叫jperf,或者xjperf。jperf是在iperf基礎上開發了更好的UI和新的功能。
3.1.2 iperf安裝及使用說明
源碼安裝參考
iperf,推薦指令行直接安裝
~# apt-get install -y iperf3 | 指令行選項 | 描述 |
|---|---|
| 用戶端與伺服器共用選項 | |
| -i, --interval # | 設定每次報告之間的時間間隔,機關為秒。如果設定為非零值,就會按照此時間間隔輸出測試報告。預設值為零。 |
| -l, --len #[KM] | 設定讀寫緩沖區的長度。TCP方式預設為8KB,UDP方式預設為1470位元組。 |
| -p, --port # | 設定端口,與伺服器端的監聽端口一緻。預設是5001端口,與ttcp的一樣。 |
| -u, --udp | 使用UDP方式而不是TCP方式。參看-b選項。 |
| - w , --window #[KM] | 設定套接字緩沖區為指定大小。對于TCP方式,此設定為TCP視窗大小。對于UDP方式,此設定為接受UDP資料包的緩沖區大小,限制可以接受資料包的最大值。 |
| -B, -- bind host | 綁定到主機的多個位址中的一個。對于用戶端來說,這個參數設定了出棧接口。對于伺服器端來說,這個參數設定入棧接口。這個參數隻用于具有多網絡接口的主機。在Iperf的UDP模式下,此參數用于綁定和加入一個多點傳播組。使用範圍在224.0.0.0至239.255.255.255的多點傳播位址。參考-T參數。 |
| -C, --compatibility | 與低版本的Iperf使用時,可以使用相容模式。不需要兩端同時使用相容模式,但是強烈推薦兩端同時使用相容模式。某些情況下,使用某些資料流可以引起1.7版本的伺服器端崩潰或引起非預期的連接配接嘗試。 |
| -M, --mss #[KM} | 通過TCP_MAXSEG選項嘗試設定TCP最大資訊段的值。MSS值的大小通常是TCP/ ip 頭減去40位元組。在以太網中,MSS值 為1460位元組(MTU1500位元組)。許多作業系統不支援此選項。 |
| -N, --nodelay | 設定TCP無延遲選項,禁用Nagle's運算法則。通常情況此選項對于互動程式,例如 telnet ,是禁用的。 |
| -V (from v1.6 or higher) | 綁定一個IPv6位址。 服務端:$ iperf -s –V 用戶端:$ iperf -c -V 注意:在1.6.3或更高版本中,指定IPv6位址不需要使用-B參數綁定,在1.6之前的版本則需要。在大多數作業系統中,将響應IPv4用戶端映射的IPv4位址。 |
| 伺服器端專用選項 | |
| -s, --server | Iperf伺服器模式 |
| -D (v1.2或更高版本) | Unix平台下Iperf作為背景守護程序運作。在Win32平台下,Iperf将作為服務運作。 |
| -o(v1.2或更高版本,僅用于Windows) | 重定向輸出到指定檔案 |
| -c, --client host | 如果Iperf運作在伺服器模式,并且用-c參數指定一個主機,那麼Iperf将隻接受指定主機的連接配接。此參數不能工作于UDP模式。 |
| -P, --parallel # | 伺服器關閉之前保持的連接配接數。預設是0,這意味着永遠接受連接配接。 |
| 用戶端專用選項 | |
| -b, --bandwidth #[KM] | UDP模式使用的帶寬,機關bits/sec。此選項與-u選項相關。預設值是1 Mbit/sec。 |
| 運作Iperf的用戶端模式,連接配接到指定的Iperf伺服器端。 | |
| -d, --dualtest | 運作雙測試模式。這将使伺服器端反向連接配接到用戶端,使用-L 參數中指定的端口(或預設使用用戶端連接配接到伺服器端的端口)。這些在操作的同時就立即完成了。如果你想要一個互動的測試,請嘗試-r參數。 |
| -n, --num #[KM] | 傳送的緩沖器數量。通常情況,Iperf按照10秒鐘發送資料。-n參數跨越此限制,按照指定次數發送指定長度的資料,而不論該操作耗費多少時間。參考-l與-t選項。 |
| -r, --tradeoff | 往複測試模式。當用戶端到伺服器端的測試結束時,伺服器端通過-l選項指定的端口(或預設為用戶端連接配接到伺服器端的端口),反向連接配接至用戶端。當用戶端連接配接終止時,反向連接配接随即開始。如果需要同時進行雙向測試,請嘗試-d參數。 |
| -t, -- time # | 設定傳輸的總時間。Iperf在指定的時間内,重複的發送指定長度的資料包。預設是10秒鐘。參考-l與-n選項。 |
| -L, --listenport # | 指定服務端反向連接配接到用戶端時使用的端口。預設使用用戶端連接配接至服務端的端口。 |
| 線程數。指定用戶端與服務端之間使用的線程數。預設是1線程。需要用戶端與伺服器端同時使用此參數。 |
關于網絡性能測試推薦參考
阿裡雲網絡性能測試方法。這樣在橫向資料對比時更具有參考價值,更多資料參考
3.1.3 iperf執行個體
帶寬測試通常采用UDP模式,因為能測出極限帶寬、時延抖動、丢包率。在進行測試時,首先以鍊路理論帶寬作為資料發送速率進行測試,例如,從用戶端到伺服器之間的鍊路的理論帶寬為100Mbps,先用
-b 100M
進行測試,然後根據測試結果(包括實際帶寬,時延抖動和丢包率),再以實際帶寬作為資料發送速率進行測試,會發現時延抖動和丢包率比第一次好很多,重複測試幾次,就能得出穩定的實際帶寬。
UDP模式
伺服器端:
iperf -u -s 用戶端:
iperf -u -c 192.168.1.1 -b 100M -t 60 在udp模式下,以100Mbps為資料發送速率,用戶端到伺服器192.168.1.1上傳帶寬測試,測試時間為60秒。
iperf -u -c 192.168.1.1 -b 5M -P 30 -t 60 用戶端同時向伺服器端發起30個連接配接線程,以5Mbps為資料發送速率。
iperf -u -c 192.168.1.1 -b 100M -d -t 60 以100M為資料發送速率,進行上下行帶寬測試。
TCP模式
iperf -s iperf -c 192.168.1.1 -t 60 在tcp模式下,用戶端到伺服器192.168.1.1上傳帶寬測試,測試時間為60秒。
iperf -c 192.168.1.1 -P 30 -t 60 用戶端同時向伺服器端發起30個連接配接線程。
iperf -c 192.168.1.1 -d -t 60 進行上下行帶寬測試
pps
iperf3 -s -p 3000
iperf3 -c server-ip -i 1 -t 2000 -V -p 3000 -b 1000000000 -l 100 -M 89
for i in $(seq 3200 3300) ; do screen -d -m iperf -s -p $i ; done
for i in $(seq 3200 3300 ); do screen -d -m iperf -c server-ip -i 1 -t 2000 -V -p $i -b 1000000000 -l 100 -M 89 ; done 3.1.4 參考
- 阿裡雲網絡性能測試方法: https://www.alibabacloud.com/help/zh/faq-detail/55757.htm#top
- 騰訊雲網絡性能測試方法: https://cloud.tencent.com/document/product/213/11460
- iperf指令: https://man.linuxde.net/iperf
- https://github.com/esnet/iperf
3.2 netperf
3.2.1 netperf簡介
Netperf是一種網絡性能的測量工具,主要針對基于TCP或UDP的傳輸。Netperf根據應用的不同,可以進行不同模式的網絡性能測試,即批量資料傳輸(bulk data transfer)模式和請求/應答(request/reponse)模式。
Netperf工具以client/server方式工作。server端是netserver,用來偵聽來自client端的連接配接,client端是netperf,用來向server發起網絡測試.在client與server之間,首先建立一個控制連接配接,傳遞有關測試配置的資訊,以及測試的結果:在控制連接配接建立并傳遞了測試配置資訊以後,client與server之間會再建立一個測試連接配接,進行來回傳遞特殊的流量模式,以測試網絡的性能。
社群提供的開源
Netperf隻能滿足兩個9的時延資料統計,當進行精度較高的專項性能測試時顯得無能為力,為此網易杭研雲計算同學對此進行了二次開發,能夠滿足9999值資料統計,項目位址參考
netperf-9999。
netperf常用指令行參數如下選項:
-H host :指定遠端運作netserver的server IP位址。
-l testlen:指定測試的時間長度(秒)
-t testname:指定進行的測試類型,包括TCP_STREAM,UDP_STREAM,TCP_RR,TCP_CRR,UDP_RR
-s size 設定本地系統的socket發送與接收緩沖大小
-S size 設定遠端系統的socket發送與接收緩沖大小
-m size 設定本地系統發送測試分組的大小
-M size 設定遠端系統接收測試分組的大小
-D 對本地與遠端系統的socket設定TCP_NODELAY選項 3.2.2 netperf 網絡測試模式說明
- TCP_STREAM Netperf預設情況下進行TCP批量傳輸,即-t TCP_STREAM。測試過程中,netperf向netserver發送批量的TCP資料分組,以确定資料傳輸過程中的吞吐量
- UDP_STREAM UDP_STREAM用來測試進行UDP批量傳輸時的網絡性能。注意:此時測試分組的大小不得大于socket的發送與接收緩沖大小,否則netperf會報出錯提示
- 測試UDP_STREAM模式下pps
pssh -i -h client-ips -O StrictHostKeyChecking=no 'for node in $(cat server-ips); do for i in $(seq 12010 12015); do screen -d -m netperf -H $node -p $i -t UDP_STREAM -l 100 -- -m 1 -R 1 ; done ; done'
- 測試UDP_STREAM模式下pps
- TCP_RR ,TCP_RR方式的測試對象是建立一次連接配接之後多次TCP request和response的交易過程,該模式下可以得到長連接配接極限帶寬或pps
- 測試TCP_RR長連接配接模式下pps
pssh -i -h client-ips -O StrictHostKeyChecking=no 'for node in $(cat server-ips); do for i in $(seq 12010 12015); do screen -d -m netperf -H $node -p $i -t TCP_RR -l 100 -- -r 1B,1B; done ; done' - 測試網絡延遲和吞吐量
./netperf_client_9999 -t TCP_RR -H <server-ip> -l 60 -- -r 1B,1B -O " MIN_LAETENCY, MAX_LATENCY,MEAN_LATENCY, P90_LATENCY, P99_LATENCY ,P999_LATENCY,P9999_LATENCY,STDDEV_LATENCY ,THROUGHPUT ,THROUGHPUT_UNITS"
- 測試TCP_RR長連接配接模式下pps
- TCP_CRR 與TCP_RR不同,TCP_CRR為每次交易建立一個新的TCP連接配接
- 測試TCP_CRR短連接配接模式下pps
pssh -i -h client-ips -O StrictHostKeyChecking=no 'for node in $(cat server-ips); do for i in $(seq 12010 12015); do screen -d -m netperf -H $node -p $i -t TCP_CRR -l 100 -- -r 1B,1B; done ; done'
- 測試TCP_CRR短連接配接模式下pps
- UDP_RR UDP_RR方式使用UDP分組進行request/response的交易過程
3.2.3 執行個體
測試網絡帶寬bps
在對端機器上啟動netserver,這是netperf自帶的一個服務端程式。可以不帶任何參數啟動。
root@lkl-stress-test-nginx-017:~# netserver -p 49999
Starting netserver with host 'IN(6)ADDR_ANY' port '49999' and family AF_UNSPEC 在本機輸入以下指令啟動netperf:
$netperf -H $(對端IP)
root@lkl-stress-test-nginx-016:~# netperf -H 172.16.0.153
MIGRATED TCP STREAM TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 172.16.0.153 () port 0 AF_INET : demo
Recv Send Send
Socket Socket Message Elapsed
Size Size Size Time Throughput
bytes bytes bytes secs. 10^6bits/sec
8192 65536 65536 10.00 15955.55 可以看到,帶寬的吞吐量基本上達到了約15G。輸出結果各個字段的含義如下:
| 字段名 | 含義 | 備注 |
|---|---|---|
| Socket size(bytes) | 緩沖區的大小 | – |
| Message size(bytes) | 資料包的大小 | |
| Elapsed Time(secs) | 測試時間 | |
| Messages Okay(個) | 發送成功的資料包數目 | |
| Messages Errors(個) | 發送失敗的資料包數目 | |
| Throughtput(10^6bits/sec) | 吞吐量 |
- PPS
- PPS 為每秒鐘發送成功的資料包個數
- 具體計算方法:PPS = 資料包發送成功的數目/測試時間
- 可以在 Server 端用 sar 指令來統計實際收到的資料包,具體指令如下所示,其表示每隔 1 秒統計一次,統計 300 次,sar 指令最後會對 300 次的統計結果求平均
sar -n DEV 1 300 測試延遲
在對端機器上啟動netserver。 在本機輸入以下指令啟動netperf:
root@lkl-stress-test-nginx-016:~# netperf -H 172.16.0.153 -t omni -- -d rr -O "THROUGHPUT, THROUGHPUT_UNITS, MIN_LATENCY, MAX_LATENCY, MEAN_LATENCY"
OMNI Send|Recv TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 172.16.0.153 () port 0 AF_INET : demo
Throughput Throughput Minimum Maximum Mean
Units Latency Latency Latency
Microseconds Microseconds Microseconds
22547.84 Trans/s 36 3605 44.23 可以看到,在resquest/response測試模式下,每秒的吞吐量為22547.84次,最小的時延為36微秒,最大為3605微秒,平均時延為44.23微秒。結果顯示,有比較少的封包的延遲比較厲害,達到了毫秒級,但是大部分都在100微秒級
3.2.4 參考
- 實體專線網絡性能測試方法: https://help.aliyun.com/document_detail/58625.html
- netperf 與網絡性能測量: https://www.ibm.com/developerworks/cn/linux/l-netperf/index.html
- https://www.cnblogs.com/xieshengsen/p/6493277.html
- https://sq.163yun.com/blog/article/190965728772210688
- 三層網絡PPS極限測試: https://blog.csdn.net/minxihou/article/details/84930250
- netperf 和 iperf 網絡性能測試小結: https://wsgzao.github.io/post/netperf/
- https://blog.didiyun.com/index.php/2018/12/07/netperf/
- 網絡性能測試方法: https://www.alibabacloud.com/help/zh/faq-detail/55757.htm
- http 性能測試 wrk使用教程: https://juejin.im/post/6844903550288396296
四、網絡資料監控工具
4.1 netdata
Netdata是Linux系統實時性能監測工具,以web的可視化方式展示系統及應用程式的實時運作狀态(包括cpu、記憶體、硬碟輸入/輸出、網絡等linux性能的資料)Netdata是一個高度優化的Linux守護程序,它為Linux系統,應用程式,SNMP服務等提供實時的性能監測。它用可視化的手段,将被監測者最細微的細節,展現了出來。這樣,你便可以清晰地了解你的系統和應用程式此時的狀況。
圖檔來源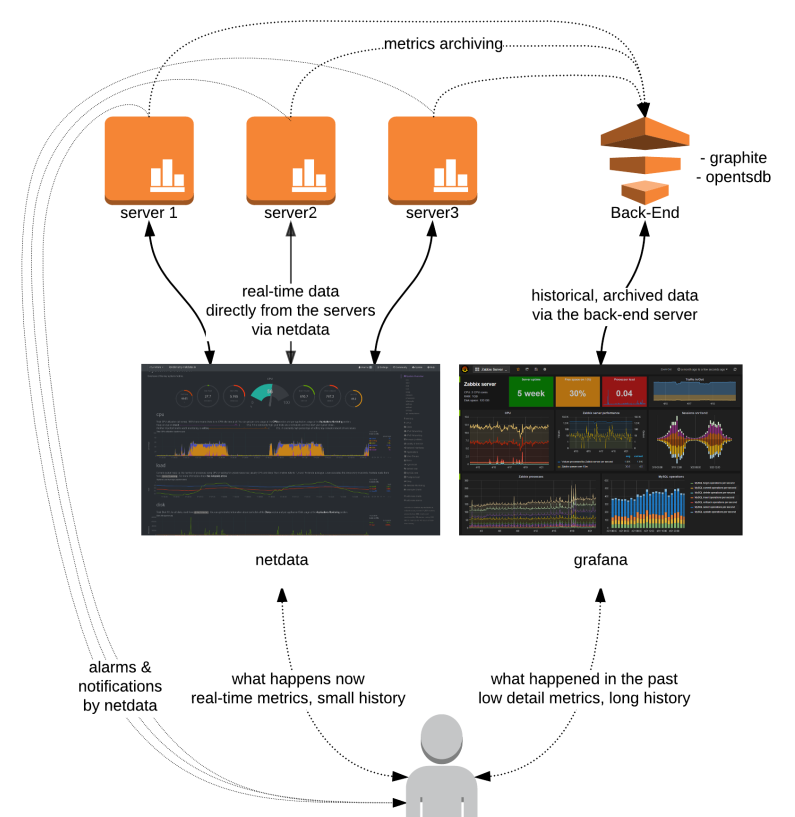
netdata部署直接參考
github實際效果參考:下圖是通過netdata監控雲主機eth0網卡的流量,可是直覺的看到收方向和發方向的流量狀況,相比
sar
工具統計更為直覺。

Fping類似于ping,但比ping強大。Fping與ping不同的地方在于,fping可以在指令行中指定要ping的主機數量範圍,也可以指定含有要ping的主機清單檔案。與ping要等待某一主機連接配接逾時或發回回報資訊不同,fping給一個主機發送完資料包後,馬上給下一個主機發送資料包,實作多主機同時ping。如果某一主機ping通,則此主機将被打上标記,并從等待清單中移除,如果沒ping通,說明主機無法到達,主機仍然留在等待清單中,等待後續操作。
下圖是netdata內建fping 監控網絡連通性,其中 fping.conf 的配置檔案為:
~# cat fping.conf
fping="/usr/local/bin/fping"
hosts="172.16.1.2 10.10.10.10" # 這邊配置需要ping的位址,通過空格隔離ip位址或域名
update_every=1
ping_every=1000
fping_opts=" -b 56 -r 0 -t 5000"
- 支援fping 監控
docker run -d --name=netdata \
-p 19999:19999 \
-v /etc/passwd:/host/etc/passwd:ro \
-v /etc/group:/host/etc/group:ro \
-v /proc:/host/proc:ro \
-v /sys:/host/sys:ro \
-v /var/run/docker.sock:/var/run/docker.sock:ro \
-v /root/fping.conf:/etc/netdata/fping.conf:ro \
--cap-add SYS_PTRACE \
--security-opt apparmor=unconfined \
hub.c.163.com/nvsoline2/netdata:fping - 監控資料持久化保留30天資料
需要配置dbengine,理論上5G硬碟可以支援 每秒2000個資料點,30天。
root@jiande1-dgw-jiande1:~# cat netdata.conf
[global]
memory mode = dbengine
page cache size = 32
dbengine disk space = 4999 啟動時使用上面這個netdata.conf配置。
- portcheck配置
這些都屬于
https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin插件。
~# cat portcheck.conf
update_every: 1
jobs:
- name: server1
host: 127.0.0.1
ports:
- 22
- name: server2
host: 59.111.96.215
ports:
- 9009
- name: nlb-beta-test
host: 59.111.245.80
update_every: 1
ports:
- 80 go.d.conf ,裡面把需要監控的項目打開
~# cat go.d.conf
# netdata go.d.plugin configuration
#
# This file is in YaML format.
# Enable/disable the whole go.d.plugin.
enabled: yes
# Enable/disable default value for all modules.
default_run: yes
# Maximum number of used CPUs. Zero means no limit.
max_procs: 0
# Enable/disable specific g.d.plugin module
# If you want to change any value, you need to uncomment out it first.
# IMPORTANT: Do not remove all spaces, just remove # symbol. There should be a space before module name.
modules:
example: yes
nginx: yes
portcheck: yes nginx監控demo
~# cat nginx.conf
jobs:
- name: local
url: http://10.199.128.66/nginx_status docker 啟動指令
docker run -d --name=netdata -p 19999:19999 \
-v /etc/passwd:/host/etc/passwd:ro \
-v /etc/group:/host/etc/group:ro \
-v /proc:/host/proc:ro \
-v /sys:/host/sys:ro \
-v /var/run/docker.sock:/var/run/docker.sock:ro \
-v /root/fping.conf:/etc/netdata/fping.conf:ro \
-v /root/example.conf:/etc/netdata/go.d/example.conf:ro \
-v /root/portcheck.conf:/etc/netdata/go.d/portcheck.conf:ro \
-v /root/nginx.conf:/etc/netdata/go.d/nginx.conf:ro \
-v /root/go.d.conf:/etc/netdata/go.d.conf:ro \
-v /root/netdata.conf:/etc/netdata/netdata.conf:ro \
--cap-add SYS_PTRACE \
--security-opt apparmor=unconfined \
hub.c.163.com/nvsoline2/netdata:fping 4.2 Prometheus
參考寫的另外一篇文章:
4.3 參考
- 實時系統性能監控工具: https://github.com/netdata/netdata
- https://www.hi-linux.com/tags/#NetData
- https://cloud.tencent.com/developer/article/1409664
續...