首先,可以試想一下,要在雲上部署一個人工智能訓練任務,需要做哪些工作?
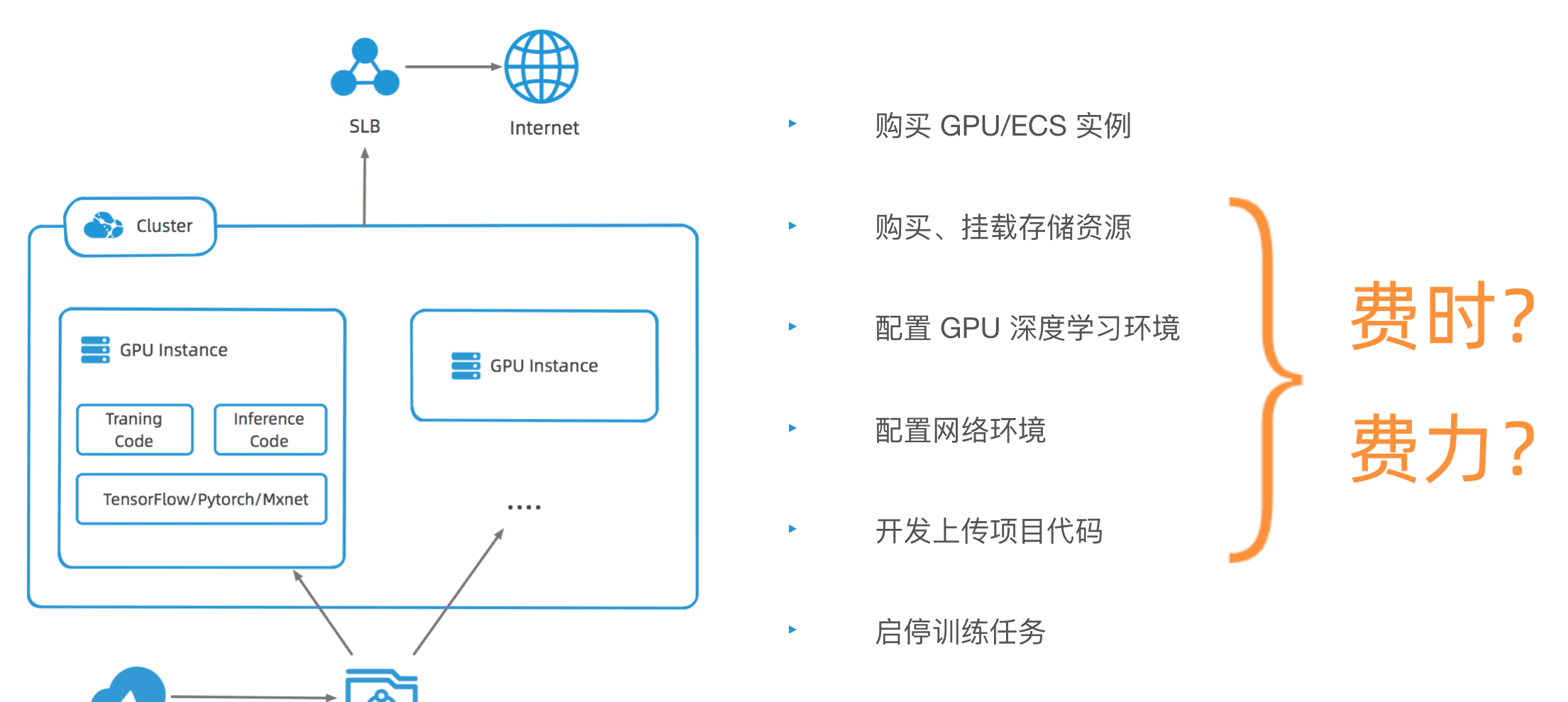
大體的部署架構如上圖所示。首先訓練任務需要一個 GPU 的叢集,裡面需要配置智能訓練所需的環境,還需要挂載 CPFS/NAS 這樣的存儲資源,來存儲和共享訓練資料。整個過程包括:購買 GPU 執行個體、購買挂載存儲資源、配置執行個體環境、配置網絡環、開發上傳訓練代碼境等等。整個過程費時費力。
工欲善其事必先利其器,在 Cloud Shell 中使用 Jupyter Notebook + FastGPU,可以省時省力的幫助開發者完成開發和部署的工作。
FastGPU
針對人工智能訓練的場景,阿裡雲提供了 FastGPU 工具,是一套建構在阿裡雲上的人工智能訓練的部署工具,提供便捷的接口和自動化工具實作人工智能訓練/推理計算在阿裡雲 IAAS 資源上的快速部署.它包含兩套元件:
- ncluster 運作時元件,它是個 python 庫,提供便捷的 API 将線下的人工智能訓練/推理腳本快速的部署在阿裡雲IAAS資源上進行計算
- ecluster 指令行元件,提供便捷的指令行工具用于管理阿裡雲上人工智能計算的運作狀态和叢集的生命周期。

使用 FastGPU 進行人工智能訓練,使用者的起點(source)為資料和訓練代碼,FastGPU 元件将幫助使用者自動完成中間訓練過程,包括計算/存儲/可視化資源的生命周期的管理等等,使用者最終擷取訓練完成後的模型/日志等(destination)。
可以看到人工智能訓練的全部流程(購買執行個體——啟動執行個體——建構 gpu 環境——部署項目代碼——啟動訓練——運作推理),通過 FastGPU 一個腳本就可以一鍵完成人工智能訓練的整個個過程。整個腳本的編寫也十分簡單,通過 ncluster 的 make_job,可以建立所需要的資源,還可以友善的定義所需資源數量、執行個體類型、執行個體鏡像等等。接着通過 upload 方法,可以将本地的檔案上傳到執行個體上去,最後通過 run 方法,可以在執行個體上執行任意指令。比如啟動 training,啟動 inferrence 等等。
最後通過 FastGPU 提供的第二個元件,ecluster 指令行,來管理任務和資源的運作狀态和生命周期。例如啟停任務,建立銷毀資源等等。比如下圖通過 ecluster ls 來展示所有訓練的執行個體資源。
CloudShell
Cloud Shell是阿裡雲提供的雲指令行産品,它是免費的網頁版指令行工具,允許使用者使用浏覽器啟動指令行進而管理阿裡雲資源。在啟動時會自動為使用者配置設定一台 Linux 管理機,并預裝 Aliyun CLI、Terraform、kubectl、fastgoup 等多種雲管理工具。
針對人工智能訓練的場景,使用 Cloud Shell 可以快速的完成雲上的模型訓練、資源管理、應用部署等工作,Cloud Shell 内置了 FastGPU,也是目前 FastGPU 唯一的使用管道,我們可以通過 FastGPU 來購買配置 GPU 執行個體,完成訓練模型的部署和運作。當然 Cloud shell 還具備很多便捷的特性,首先它是完全免費的,每次使用會自動建立一台 Linux 虛拟機,通過浏覽器可以随時随地使用,同時支援綁定 NAS 等存儲空間,保證個人檔案的永久存儲,同時内置了衆多工具和開發環境,像資料庫工具 Mysql Client、容器群裡工具 Kubectl、Heml,編排工具 Terraform、Ansible、代碼管理工具 Git 等等,開發環境包括 Node、Java、Go、Python,常用的基本都已經涵蓋。最重要的是會保障使用的安全,每個使用者配置設定的虛拟機都是完全獨立、互相隔離的。
Jupyter Notebook
是基于網頁的用于互動計算的應用程式。其可被應用于全過程計算:開發、文檔編寫、運作代碼和展示結果等。使用 Jupyter Notebook 可以友善的一站式開發、部署和運作我們的訓練任務。
由于 Jupyter Notebook 是基于網頁使用的,是以
除了内置 Jupyter Notebook 外,也提供了網頁預覽的功能,我們可以在 Cloud Shell 直接使用。
首先啟動 Jupyter Notebook
jupyter notebook --ip=0.0.0.0 --port=65000 --no-browser --NotebookApp.allow_origin=* 目前 Cloud Shell 隻允許在固定幾個端口上進行網頁預覽,是以 Jupyter Notebook 需要啟動到支援預覽的幾個端口上。然後在 Cloud Shell 右上角,打開對應端口的網頁預覽。
實操示例
我們來看一個真實的使用 FastGPU 部署人工智能訓練的代碼示例
#!/usr/bin/env python
import argparse
import ncluster
import os
import time
from ncluster import ncluster_globals
# setting parameters
INSTANCE_TYPE = 'ecs.gn6v-c8g1.2xlarge'
NUM_GPUS = 1
ncluster.set_backend('aliyun')
parser = argparse.ArgumentParser()
parser.add_argument('--name', type=str, default='fastgpu-gtc-demo',
help="name of the current run, used for machine naming and tensorboard visualization")
parser.add_argument('--machines', type=int, default=1,
help="how many machines to use")
args = parser.parse_args()
def main():
print('start job ...')
start_time = time.time()
# 1. create infrastructure
supported_regions = ['cn-huhehaote', 'cn-shanghai', 'cn-zhangjiakou', 'cn-hangzhou', 'cn-beijing']
assert ncluster.get_region() in supported_regions, f"required AMI {IMAGE_NAME} has only been made available in regions {supported_regions}, but your current region is {ncluster.get_region()} (set $ALYUN_DEFAULT_REGION)"
ncluster_globals.set_should_disable_nas(True)
job = ncluster.make_job(name=args.name,
run_name=f"{args.name}-{args.machines}",
num_tasks=args.machines,
instance_type=INSTANCE_TYPE,
disable_nas=True,
spot=True,
install_script='')
init_ncluster = time.time()
print('init ncluster:', init_ncluster - start_time)
# 2. upload code
job.upload('GTC')
job.run('cd GTC && conda activate torch_1.3_cu10.0_py36')
upload_data = time.time()
print('upload_data time:', upload_data - init_ncluster)
# 3. run the training job
job.tasks[0].run('conda activate torch_1.3_cu10.0_py36')
job.tasks[0].run('./train.sh 2>&1 | tee logs.log', non_blocking=False)
train_time = time.time()
print('training time:', train_time - unzip_time)
# 4. run the inference job
job.tasks[0].run('python inference.py 2>&1 | tee logs.inference.log', non_blocking=False)
print('inference time:', time.time() - train_time)
eclapse_time = time.time() - start_time
print(f'training and inference deploy time is: {eclapse_time} s.')
# 5. stop the instance (optional)
# job.stop()
if __name__ == '__main__':
main()
示例中首先定義了一些參數變量,包括執行個體類型,這裡采用的是采用單機單卡 V100 的執行個體,配置了執行個體名稱、執行個體數量,這裡簡單起見,就隻生産 1 台機器。
然後通過
make_job
來建立基礎設施,示例中沒有設定
image_name
鏡像名稱,會使用預設鏡像,是 CentOS 的阿裡 AI 雲加速鏡像,裡面內建了 TensorFlow/pytorch 等各種架構。然後關閉了 NAS 綁定,同時通過 Spot 來表示生産一個搶占式執行個體。
這裡通過
run
方法,可以在生産出來的執行個體上執行指令。接着通過 upload 方法上傳訓練腳本的檔案夾(示例中的訓練腳本放到了 GTC 檔案夾下)。upload 方法預設會将檔案上傳到執行個體的根目錄下。然後開始 run training,先激活 python 特定深度學習環境。然後調用訓練腳本:train.py。訓練完成後,執行推理腳本。
最後,可以通過
stop
方法來停止任務,這時 GPU 執行個體也會被停止,停止執行個體本身不會産生費用了。
這樣一個部署和運作的腳本就寫好了。最後執行該腳本。FastGPU 會自動的檢測有效可用的可用區,自動建立 VPC、虛拟機、安全組以及 ECS,并自動開始訓練等等。
完整的操作示例,您可以參考
雲上極速部署手勢識别訓練任務和場景應用的直播視訊。