1.背景
近期,在NLP領域預訓練模型受到了越來越多的關注。從ELMo到BERT,預訓練模型在不同的NLP問題取得了很好的效果。本文參考To Tune or Not to Tune? Adapting Pretrained Representations to Diverse Tasks論文, 針對預訓練模型BERT/EMLo,分析其在實際問題中的使用方式。
2.怎麼用BERT/ELMo解決問題
對于預訓練模型一般有兩種使用方式:
1) Feature extraction:
此方法模型的權重被固定的給下遊任務使用,優勢在于模型的權重隻訓練了一次,計算量較小。
2) Fine-tuning:
此方法模型的權重重新被下遊任務重新更新,優勢在于針對特定任務進行了微調,模型對特定任務表現效果較好。
3.實驗設定
3.1Feature extraction
對于ELMo和BERT,從所有層中提取單詞的上下文表示。 在下遊任務訓練過程中,學習層的線性權重組合,它被用作任務特定模型的輸入。 對于情感分析,采用雙向分類網絡。 對于句子對比對任務,我們使用ESIM模型。 對于NER,使用LSTM+CRF模型。
3.2 Finetune ELMo
對LM狀态進行max-pool并添加softmax圖層進行文本分類。 對于句子對比對任務,計算LM狀态之間的跨句子雙重注意力并使用池化,然後添加softmax層。 對于NER,使用LSTM+CRF模型。
3.3 Finetune BERT
将句子表示提供給softmax層,用于文本分類和句子對比對任務。 對于NER,提取每個标記的第一個單詞的表示輸入給softmax。
4.實驗結果
4.1 BERT vs ELMo
ELMo和BERT都比傳統的表示學習方法如Skip-thoughts好,不同任務的Feature extraction vs Finetune效果對比不一樣。ELMo來說,句對任務(MNLI )Feature extraction效果遠比Finetune好,對BERT來說,句子對任務 (STS-B)Finteune效果比Feature extraction好。原因:參考CV領域,原始任務和目标任務越接近,遷移學習效果越好,BERT預訓練中有預測下一句的任務,是以理所當然效果會好。然而為什麼ELMo Fiinetune後效果會差呢?
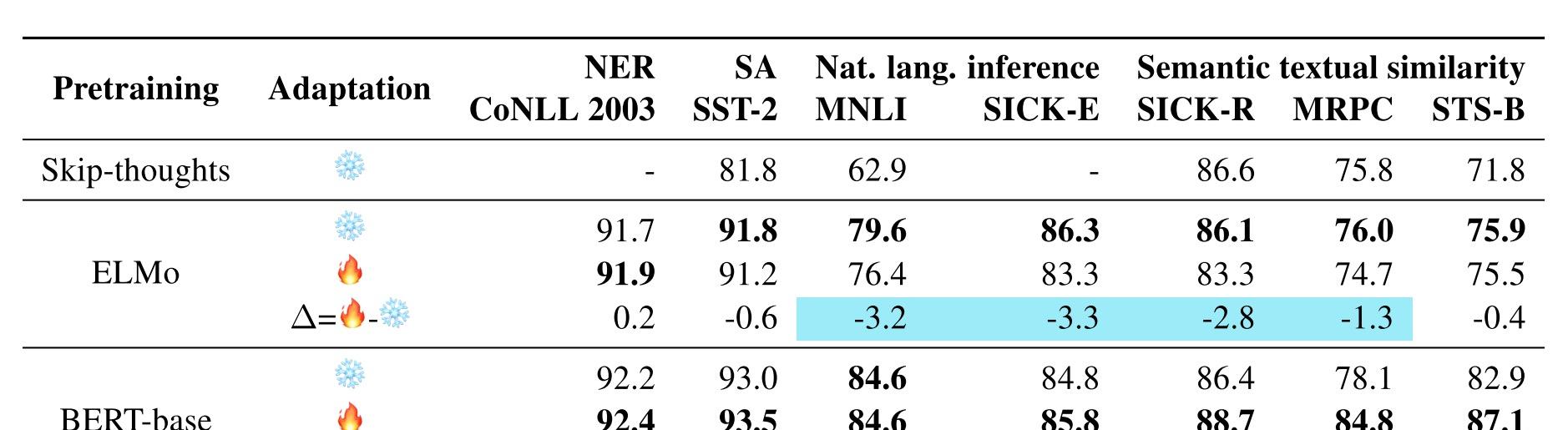
這要從句子對任務本身和ELMo的模型結構說起,EMLo使用的是雙向LSTM,并不擅長捕捉句子之間的互動資訊,而基于attention的Tranformer就不一樣了,比較擅長捕捉句子間的互動資訊,事實上在文本比對領域,互動模型一般都比孿生網絡效果好。下圖從連個實驗驗證了原生的EMLo本身不擅長句子對任務和BERT擅長句子對任務。

如上圖所示,EMLo增加了互動的attention之後句子對任務效果提升明顯,證明LSTM不擅長捕捉句子互動資訊。BERT對不同句子進行分别編碼後準确率下降,也證明BERT原生擅長捕捉句子之間互動資訊。
4.2 如何更好的Finetune
既然Finetune之後效果還會變差,有沒有辦法解決這個問題呢。針對NER任務 (句子對任務暫時無解),有兩種解決方法:1) 增加模型複雜度, 比如增加CRF層,如下圖所示,效果蹭蹭蹭上去了。2) 複雜的Finetune技巧如三角學習率 (slanted triangular learning rates) 、 discriminative fine-tuning、 gradual unfreezing。 這些技巧在BERT paper也都介紹過,實為海量模型Finetune的大殺器。
4.3不同層對任務影響
在實際的下遊任務中,NLP和CV有一個很大的差別。NLP不同任務可能需要的是上遊任務的某些層,比如BERT和ELMo論文所述,靠近輸入的層捕捉到詞法資訊擅長做POS等任務,靠近輸出的層捕捉到語義資訊。下圖的實驗結果進一步證明了這個結論。
實驗中使用不同層的向量求均值作為下遊任務輸入,可以看出需要語義了解的任務,越接近輸出的層表征效果越好。
6.結論
1.實際業務問題和Pretrain任務越接近,取得的效果越好
2.實際使用BERT 如有足夠訓練資料,Finetune效果會較好,反之,使用Feature extraction
3.實際使用ELMo, 一般情況下使用Feature extraction 效果較好
4.BERT比較擅長做句子對任務
5.不論Finetune 還是pretrained 模型,取特征的層數取決于任務類型,一般語義相關的取接近輸出層,詞法相關的取接近輸入層,特殊情況可取多層權重平均。
參考文獻
- To Tune or Not to Tune? Adapting Pretrained Representations to Diverse Tasks
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Deep contextualized word representations