雲栖号資訊:【 點選檢視更多行業資訊】
在這裡您可以找到不同行業的第一手的上雲資訊,還在等什麼,快來!
CPU是計算機的大腦。
1、程式的運作過程,實際上是程式涉及到的、未涉及到的一大堆的指令的執行過程。
當程式要執行的部分被裝載到記憶體後,CPU要從記憶體中取出指令,然後指令解碼(以便知道類型和操作數,簡單的了解為CPU要知道這是什麼指令),然後執行該指令。再然後取下一個指令、解碼、執行,以此類推直到程式退出。
2、這個取指、解碼、執行三個過程構成一個CPU的基本周期。
3、每個CPU都有一套自己可以執行的專門的指令集(注意,這部分指令是CPU提供的,CPU-Z軟體可檢視)。
正是因為不同CPU架構的指令集不同,使得x86處理器不能執行ARM程式,ARM程式也不能執行x86程式。(Intel和AMD都使用x86指令集,手機絕大多數使用ARM指令集)。
注:指令集的軟硬體層次之分:硬體指令集是硬體層次上由CPU自身提供的可執行的指令集合。軟體指令集是指語言程式庫所提供的指令,隻要安裝了該語言的程式庫,指令就可以執行。
4、由于CPU通路記憶體以得到指令或資料的時間要比執行指令花費的時間長很多,是以在CPU内部提供了一些用來儲存關鍵變量、臨時資料等資訊的通用寄存器。
是以,CPU需要提供 一些特定的指令,使得可以從記憶體中讀取資料存入寄存器以及可以将寄存器資料存入記憶體。
此外還需要提供加法、減、not/and/or等基本運算指令,而乘除法運算都是推算出來的(支援的基本運算指令參見ALU Functions),是以乘除法的速度要慢的多。這也是算法裡在考慮時間複雜度時常常忽略加減法次數帶來的影響,而考慮乘除法的次數的原因。
5、除了通用寄存器,還有一些特殊的寄存器。典型的如:
PC:program counter,表示程式計數器,它儲存了将要取出的下一條指令的記憶體位址,指令取出後,就會更新該寄存器指向下一條指令。
堆棧指針:指向記憶體目前棧的頂端,包含了每個函數執行過程的棧幀,該棧幀中儲存了該函數相關的輸入參數、局部變量、以及一些沒有儲存在寄存器中的臨時變量。
PSW:program status word,表示程式狀态字,這個寄存器内儲存了一些控制位,比如CPU的優先級、CPU的工作模式(使用者态還是核心态模式)等。
6、在CPU進行程序切換的時候,需要将寄存器中和目前程序有關的狀态資料寫入記憶體對應的位置(核心中該程序的棧空間)儲存起來,當切換回該程序時,需要從記憶體中拷貝回寄存器中。即上下文切換時,需要保護現場和恢複現場。
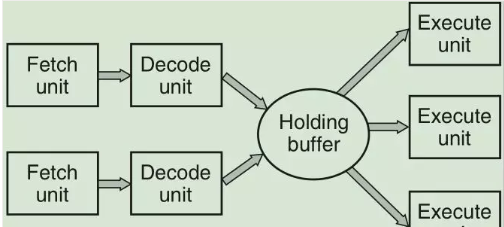
7、為了改善性能,CPU已經不是單條取指-->解碼-->執行的路線,而是分别為這3個過程分别提供獨立的取值單元,解碼單元以及執行單元。這樣就形成了流水線模式。
例如,流水線的最後一個單元——執行單元正在執行第n條指令,而前一個單元可以對第n+1條指令進行解碼,再前一個單元即取指單元可以去讀取第n+2條指令。這是三階段的流水線,還可能會有更長的流水線模式。
8、更優化的CPU架構是superscalar架構(超标量架構)。這種架構将取指、解碼、執行單元分開,有大量的執行單元,然後每個取指+解碼的部分都以并行的方式運作。比如有2個取指+解碼的并行工作線路,每個工作線路都将解碼後的指令放入一個緩存緩沖區等待執行單元去取出執行。
9、除了嵌入式系統,多數CPU都有兩種工作模式:核心态和使用者态。這兩種工作模式是由PSW寄存器上的一個二進制位來控制的。
10、核心态的CPU,可以執行指令集中的所有指令,并使用硬體的所有功能。
11、使用者态的CPU,隻允許執行指令集中的部分指令。一般而言,IO相關和把記憶體保護相關的所有執行在使用者态下都是被禁止的,此外其它一些特權指令也是被禁止的,比如使用者态下不能将PSW的模式設定控制位設定成核心态。
12、使用者态CPU想要執行特權操作,需要發起系統調用來請求核心幫忙完成對應的操作。其實是在發起系統調用後,CPU會執行trap指令陷入(trap)到核心。當特權操作完成後,需要執行一個指令讓CPU傳回到使用者态。
13、除了系統調用會陷入核心,更多的是硬體會引起trap行為陷入核心,使得CPU控制權可以回到作業系統,以便作業系統去決定如何處理硬體異常。
關于CPU的基本組成
1、CPU是用來運算的(加法運算+、乘法運算*、邏輯運算and not or等),例如c=a+b。
2、運算操作涉及到資料輸入(input)、處理、資料輸出(output),a和b是輸入資料,加法運算是處理,c是輸出資料。
3、CPU需要使用一個叫做存儲器(也就是各種寄存器)的東西儲存輸入和輸出資料。以下是幾種常見的寄存器(前文也介紹了一些)
MAR: memory address register,儲存将要被通路資料在記憶體中哪個位址處,儲存的是位址值
MDR: memory data register,儲存從記憶體讀取進來的資料或将要寫入記憶體的資料,儲存的是資料值
AC: Accumulator,儲存算術運算和邏輯運算的中間結果,儲存的是資料值
PC: Program Counter,儲存下一個将要被執行指令的位址,儲存的是位址值
CIR: current instruction register,儲存目前正在執行的指令
4、CPU還要将一些常用的基本運算工具(如加法器)放進CPU,這部分負責運算,稱為算術邏輯單元(ALU, Arithmetic Logic Unit)。
5、CPU中還有一個控制器(CU, Control Unit),負責将存儲器中的資料送到ALU中去做運算,并将運算後的結果存回到存儲器中。
控制器還包含了一些控制信号。
5、控制器之是以知道資料放哪裡、做什麼運算(比如是做加法還是邏輯運算?)都是由指令告訴控制器的,每個指令對應一個基本操作,比如加法運算對應一個指令。
6、例如,将兩個MDR寄存器(儲存了來自記憶體的兩個資料)中的值拷貝到ALU中,然後根據指定的操作指令執行加法運算,将運算結果拷貝會一個MDR寄存器中,最後寫入到記憶體。
7、這就是馮諾依曼結構圖,也就是現在計算機的結構圖。

關于CPU的多核和多線程
1、CPU的實體個數由主機闆上的插槽數量決定,每個CPU可以有多核心,每核心可能會有多線程。
2、多核CPU的每核(每核都是一個小晶片),在OS看來都是一個獨立的CPU。
3、對于超線程CPU來說,每核CPU可以有多個線程(數量是兩個,比如1核雙線程,2核4線程,4核8線程),每個線程都是一個虛拟的邏輯CPU(比如windows下是以邏輯處理器的名稱稱呼的),而每個線程在OS看來也是獨立的CPU。
這是欺騙作業系統的行為,在實體上仍然隻有1核,隻不過在超線程CPU的角度上看,它認為它的超線程會加速程式的運作。
4、要發揮超線程優勢,需要作業系統對超線程有專門的優化。
5、多線程的CPU在能力上,比非多線程的CPU核心要更強,但每個線程不足以與獨立的CPU核心能力相比較。
6、每核上的多線程CPU都共享該核的CPU資源。
例如,假設每核CPU都隻有一個"發動機"資源,那麼線程1這個虛拟CPU使用了這個"發動機"後,線程2就沒法使用,隻能等待。
是以,超線程技術的主要目的是為了增加流水線(參見前文對流水線的解釋)上更多個獨立的指令,這樣線程1和線程2在流水線上就盡量不會争搶該核CPU資源。是以,超線程技術利用了superscalar(超标量)架構的優點。
7、多線程意味着每核可以有多個線程的狀态。比如某核的線程1空閑,線程2運作。
8、多線程沒有提供真正意義上的并行處理,每核CPU在某一時刻仍然隻能運作一個程序,因為線程1和線程2是共享某核CPU資源的。可以簡單的認為每核CPU在獨立執行程序的能力上,有一個資源是唯一的,線程1擷取了該資源,線程2就沒法擷取。
但是,線程1和線程2在很多方面上是可以并行執行的。比如可以并行取指、并行解碼、并行執行指令等。是以雖然單核在同一時間隻能執行一個程序,但線程1和線程2可以互相幫助,加速程序的執行。
并且,如果線程1在某一時刻擷取了該核執行程序的能力,假設此刻該程序發出了IO請求,于是線程1掌握的執行程序的能力,就可以被線程2擷取,即切換到線程2。這是在執行線程間的切換,是非常輕量級的。(WIKI: if resources for one process are not available, then another process can continue if its resources are available)
9、多線程可能會出現一種現象:假如2核4線程CPU,有兩個程序要被排程,那麼隻有兩個線程會處于運作狀态,如果這兩個線程是在同一核上,則另一核完全空轉,處于浪費狀态。更期望的結果是每核上都有一個CPU分别排程這兩個程序。
關于CPU上的高速緩存
1、最高速的緩存是CPU的寄存器,它們和CPU的材料相同,最靠近CPU或最接近CPU,通路它們沒有時延(<1ns)。但容量很小,小于1kb。
32bit:32*32比特=128位元組
64bit:64*64比特=512位元組
2、寄存器之下,是CPU的高速緩存。分為L1緩存、L2緩存、L3緩存,每層速度按數量級遞減、容量也越來越大。
3、每核心都有一個自己的L1緩存。L1緩存分兩種:L1指令緩存(L1-icache)和L1資料緩存(L1-dcache)。L1指令緩存用來存放已解碼指令,L1資料緩存用來放通路非常頻繁的資料。
4、L2緩存用來存放近期使用過的記憶體資料。更嚴格地說,存放的是很可能将來會被CPU使用的資料。
5、多數多核CPU的各核都各自擁有一個L2緩存,但也有多核共享L2緩存的設計。無論如何,L1是各核私有的(但對某核内的多線程是共享的)。
【雲栖号線上課堂】每天都有産品技術專家分享!
課程位址:
https://yqh.aliyun.com/zhibo立即加入社群,與專家面對面,及時了解課程最新動态!
【雲栖号線上課堂 社群】
https://c.tb.cn/F3.Z8gvnK
原文釋出時間:2020-06-20
本文作者:網際網路架構師
本文來自:“
網際網路架構師 微信公衆号”,了解相關資訊可以關注“[網際網路架構師](
https://mp.weixin.qq.com/s/oUDJ7H7js2LpUMVzg5driA)