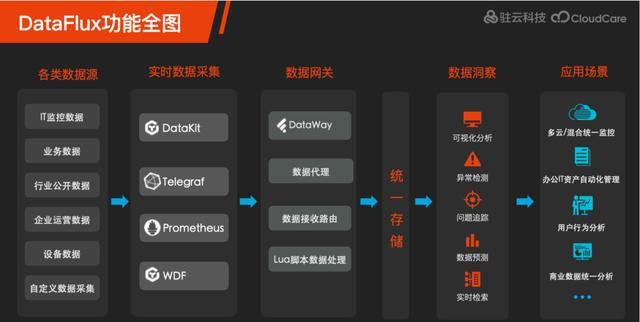
DataFlux是上海駐雲自研發的一套大資料統一分析平台,可以通過對任何來源、類型、規模的實時資料進行監控、分析和處理,釋放資料價值。
DataFlux包含五大功能子產品:
- Datakit 采集器
- Dataway 資料網關
- DataFlux Studio 實時資料洞察平台
- DataFlux Admin Console 管理背景
- DataFlux.f(x) 實時資料處理開發平台
使用 DataFlux 采集 Docker 監控名額并展示
面向企業提供全場景的資料洞察分析能力, 具有實時性、靈活性、易擴充、易部署等特點。
安裝DataKit
PS:以Linux系統為例
第一步:執行安裝指令
DataKit 安裝指令:
DK_FTDATAWAY=[你的 DataWay 網關位址] bash -c "$(curl https://static.dataflux.cn/datakit/install.sh)" 補充安裝指令中的 DataWay 網關位址,然後複制安裝指令到主機上執行即可。
例如:如果的 DataWay 網關位址 IP 為 1.2.3.4,端口為 9528(9528為預設端口),則網關位址為
http://1.2.3.4:9528/v1/write/metrics,安裝指令為:
DK_FTDATAWAY=http://1.2.3.4:9528/v1/write/metrics bash -c "$(curl https://static.dataflux.cn/datakit/install.sh)" 安裝完成後,DataKit 預設會自動運作,并且會在終端中提示 DataKit 的狀态管理指令

Docker 名額采集
采集 docker 名額上報到 DataFlux 中
-
已安裝 DataKit(DataKit 安裝文檔)
打開 DataKit 采集源配置檔案夾(預設路徑為 DataKit 安裝目錄的 conf.d 檔案夾),找到 docker 檔案夾,打開裡面的 docker.conf。
設定:
# Read metrics about docker containers
[[inputs.docker]]
## Docker Endpoint
## To use TCP, set endpoint = "tcp://[ip]:[port]"
## To use environment variables (ie, docker-machine), set endpoint = "ENV"
endpoint = "unix:///var/run/docker.sock"
## Set to true to collect Swarm metrics(desired_replicas, running_replicas)
## Note: configure this in one of the manager nodes in a Swarm cluster.
## configuring in multiple Swarm managers results in duplication of metrics.
gather_services = false
## Only collect metrics for these containers. Values will be appended to
## container_name_include.
## Deprecated (1.4.0), use container_name_include
container_names = []
## Set the source tag for the metrics to the container ID hostname, eg first 12 chars
source_tag = false
## Containers to include and exclude. Collect all if empty. Globs accepted.
container_name_include = []
container_name_exclude = []
## Container states to include and exclude. Globs accepted.
## When empty only containers in the "running" state will be captured.
## example: container_state_include = ["created", "restarting", "running", "removing", "paused", "exited", "dead"]
## example: container_state_exclude = ["created", "restarting", "running", "removing", "paused", "exited", "dead"]
# container_state_include = []
# container_state_exclude = []
## Timeout for docker list, info, and stats commands
timeout = "5s"
## Whether to report for each container per-device blkio (8:0, 8:1...) and
## network (eth0, eth1, ...) stats or not
perdevice = true
## Whether to report for each container total blkio and network stats or not
total = false
## docker labels to include and exclude as tags. Globs accepted.
## Note that an empty array for both will include all labels as tags
docker_label_include = []
docker_label_exclude = []
## Which environment variables should we use as a tag
tag_env = ["JAVA_HOME", "HEAP_SIZE"]
## Optional TLS Config
# tls_ca = "/etc/telegraf/ca.pem"
# tls_cert = "/etc/telegraf/cert.pem"
# tls_key = "/etc/telegraf/key.pem"
## Use TLS but skip chain & host verification
# insecure_skip_verify = false 配置好後,重新開機 DataKit 即可生效
驗證資料上報
完成資料采集操作後,我們需要驗證資料是否采內建功并且上報到DataWay,以便後續能正常進行資料分析及展示
操作步驟:登入DataFlux——資料管理——名額浏覽——驗證資料是否采內建功
Docker 名額:
使用DataFlux實作資料洞察
根據擷取到的名額項進行資料洞察設計,例如:
Docker 監控視圖
DataFlux基于自研的DataKit資料(采集器)目前已經可以對接超過200種資料協定,包括:雲端資料采集、應用資料采集、日志資料采集、時序資料上報、常用資料庫的資料彙聚,幫助企業實作最便捷的IT 統一監控。