Dialog Studio 是達摩院NLP-小蜜Conversational AI團隊研發的面向開發者的智能對話開發平台,目前已經在雲(多省市政務12345熱線、中移動10086、金融、醫療等)、釘釘(通過釘釘官方智能工作助理服務幾百萬企業)、集團内(淘寶優酷等十幾個BU)、淘寶天貓商家以及Lazada東南亞6國大規模應用。
為了應對疫情,基于 Dialog Studio 緊急開發的智能疫情外呼機器人,截止3月底,總共呼出了1600多萬通電話,幫助23個省篩查出了18萬健康異常的人員,對話完成率高達90%,在人民網“人民戰疫”大賽評為唯一的一等獎。
圍繞 Dialog Studio,我們有系列文章:
【1】
一個中心+三大原則 -- 小蜜這樣做智能對話開發平台 【2】 自然語言了解-從規則到深度學習 【3】 Few-shot Learning 最新進展 【4】 EMNLP 2019: 基于 Few-shot learning 的對話意圖識别 【5】 Dialog Studio - 新一代智能對話開發平台 【6】 對話使用者模拟器最新進展 【7】 小蜜團隊萬字長文:對話管理模型最新研究進展 【8】[ACL 2020: 基于元學習和人機協同的端到端對話模型]()1. 背景
端到端對話模型近幾年得到了學術界和工業界的廣泛關注(詳見可參考
《小蜜團隊萬字長文:對話管理模型最新研究進展》),相比 pipeline 式的對話系統,端到端對話系統可以直接利用對話日志進行訓練,不需要人工設計特定的語義标簽,是以更具備可擴充性。 我們在 Dialog Studio 上已經實作了端到端的對話模型,并且在政務、疫情等業務中落地應用。一個省信訪外呼對話例子如下:
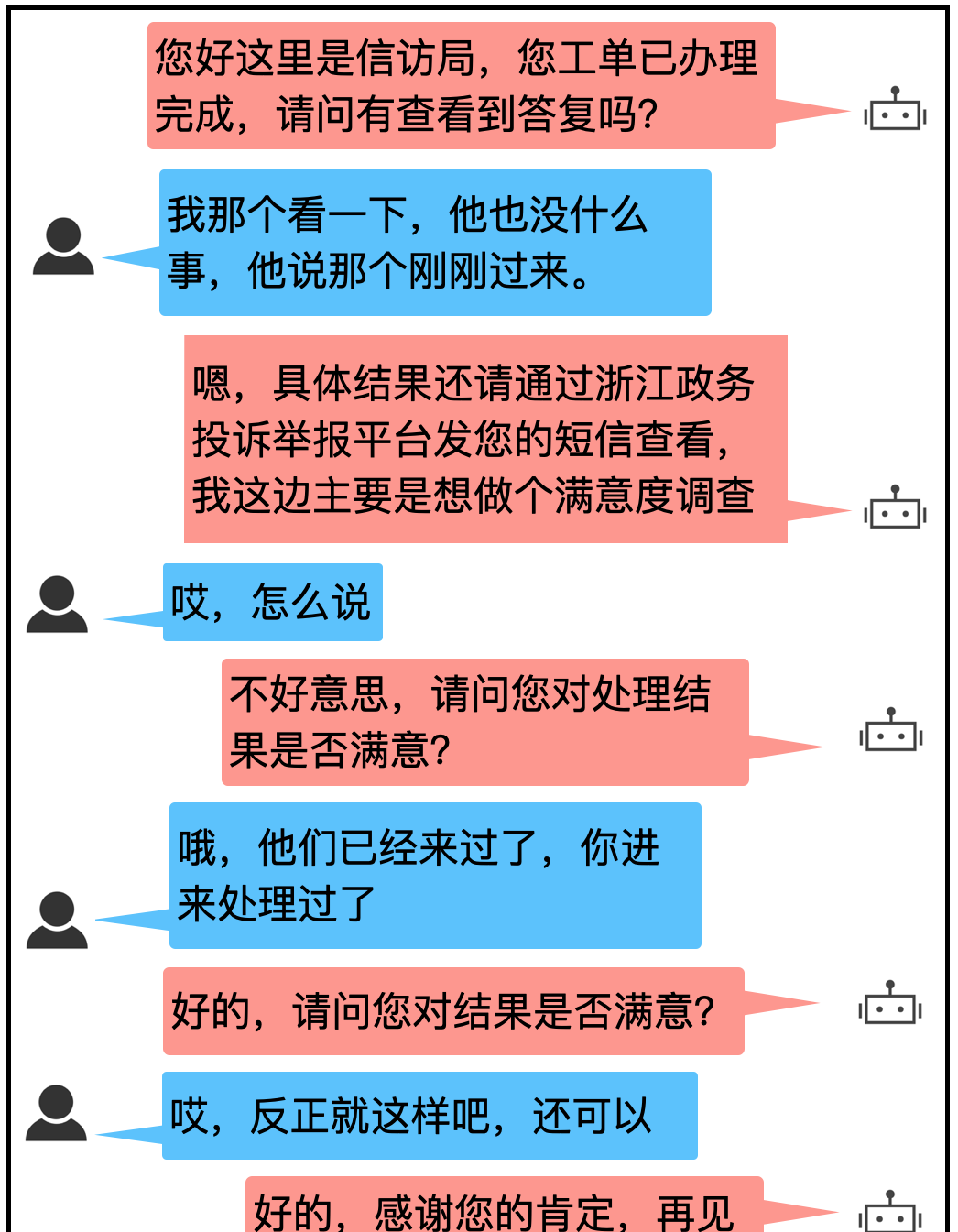
上述例子是一個滿意度回訪調查的場景,由于沒有複雜的知識推理、語義解析等,是端到端對話系統特别适用的場景。一般來說,端到端對話模型可分為檢索式和生成式,檢索式模型就是給定對話曆史從預定義回複候選集合中選出最佳回複作為目前系統輸出,生成式模型則是給定對話曆史直接生成回複。兩種方式都可以通過和使用者多輪互動完成最終的對話任務。
然而,盡管端到端對話模型簡單易用,但是在實際應用中仍然面臨着兩大常見問題:
- Data Scarcity Problem:端到端模型一般需要大量的訓練資料,且場景越複雜,需求越大。在雲小蜜 Dialog Studio 中的ToB 的業務,不少新場景一開始是沒有可用的高品質對話日志的,比如我們已經在政務12345 場景 和 114 移車場景上積累了大量的對話,可以當我們做省信訪外呼場景時,一開始隻有很少的對話可以使用。是以如何利用已有場景的豐富資料訓練一個端到端模型,使其可以快速遷移到缺少資料的新場景上是一個很大的挑戰。

ACL 2020: 基于元學習和人機協同的端到端對話模型1. 背景2. 技術方案3. 實驗結果4. 總結和展望參考文獻 - Covariate Shift Effect:有限的離線訓練資料和真實的線上測試資料之間存在資料分布的差異性,會導緻系統線上表現不佳,和離線測試效果不比對,這種差異性主要來自于未見的使用者行為(例如:新槽值、新意圖、複雜句等)。例如下圖中,訓練資料中從未出現過“喂,内容是什麼?我忘了回報什麼了” 類似的使用者語句,一旦真實上線,模型很容易預測出錯誤的結果,進而影響使用者體驗。尤其是當資料量少的時候,模型對于線上資料的魯棒性會進一步下降。是以如何解決線上線下資料不比對,提高端到端對話模型的魯棒性是另一大挑戰。
實際上,在雲小蜜的業務中,不少場景都存在訓練資料少的問題,而客戶又需要我們的對話系統能夠達到可直接上線的标準。是以綜合來看,我們希望提出一種新的對話系統以及對應的訓練方法,能夠兼具備面對新場景的快速适應性 (fast adaptability)和穩健的線上表現 (reliable performance),能夠在低訓練資源下依舊能夠保證較好的線上效果。 ACL 2020: 基于元學習和人機協同的端到端對話模型1. 背景2. 技術方案3. 實驗結果4. 總結和展望參考文獻 2. 技術方案
通過前期調研我們發現,應對資料少的問題的常用方法有元學習、資料增強等,應對訓練和測試對話資料不一緻的問題的常用方法有人機協同[1]、線上學習[2]等。最終我們選擇将元學習(meta-learning)方法和人機協同(human-machine collaboration)方法結合,提出了元對話系統(Meta-Dialog System, MDS):利用元學習,系統能夠在少量訓練資料上進行快速學習,解決 Data Scarcity Problem;利用人機協作,模型可以在對話中請求人工客服幫助,以保證系統達到可接受的線上水準,降低 Covariate Shift Effect。相關成果已經發表至 ACL2020 [3],該系統有望在有輔助人工客服且缺資料的新場景中得到應用。2.1 問題定義
由于回複内容可控,我們采用檢索式端到端對話模型,該對話任務是一個分類任務:給定預定義的回複候選集,基于對話曆史選擇正确回複。如下圖所示,模型一般包含: 1)曆史編碼器(History encoder) ,對整個對話曆史進行編碼提取對話狀态向量,常見模型有 MemN2N,Hierarical RNN 等 ;2)回複編碼器 (Response encoder),對每個回複進行編碼提取句向量;3)預測器,根據對話狀态向量和回複句向量判斷出正确的回複,通常就是計算餘弦相似度給出。而在人機協同的架構下,端到端對話模型會多出一個判決器子產品,用于判定目前對話是否轉人工,如果轉人工則交給人工客服解答,否則模型自己給出答案。如下圖所示: ACL 2020: 基于元學習和人機協同的端到端對話模型1. 背景2. 技術方案3. 實驗結果4. 總結和展望參考文獻 ACL 2020: 基于元學習和人機協同的端到端對話模型1. 背景2. 技術方案3. 實驗結果4. 總結和展望參考文獻 2.2. 模型詳解
我們沿用了上述的模型結構 [1],但是在每個子產品和訓練方法上都進行的改進創新。整個 MDS 的架構如下:和 [1, 4] 一緻,對于曆史編碼器我們采用了一個 MemN2N 模型,對于回複編碼器我們使用了一個簡單的詞向量相加的句向量。模型預測器的部分,我們選擇了large margin cosine loss [7] 作為損失函數 $\mathcal{L}_{LMC}$,因為它可以學習更有鑒别性的特征(discriminative features)。針對請求人工的判決器,我們在 [1] 的基礎之上提出了一個新的 reward 設定,使用增強學習來進行優化 $\mathcal{L}_{RL}$。最終,我們使用 MAML [5] 方法對 $\mathcal{L} = \mathcal{L}_{RL} + \mathcal{L}_{LMC}$ 進行聯合優化,幫助模型找到一組合适的參數,使得預測器和判決器一起快速适應新場景。 ACL 2020: 基于元學習和人機協同的端到端對話模型1. 背景2. 技術方案3. 實驗結果4. 總結和展望參考文獻 2.2.1. Learning to Switch
設第 $i$ 個資料為 $d_i$, 該對話狀态向量為 $s_i$, 回複候選集為 $\mathcal{R}$, 每個回複的句向量設為 $r_k$, 判斷器的輸出整體考慮了 $s_i$ 的資訊以及它和各個 $r_k$ 的 attention 資訊,具體計算如下: ACL 2020: 基于元學習和人機協同的端到端對話模型1. 背景2. 技術方案3. 實驗結果4. 總結和展望參考文獻 $\sigma$ 是 sigmoid function, $FC(\cdot)$ 是一個全連接配接網絡,$W$ 是個 trainable matrix。得到判決器的預測結果後,我們需要設計合适的 reward 使用增強學習來優化。直覺來看,一個理想的判決器應當是模型預測錯時多轉人工,模型預測對時少轉人工,這樣就能保證整體的轉人工率低,且整體 turn ACC (請求人工也算對)高。
reward 設定:設一個batch data 為 $mathcal{D}={d_1, d_2, ...,d_i, ...}$, 我們将模型預測錯誤的 $d_i$ 設為正樣本(label=True), 預測正确的設為負樣本 (label=False), 判決器判斷轉人工的資料設為預測正樣本( prediction=True), 判斷不轉人工的設為預測負樣本(prediction=False), 然後計算出正樣本和負樣本的 F1 score,再取平均得到整個 batch 的 得分 $score(\mathcal{D})$, 其中每個資料 $d_i$ 配置設定到的 reward $r_i=score(\mathcal{D})-score(\mathcal{D}-d_i)$。 RL 的優化我們選擇 policy gradient method。
2.2.2. MAML 訓練
得到整體的損失函數 $\mathcal{L} = \mathcal{L}_{RL} + \mathcal{L}_{LMC}$ 後,我們采用 MAML 算法優化整個模型。
首先需要構造元任務 (meta-task),步驟如下:
- 采樣 K 個對話場景 (每個場景對應一個對話任務)
- 每個對話任務,采樣 N 個對話資料作為支撐集(supoort set),N 個資料作為問詢集(query set)
ACL 2020: 基于元學習和人機協同的端到端對話模型1. 背景2. 技術方案3. 實驗結果4. 總結和展望參考文獻 3. 實驗結果
為驗證模型在新場景的遷移能力,我們需要多場景的端到端對話資料集。在評估時,依次選取一個場景作為目标場景,剩餘的作為訓練場景,利用 MAML 預訓練模型,meta trainning 完畢之後, 再在目标場景上進行小樣本的遷移實驗。最終結果是每個場景去平均後得到。3.1. 資料集構造
3.1.1 Extended-bAbI
原始的 bAbI [4] 因為是單場景的對話,且初步實驗效果發現将其中的 Task1-5 作為元任務效果不佳。是以我們仿造 bAbI 模拟生成了一個更大的多場景端到端資料集稱作 extended-bAbI。包含場景有餐館、機票、酒店、電影、音樂、旅遊、天氣等 7 個場景,每個場景的訓練集/開發集/測試集為 1500/500/1000 個完整對話。 音樂和天氣場景的兩個對話例子如下所示: ACL 2020: 基于元學習和人機協同的端到端對話模型1. 背景2. 技術方案3. 實驗結果4. 總結和展望參考文獻 3.1.2. MultiWOZ
MultiWOZ [6] 是最近提出的大型任務對話資料集,也可以用于進行模型評估。為了将 MultiWOZ 簡化成 bAbI 對話任務,我們隻使用包含 single-domain 的對話,并且進行去詞彙化,利用 dialog label 将槽值替換成特定 token,再将 dialog act 進行一定的規整,最終得到端到端對話資料。一個對話例子如下所示。 ACL 2020: 基于元學習和人機協同的端到端對話模型1. 背景2. 技術方案3. 實驗結果4. 總結和展望參考文獻 3.2. Baselines
- $\textbf{Mem}$: 利用 MLE 訓練的一個 MemN2N 模型。
- $\textbf{MetaMem}$: 利用 MAML 訓練的 一個 MemN2N 模型。$\textbf{MetaMem}$ 和 $\textbf{Mem}$ 都沒有請求人工的判決器。
- $\textbf{Mem+C}$:論文[1] 的人機協同模型。該模型的訓練準則和損失函數和我們都不一樣。
- $\textbf{IDS}$:論文[8] 提出的 incremental dialog system, 該模型的判決器是一個變分自編碼器,通過估計對話的不确定性來判斷是否請求人工。
- $\textbf{MDS}_\text{-switch}$: MDS 去掉判決器部分。
- $\textbf{MDS}_\text{mle}$: MDS 保持模型一緻,但是訓練方法采用 MLE。
- $\textbf{MDS}_\text{rand}$: MDS 的判決器替換成一個 請求人工率一緻的 random classifier,
3.3. 實驗結果和分析
在extended-bAbI 上的結果如下表所示: ACL 2020: 基于元學習和人機協同的端到端對話模型1. 背景2. 技術方案3. 實驗結果4. 總結和展望參考文獻 request 是請求人工率,accuracy 是含轉人工的整體 turn ACC,即轉人工或模型預測正确均算對。
可以看到,MDS 的表現優于所有的基線模型,平均在新場景上僅需 10 個對話就可以達到 90% 以上的turn ACC。 使用請求人工的判決器的模型顯著好于不使用或者使用random判決器的模型,說明人機協同架構在提高模型整體表現起到重要作用。利用元學習的模型相比不使用元學習的模型,在效果上也有穩定的提高。
MultiWOZ 上的實驗結果如下表所示:
由于MultiWOZ是真實的人人對話,是以所有模型的表現都有合理的下降,但是 MDS 相比其他模型依然有明顯的優勢,在請求人工率相近的情況下有更高的 turn ACC。 ACL 2020: 基于元學習和人機協同的端到端對話模型1. 背景2. 技術方案3. 實驗結果4. 總結和展望參考文獻 4. 總結和展望
本文主要介紹了如何結合 元學習方法 和 人機協同 方法 提高端到端對話模型在新場景上的快速适應能力和預測效果。對于元學習方法,我們采用了 MAML 算法,在多場景的對話資料集上進行實驗。實驗表明,利用 MAML 可以很好地幫助模型的判決器和預測器一起找到合适的初始化參數,以更快地遷移到新的場景中去。未來,我們将探索利用更強大的編碼模型(如 BERT),更好的 reward 設計,并把我們的元學習對話系統落地到雲小蜜的真實業務中去。參考文獻
[1] Rajendran J, Ganhotra J, Polymenakos L C. Learning End-to-End Goal-Oriented Dialog with Maximal User Task Success and Minimal Human Agent Use. ACL, 2019.
[2] Liu B, Tur G, Hakkani-Tur D, et al. Dialogue learning with human teaching and feedback in end-to-end trainable task-oriented dialogue systems. NAACL, 2018.
[3] Dai Y, Li H, et al. Learning Low-Resource End-To-End Goal-Oriented Dialog for Fast and Reliable System Deployment. ACL, 2020. (to be appeared)
[4] Bordes A, Boureau Y L, Weston J. Learning end-to-end goal-oriented dialog. ICLR, 2016.
[5] Finn C, Abbeel P, Levine S. Model-agnostic meta-learning for fast adaptation of deep networks. ICML, 2017.
[6] Eric M, Goel R, Paul S, et al. Multiwoz 2.1: Multi-domain dialogue state corrections and state tracking baselines[J]. arXiv preprint arXiv:1907.01669, 2019.
[7] Lin T E, Xu H. Deep unknown intent detection with margin loss[J]. ACL, 2019.
[8] Wang W, Zhang J, Li Q, et al. Incremental learning from scratch for task-oriented dialogue systems. ACL, 2019.