AI-DSW 上編輯嵌套式模型實作Resnet手勢識别
AI-DSW(Data science workshop)是專門為算法開發者準備的雲端深度學習開發環境,
進入DSW,目前隻有KerasCode和KerasGraph兩個Kernel實作了FastNeuralNetwork功能。
- KerasCode:先寫深度學習網絡代碼,然後将代碼轉成圖
- KerasGraph:直接通過畫布建構深度學習網絡,并且将圖轉成代碼
接下來我們通過實作Resnet18實作手勢識别為例,體驗AI-DSW的使用
我們的任務為,手語英文字母資料集中包含用手語表示的26個英文字母的資訊,我們通過建立ResNet18模型進行手語英文字母識别
在AI-DSW 的官方文檔中推薦我們采用序貫式(sequential)的方式構模組化型,但是嵌套式封裝來構模組化型可以使結構更清晰,一些内容可以複用,我們來具體看下代碼:
def Conv2d_BN(x, nb_filter, kernel_size, strides=(1, 1), padding='same'):
x = Conv2D(nb_filter, kernel_size, padding=padding, strides=strides)(x)
x = BatchNormalization(axis=3)(x)
x = Activation('relu')(x)
return x 首先我們将最常見的CNN子產品封裝,包括卷積,BN,激活函數;用于Resnet模型的複用;
def identity_Block(inpt, nb_filter, kernel_size, strides=(1, 1), with_conv_shortcut=False):
x = Conv2d_BN(inpt, nb_filter=nb_filter, kernel_size=kernel_size, strides=strides, padding='same')
x = Conv2d_BN(x, nb_filter=nb_filter, kernel_size=kernel_size, padding='same')
if with_conv_shortcut:#shortcut的含義是:将輸入層x與最後的輸出層y進行連接配接,如上圖所示
shortcut = Conv2d_BN(inpt, nb_filter=nb_filter, strides=strides, kernel_size=kernel_size)
x = add([x, shortcut])
return x
else:
x = add([x, inpt])
return x 接下來我們實作Resnet用于Residual Block的子產品,即殘差塊,基于殘差塊可以有效提升網絡性能,提升模型泛化能力,如圖所示:
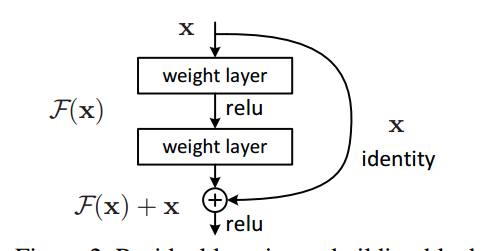
有了核心子產品後,我們可着手搭模組化型的核心結構,包括輸入,卷積,殘差,池化,全連接配接,輸出等一系列步驟
def resnet_18(width,height,channel,classes):
inpt = Input(shape=(width, height, channel))
# x = ZeroPadding2D((3, 3))(inpt)
#conv1
x = Conv2d_BN(inpt, nb_filter=64, kernel_size=(7, 7), strides=(2, 2), padding='valid')
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), padding='same')(x)
#conv2_x
x = identity_Block(x, nb_filter=64, kernel_size=(3, 3))
x = identity_Block(x, nb_filter=64, kernel_size=(3, 3))
#conv3_x
x = identity_Block(x, nb_filter=128, kernel_size=(3, 3), strides=(2, 2), with_conv_shortcut=True)
x = identity_Block(x, nb_filter=128, kernel_size=(3, 3))
#conv4_x
x = identity_Block(x, nb_filter=256, kernel_size=(3, 3), strides=(2, 2), with_conv_shortcut=True)
x = identity_Block(x, nb_filter=256, kernel_size=(3, 3))
#conv5_x
x = identity_Block(x, nb_filter=512, kernel_size=(3, 3), strides=(2, 2), with_conv_shortcut=True)
x = identity_Block(x, nb_filter=512, kernel_size=(3, 3))
x = GlobalAvgPool2D()(x)
x = Dense(classes, activation='softmax')(x)
model = Model(inputs=inpt, outputs=x)
return model 在 DSW的官方介紹
https://www.alibabacloud.com/help/zh/doc-detail/126303.htm采用的是序貫式來做模型展示,這裡我們發現,基于嵌套式政策同樣可以做生成模型結構,如圖所示:

同樣的,我們按照官方文檔介紹的,也可做模型可視化編輯,調整參數等
有了模型後,我們定義損失函數,加入訓練集驗證集來訓練優化模型,最終得到結果。
綜上,體驗了KerasGraph後,個人感覺它代表了最新的ai開發環境演進方向——類似輕代碼(low code)編輯器,可以快速構模組化型結構并驗證模型效果,提升了我們對模型結構的實作效率,避免糾結與在TF過于繁瑣的源碼,而是Focus在模型結構優化本身,總體來說還是不錯的。
當然KerasGraph目前使用也存在一些問題:
- 暫不支援各類預訓練模型,比如keras_bert,resnet這些,不過在支援了預訓練模型,甚至支援對預訓練模型最後幾層做編輯,将大大提升實用性
- KerasGraph圖形化界面前端占用過多記憶體,有的時候會導緻頁面卡塞
- KerasGraph對于各層參數編輯和定義易用性還需要提升,目前并不比查閱文檔友善多少
當然這不妨礙KerasGraph已經是個較為出色的模型展示工具,我也相信假以時日KerasGraph在模型編輯上取得突破