雲栖号資訊:【 點選檢視更多行業資訊】
在這裡您可以找到不同行業的第一手的上雲資訊,還在等什麼,快來!
有人說世界上有三個偉大的發明:火,輪子,以及 Kafka。
發展到現在,Apache Kafka 無疑是很成功的,Confluent 公司曾表示世界五百強中有三分之一的企業在使用 Kafka。實時備份機制讓它在推薦、廣告等網際網路場景中遊刃有餘,但是實際生産中還有很多不允許丢資料的場景存在。針對這類場景是否有新的技術和架構出現?
Kafka:大資料平台中的核心軟體
據中國信通院企業采購大資料軟體調研報告來看,86.6% 的企業選擇基于開源軟體建構自己的大資料處理業務,但大資料人都會感歎大資料領域開源項目的“玲琅滿目”。很多軟體隻經過一兩年就形成一次更替,經過多年的厮殺和競争,很多優秀的産品已經脫穎而出,也有很多産品慢慢走向消亡。比如 Spark 基本上已經成為批處理領域的佼佼者, Flink 成為了低延遲流處理領域的不二選擇,而 Storm 開始慢慢退出曆史舞台。 Kafka 在消息中間件領域基本上占據了壟斷地位,最終沉澱出了以這幾個軟體為核心的大資料處理平台。
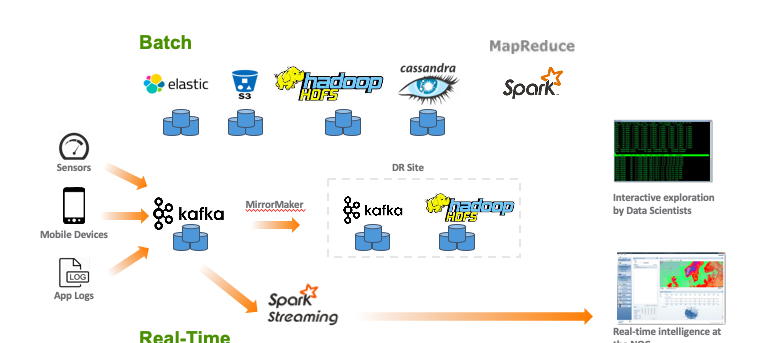
那麼現在的大資料架構下的底層生态已經足夠成熟來幫助企業使用者進行數字轉型嗎?哪些地方還存在優化的空間?
同為開源資料管道,卻有不同命運。
回到 7 年前,Kafka 也肯定想不到自己會在大資料系統中起到這麼重要的作用。2010 年, LinkedIn 開始研發 Kafka,最初的設計理念非常簡單,就是一個以 append-only 日志作為核心的資料存儲結構。2011 年的時候,Kafka 提出了一個叫做 ISR 實時備份清單的機制,來保證高可用性。
運作過 Kafka 大規模叢集的人都知道,Kafka 裡面有很多資料持久化的問題。在一些早期版本中或者沒有選擇正确配置時,如果一個伺服器失敗(這在分布式系統裡很常見),就會導緻這個伺服器端所存的資料在恢複之前無法再被取得,更有甚者,這些資料有可能就永遠丢失了。僅僅作為一個日志系統,這也許是可以勉強接受的。但是當越來越多企業開始使用 Kafka 來傳輸和儲存重要商業資料,沒有高可用性是不行的。是以在引入了多備份機制之後,Kafka 脫穎而出,成為了當時整合流資料傳輸的集中式通道的首選,并慢慢進化出了強大的社群生态。
但企業采用 Kafka 之後,依然需要踩很多坑。為了應對多租戶、支撐上百萬 Topics 等要求,雅虎研發了新一代消息平台 Pulsar,并且在設計上采用了資料服務和資料存儲分層的架構。2016 年雅虎将這套軟體進行了開源,當時有人感慨:“如果 Pulsar 早推出兩年,也許就沒 Kafka 什麼事兒了。“
對比 Pulsar,Kafka 的先發優勢非常明顯,在強大的社群支撐下,Kafka 背後的公司 Confluent 不斷獲得融資,估值高達 25 億美元。但是 Pulsar 背後的公司 Streamlio,發展卻不那麼順利,沒幾年就被 Splunk 以人才收購的方式合并到一起了。關于開源軟體的商業模式很難用一兩句話讨論清楚,但 Pulsar 一開始的目的是想做“更好的 Kafka”,它在技術上可以認為是成功的,并且是值得被借鑒和被采用的。
也就是在 Pulsar 開發的同時,戴爾科技集團的研發團隊發現做一個更好的消息隊列 /Kafka 并不能解決新一代大資料平台在資料存儲層上的挑戰,是以他們重新思考了資料處理和存儲的規則,設計并開源了全新流存儲”Pravega”項目(
https://github.com/pravega)。通過一個全新的“stream”存儲抽象層,Pravega 讓上層計算引擎能更好和無縫去跟底層存儲解耦:“所有計算機領域的問題,都可以通過增加一個額外的中間層抽象解決”。
一套新的開源大資料平台

“Steam is the new file system for continous data."
有了 Pravega 提供的存儲層以後,大資料架構将會變成如上圖右側所示,并帶來以下改變:
1.在整個流水線中,無論有多少計算處理單元,原始的資料隻會被儲存一份。
2.不再需要根據資料的“時間”屬性去選擇不同的處理流水線 (streaming or batch),可以同時對實時和曆史資料的聚合做低延時的實時處理。
3.計算處理邏輯統一,降低應用開發難度。
為了詳細解釋這三點,我們可以先用下表來簡單對比一下 Pravega 和 Kafka 設計哲學的不同之處,這也代表了流存儲和消息隊列的本質差異:
接下來我們可以就第一點再展開,以了解新系統的優勢:
“資料無價,而計算可以重試”, 在左邊使用 Kafka+Spark/ES 的大資料技術棧中,很多企業為了保證資料不丢失,必然對重要(甚至所有的)的資料進行 3 拷貝落盤的設定。一份 topic,在 Lamda 架構下,從 Kafka 到離線、實時計算上要形成至少 6 個拷貝。再加上多資料中心,比如說 2-3 個站點,那麼一個 topic 就至少形成 12-18 個拷貝。而現在每天産生 PB 級别資料的企業不在少數,那就意味着這些副本也需要 PB 級别的資源去存儲,成本相當昂貴。
而在 Pravega+Flink 這套技術棧下,Pravega 是一個抽象的存儲接口,在這個流水線上所有的原始資料隻被存儲一份,然後将資料寫到持久存儲層如對象存儲或 HDFS。并且如果選用支援高效 EC 糾錯碼的商業分布式存儲作為 Pravega 的 long term storage,在保證資料的高可用高可靠性的情況下,對比 Kafka,就節省掉了相當多的資料存儲開銷。當企業的資料量達到 10+PB 級别後,Pravega/Flink + 商業存儲模式遠比完全使用開源軟體自建要省錢的多。
在接受 InfoQ 的采訪時,戴爾科技中國研發集團滕昱解釋完這套産品後表示:“我認為,下一個十年企業使用者真正需要的大資料平台就應該是這個樣子的。“
大資料平台的幾個發展方向
開發人員也需要有一個“整體”的商業思維。
豐富的開源項目能讓一個大資料系統的初始搭建變得簡單,Kafka+Spark/Flink 的 Lambda 架構已經很普遍,一定程度上降低了技術的入門門檻。但一個企業裡的端到端方案,并不是簡單的堆積一些大資料産品元件,使用者需要的也不是 Hadoop、Spark、Flink、Kafka 等這些技術,而是要以這些技術為基礎的能解決業務問題的一套完整的産品方案。
現在很多國内的企業,将建設一套解決方案的事情上升到了組織架構層面,形成各種部門,有叫大資料的,有叫基礎架構的,有的專門管存儲,有的專門管計算…每個部門各司其職,各自負責尋找各自的“局部最優解”,比如用 Kafka 的大資料部門就覺得把 Kafka 做好就行了。但是比單個技術應用更重要的,是企業還需要整體去考慮規模化應用、運維管控和成本優化方面的事情。隻有把整套架構放到一起,做好優化,同時考慮整體成本,才更具有優勢。比如管存儲的部門的 KPI 可能是基于有多少資料量來考慮的,那麼做一個統一存儲層的動力自然不足,但是這從整個公司角度來看其實是有問題的。
“做分布式存儲遠比做分布式計算更難。”
在一套大資料技術棧下,從資料采集到計算,到存儲,再到底層的基礎設施,最難的往往是存儲相關的這一塊。
所謂的數字化資産,就是企業儲存下來的原始資料。對于有價值的資産,在資料安全性上是不允許有閃失的。大家可以很清楚的發現,相對于計算架構的百花齊放,開源分布式存儲項目上其實一直處于“不堪大用”的地步。因為任何軟體都有 bug,當存儲産品出現 bug 的時候,開源模式就決定了無法找到一個 24*7 的響應模式來幫助客戶 fix DU/DL 的支援團隊,這其實是沒有任何企業使用者可以接受的。是以你會發現,到最後就變成了自建團隊維護自己專屬分支的結局,想想 Ceph 的曆史上有多少 bug 已經無人問津的現實吧, Ceph 官方的做法是設計一個新的存儲引擎去挖新坑。
未來企業資料量隻會越來越大,當超過 EB 級别以後,現有開源的存儲産品都會有一些基本設計上的問題,即使它們的架構圖是那麼“完美”。而商業存儲産品在 2013-2014 年就已經達到 2-3EB 單個系統的體量,這種積累其實是開源存儲産品很難在短時間跟上的。是以當資料量達到一定程度後,所有企業都需要去平衡技術和商業。
這也是 Pravega 被推出的一個重要原因,用開源技術連接配接底層存儲和開源計算,解決“成本”問題。在項目啟動早期,仍然可以使用 HDFS/Ceph/ 公有雲去“試水”, 正式進入商業以後,可以使用商業分布式存儲和公有雲存儲混布的架構,在滿足上層計算完全通過 Pravega 的抽象通路資料無需更改的前提下,使用者可以根據自己數字資産特性去自由地在公有雲和商業雲原生存儲平台之間動态遷移,畢竟公有雲存儲對于絕大部分企業使用者來說實在太昂貴了。
“技術當然很重要,但更重要的是順應技術趨勢去思考未來發展。”
從 2012 年開始,Mesos 的流行、Docker 的興起,然後 Kubernetes 出現并一舉打敗 Yarn 和 Mesos,到現在整個基礎架構正在全面往雲原生方向發展。
另一方面,雖然公有雲廠商總是宣傳讓大家“全面上雲”,但是除了對公有雲存儲成本的擔憂之外,企業使用者更加擔心的是資料鎖定(Lockdown)隐患。尤其是沒有人能保證公有雲廠商不會進入自己的商業領域,企業必須選擇将自己最看重的資料資産放到自己能掌控的硬體環境下或者是更靠近資料産生的邊緣端。是以未來的大趨勢必然以混合雲多雲的方式為主。這也是為什麼雲原生存儲對企業使用者有吸引力,因為它和上面的趨勢是契合的。
雲原生最重要的一個隐含意義就是做到端到端的存儲計算動态可伸縮性。當負載增大時,負責這條流水線的底層架構可以自動感覺變化并進行合理排程,并且是在沒有 DevOps 人為幹預的前提下。而當負載變小後,又可以動态釋放多餘資源給系統中其他流水線使用,如下圖所示。這樣可以在最大程度上榨幹硬體資源每一份能力。
面向傳統企業,開源需做出改變
“一切人類活動都是經濟活動,軟體開發也不例外”。
AWS 曾表示:公有雲至今隻轉移了世界上 3% 的 Workload,另外 97% 仍然還是傳統的企業開發。
這 97% 的存量 ToB 市場跟網際網路企業有着很不一樣的商業模式,主要表現在以下幾點:
第一,這不是一個“從 0 到 1”的市場。這些傳統企業往往在本領域已經是頭部,它們的營收一般在百億美元以上,每年的增長可能隻有 10%-20%。在它們選擇新技術時候,一個 3-4 年的 TCO(Total Cost of Ownership 總擁有成本)往往是其 COO 首先考慮的名額。那麼他 / 她必然要在公有雲的“彈性”和“昂貴”中作出取舍,更不說上面提到的 Lockdown 的商業風險。
一般網際網路企業喜歡的是全新的颠覆性的市場,用全新打法來追求爆炸性的增長率。對比網際網路企業,傳統企業自然在技術上取舍上會不一緻。“先有再演化”的開源軟體自然是不二選擇。隻是随着整體的經濟形式變化,每個今天的新興企業都有可能成為明天的成熟行業。 他們同樣會面臨技術使用上對成本的整體考慮,比如最近兩年就出現了從 AWS 等公有雲存儲回歸私有商業存儲的“歸隊”趨勢。
第二,垂直細分領域在企業開發中相當常見。不同領域有不同的需求,比如在遠洋運輸和石油鑽井平台行業中,網絡連接配接甚至都不是一個“必選項”,那麼其實也就不存在一個能滿足所有行業的開源項目。更多是需要在了解這些領域挑戰得前提下,有商業化支援的雲原生存儲計算的混合雲方案。
另外一個例子是在很多金融公司和銀行裡面,對安全的标準往往是實體隔離或者是多年行業形成的一系列規範。絕大部分的開源軟體其實完全沒有考慮或者也沒法考慮這類要求,必須借助商業軟體才能完成。比如戴爾科技集團在基于 Pravega+Flink 的 Streaming data platform 上就加入了基于 K8S 的全棧安全特性支援,并且作為預設設定。
第三,在實踐中,“ToB”和“ToC”另一個巨大的不同點在于技術方案不再由單個人來評估好壞,更多是一個企業決策者群體共同的決定結果。而這個群體裡面每個決策者,又會因為各自代表利益的不一樣,需要從很多非技術的角度去考慮。這甚至造成了企業開發中“慢速靈活”的現狀,穩定和相容性的要求遠大于新功能和快速試錯的要求。
很多企業甚至表示,“我們不需要一周一個新版本”。因為光是協調更新線上系統的批複流程都需要 1-2 周,一個月一次的 bug fix 更新已經足夠靈活,6-8 個月的大版本更新也“足夠好”,但是向後相容是必須要保證的,而這在開源軟體中往往很難做到。業界最好的例子莫過于 Intel 的 CPU 指令集,為了最大程度的保證向後相容,x86 不得不一直維護着一些很古老的指令來保證所有的使用者都不會因為新 CPU 造成上層程式的相容出錯。
滕昱說:“這就是企業開發的特點,和市場每年以 300% 甚至 500% 的速度快速膨脹的網際網路企業本質上并不一樣。隻不過經過 10 年高速發展之後,大家終于開始把目光投向了這些巨大的存量企業市場。而這個時候,我們所有的技術,包括開源項目和雲技術,都要做出一些相應的商業上的調整,才能抓住這些使用者的心和市場(real money) 。”
嘉賓介紹:
滕昱,現就職于 戴爾科技集團并擔任軟體開發總監。負責分布式對象存儲 ECS(Elastic Cloud Storage) 以及基于開源 Pravega 項目的新一代大資料分析平台的研發工作。滕昱于 2007 年加入 戴爾易安信 以後一直專注于分布式存儲領域,先後參與上司了戴爾易安信中國研發團隊在前後兩代對象存儲産品中的核心研發工作并取得商業成功。他正在積極擁抱新的邊緣 / 混合雲 / 多雲和實時流處理時代的到來,為企業使用者提供下一代大資料平台而努力完善整個生态系統的建構。
【雲栖号線上課堂】每天都有産品技術專家分享!
課程位址:
https://yqh.aliyun.com/zhibo立即加入社群,與專家面對面,及時了解課程最新動态!
【雲栖号線上課堂 社群】
https://c.tb.cn/F3.Z8gvnK
原文釋出時間:2020-05-12
本文作者:Tina
本文來自:“
InfoQ”,了解相關資訊可以關注“
”