實際處理和解決機器學習工程化問題過程中,我們很難通過單點完成機器學習模型的訓練。這些場景包括線上推薦,CTR預估,Lookalike營銷等,當有上億條資料,上千上萬維特征,這些應用涉及到的資料量在10G以上甚至TB級别,那麼該如何基于海量資料來訓練模型呢?
增量學習與特征選擇
增量學習
增量學習即使用小batch的資料中進行學習(有時候也稱為online learning)是這種學習方式的核心,因為它能讓任何一段時間内記憶體中隻有少量的資料,然後将最終的結果通過Voting的方式産生輸出,如下是參考代碼
#切分塊數
cnt=20
size = math.ceil(len(train) / cnt)
result=[]
for i in range(cnt):
start = size * i
end = (i + 1) * size if (i + 1) * size < len(train) else len(train)
#對資料做batch
slice = train[start:end]
result.append(batch_predict(pd.concat([slice,test]),i))
gc.collect() 特征選擇
特征選擇即從稀疏的特征中删除特征重要度為0,特征重要度排序較低的特征值,并通過npz的格式将特征持久化,供後續加載,核心代碼如下
se = pd.Series(clf.feature_importances_)
se = se[se>0]
##将特征重要性進行排序
col =list(se.sort_values(ascending=False).index)
pd.Series(col).to_csv('data_preprocessing/col_sort_one.csv',index=False)
##列印出來不為零的特征以及個數
print('特征重要性不為零的編碼特征有',len(se),'個')
n = clf.best_iteration_
baseloss = clf.best_score_['valid']['auc']
print('baseloss',baseloss)
#通過篩選特征找出最優特征個數
clf = LGBMClassifier(boosting_type='gbdt',
num_leaves=31, max_depth=-1,
learning_rate=0.1, n_estimators=n,
subsample_for_bin=200000, objective=None,
class_weight=None, min_split_gain=0.0,
min_child_weight=0.001,
min_child_samples=20, subsample=1.0, subsample_freq=1,
colsample_bytree=1.0,
reg_alpha=0.0, reg_lambda=0.0, random_state=None,
n_jobs=-1, silent=True)
print('開始進行特征選擇計算...')
all_num = int(len(se)/100)*100
print('共有',all_num,'個待計算特征')
loss = []
break_num = 0
for i in range(100,all_num,100):
loss.append(evalsLoss(col[:i]))
if loss[-1]>baseloss:
best_num = i
baseloss = loss[-1]
break_num+=1
print('前',i,'個特征的得分為',loss[-1],'而全量得分',baseloss)
print('\n')
if break_num==2:
break
print('篩選出來最佳特征個數為',best_num,'這下子訓練速度終于可以大大提升了') 如上所述,我們介紹了增量學習+特征選擇的方式,他适用的場景普遍在資料量在10G左右的單機計算,這種方式也适用于開發人員也可以通過阿裡PAI搭載計算資源Maxcompute來做模型驗證,采用這種方式有如下優勢
優勢:
- 模型的泛化能力最強,性能最好;
- 易于部署和模型疊代;
- 支援較為複雜的樹模型,模型可解釋強;
局限:
- 僅适用于單機場景,超過100G級别的資料很難訓練;
MMLSpark
Spark 是為通用資料處理而設計的,并非專用于機器學習任務 ,是以真正意義下Spark不是一個機器學習架構。 要在 Spark 上運作機器學習任務,可以使用 MLlib for Spark;但該方案通常存在如下局限:
- 不支援較為複雜的模型,如內建樹模型的訓練;
- 适用的場景多為baseline,對于參數的選擇支援有限,需要開發者自己重構(比如kmeans算法,spark内部使用的兩個向量間的距離是歐式距離。如果希望調整為餘弦或者馬氏距離,就需要重構了);
- 對網格調參支援并不理想;
鑒于此,微軟開發了MMLSpark,為Apache Spark提供了一些深入的學習和資料科學工具,實作了将機器學習元件 CNTK、LightGBM 和 Spark的 統一,至此:
- 我們可以基于Spark來運作內建樹模型的任務;
- 能夠對葉子節點設定等複雜參數來做調整;
- 支援超參數的搜尋
示例代碼如下:
# 執行個體化一個LightGBM Regressor, 其參數和單機版本類似但不盡相同, 文檔可以在以下連結找到:
# https://mmlspark.azureedge.net/docs/pyspark/LightGBMRegressor.html
lgbm = LightGBMRegressor(numIterations=120, objective='binary',
learningRate=0.007, baggingSeed=50,
boostingType="goss", lambdaL1=0.4, lambdaL2=0.4,
baggingFraction=0.87, minSumHessianInLeaf=0.003,
maxDepth=9, featureFraction=0.66, numLeaves=47,
labelCol="TARGET") MMLSpark對比增量學習有如下優勢
- 分布式訓練;
- 支援PB級别資料訓練模組化;
- 環境搭建與維護成本過于複雜;
Tensorflow等深度學習架構
将資料集均等地配置設定到系統的各個節點(node),其中每個節點都有該神經網絡的一個副本及其本地的權重。每個節點都會處理該資料集的一個不同子集并更新其本地權重集。這些本地權重會在整個叢集中共享,進而通過一個累積算法計算出一個新的全局權重集。這些全局權重又會被配置設定至所有節點,然後節點會在此基礎上處理下一批資料
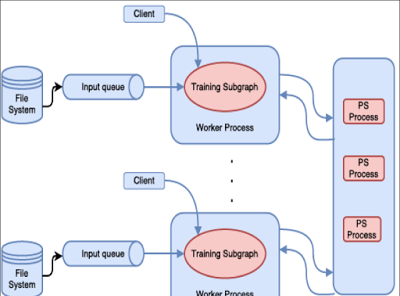
如上圖所示,在 TensorFlow 中,分布式機器學習訓練就使用了參數伺服器方法(PS)。實作了資料集的并行處理和參數的全局共享
采用深度學習架構的優勢如下
- Tensorflow、Mxnet與Pytorch天然支援分布式訓練,配置簡單靈活;
- 機器學習場景下,缺乏可解釋性
- 資料并行計算帶來了開發門檻
除開上述方法,如果采用阿裡雲的Maxcompute+Dataworks,可嘗試機器學習PAI的方式做海量的資料模組化,PAI屏蔽了分布式環境産生的開發複雜度,無需環境的配置與運維,應該說也是個“降本增效”的選擇

在最新的版本中,PAI支援了小資料集模型運算,可以讓開發者先跑通流程,在驗證之成功後方可進行大規模資料的計算。