雲栖号資訊:【 點選檢視更多行業資訊】
在這裡您可以找到不同行業的第一手的上雲資訊,還在等什麼,快來!
Apriori算法号稱是十大資料挖掘算法之一,在大資料時代威風無兩,哪怕是沒有聽說過這個算法的人,對于那個著名的啤酒與尿布的故事也耳熟能詳。但遺憾的是,随着時代的演進,大資料這個概念很快被機器學習、深度學習以及人工智能取代。即使是拉攏投資人的創業者也很少會講到這個故事了,雖然時代的變遷令人唏噓,但是這并不妨礙它是一個優秀的算法。
我們來簡單回顧一下這個故事,據說在美國的沃爾瑪超市當中,啤酒和尿布經常被擺放在同一個貨架當中。如果你仔細觀察就會覺得很奇怪,啤酒和尿布無論是從應用場景還是商品本身的屬性來分都不應該被放在一起,為什麼超市要這麼擺放呢?
看似不合理的現象背後往往都有更深層次的原因,據說是沃爾瑪引進了一種全新的算法,它分析了所有顧客在超市消費的記錄,然後計算商品之間的關聯性,發現這兩件商品的關聯性非常高。也就是說有大量的顧客會同時購買啤酒和尿布這兩種商品,是以經過資料的分析,沃爾瑪下令将這兩個商品放在同一個貨架上進行銷售。果然這麼一搞之後,兩種商品的銷量都提升了。
這個在背後分析資料,出謀劃策充當軍師一樣決策的算法就是Apriori算法。
關聯分析與條件機率
我們先把這個故事的真假放在一邊,先來分析一下故事背後折射出來的資訊。我們把問題進行抽象,沃爾瑪超市當中的商品種類大概有數萬種,我們的算法做的其實是根據售賣資料計算分析這些種類之間的相關性。專業術語叫做關聯分析,這個從字面上很好了解。但從關聯分析這個角度出發,我們會有些不一樣的洞見。
我們之前都學過條件機率,我們是不是可以用條件機率來反應兩個物品之間的關聯性呢?比如,我們用A表示一種商品,B表示另外一種商品,我們完全可以根據所有訂單的情況計算出P(A|B)和P(B|A),也就是說使用者在購買了A的情況下會購買B的機率以及在購買B的情況下會購買A的機率。這樣做看起來也很科學啊,為什麼不這樣做呢,還要引入什麼新的算法呢?
這也就是算法必要性問題,這個問題解決不了,我們好像會很難說服自己去學習一門新的算法。其實回答這個問題很簡單,就是成本。大型超市當中的商品一般都有幾萬種,而這幾萬種商品的銷量差異巨大。一些熱門商品比如水果、蔬菜的銷量可能是冷門商品,比如冰箱、洗衣機的上千倍甚至是上萬倍。如果我們要計算兩兩商品之間的相關性顯然是一個巨大的開銷,因為對于每兩個商品的組合,我們都需要周遊一遍整個資料集,拿到商品之間共同銷售的記錄,進而計算條件機率。
我們假設商品的種類數是一萬,超市的訂單量也是一萬好了,那麼兩兩商品之間的組合就有一億條,如果再乘上每次計算需要周遊一次整個資料集,那麼整個運算的複雜度大概會是一萬億。如果再考慮多個商品的組合,那這個數字更加可怕。
但實際上一個大型超市訂單量肯定不是萬級别的,至少也是十萬或者是百萬量級甚至更多。是以這個計算的複雜度是非常龐大的,如果考慮計算帶來的開銷,這個問題在商業上就是不可解的。因為即使算出來結果帶來的收益也遠遠無法負擔付出的計算代價,這個計算代價可能比很多人想得大得多,即使是使用現成的雲計算服務,也會帶來極為昂貴的開銷。如果考慮資料安全,不能使用其他公司的計算服務的話,那麼自己維護這些資料和人工帶來的消耗也是常人難以想象的。
如果想要得出切實可行的結果,那麼優化算法一定是必須的,否則可能沒有一家超市願意付出這樣的代價。
在我們介紹Apriori算法之前,我們可以先試着自己思考一下這個問題的解法。我真的試着想過,但是我沒有得到很好的答案,對比一下Apriori算法我才發現,這并非是我個人的問題,而是因為我們的思維有誤區。
如果你做過LeetCode,學過算法導論和資料結構,那麼你在思考問題的時候,往往會情不自禁地從最優解以及最佳解的方向出發。反應在這個問題當中,你可能會傾向于找到所有高關聯商品,或者是計算出所有商品對之間的關聯性。但是在這個問題當中,前提可能就是錯的。因為答案的完備性和複雜度之間往往是挂鈎的,找出所有的答案必然會帶來更多的開銷,而且落實在實際當中,犧牲一些完備性也是有道理的。因為對于超市而言,更加關注高銷量的商品,比如電冰箱和洗衣機,即使得出結論它們和某些商品關聯性很高對超市來說也沒有太大意義,因為電冰箱和洗衣機一天總共也賣不出多少台。
你仔細思考就會發現這個問題和算法的背景比我們一開始想的和了解的要深刻得多,是以讓我們帶着一點點敬畏之心來看看這個算法的詳細吧。
頻繁項集與關聯規則
在我們具體了解算法的原理之前,我們先來熟悉兩個術語。第一個屬于叫做頻繁項集,英文是frequent item sets。這個翻譯很接地氣,我們直接看字面意思應該就能了解。意思是經常會出現在一起的物品的集合。第二個屬于叫做關聯規則,也就是兩個物品之間可能存在很強的關聯關系。
用啤酒和尿布的故事舉個例子,比如很多人經常一起購買啤酒和尿布,那麼啤酒和尿布就經常出現在人們的購物單當中。是以啤酒和尿布就屬于同一個頻繁項集,而一個人買了啤酒很有可能還會購買尿布,啤酒和尿布之間就存在一個關聯規則。表示它們之間存在很強的内在聯系。
有了頻繁項集和關聯規則我們會做什麼事情?很簡單會去計算它們的機率。
對于一個集合而言,我們要考慮的是整個集合出現的機率。在這個問題場景當中,它的計算非常簡單。即用集合當中所有元素一起出現的次數,除以所有的資料條數。這個機率也有一個術語,叫做支援度,英文稱作support。
對于一個關聯規則而言,它指的是A物品和B物品之間的内在關系,其實也就是條件機率。是以A->B關聯規則的機率就是P(AB)/P(A)和條件機率的公式一樣,不過在這個問題場景當中,也有一個術語,叫做置信度,英文是confidence。
其實confidence也好,support也罷,我們都可以簡單地了解成出現的機率。這是一個計算機率的模型,可以認為是條件機率運算的優化。其中關聯規則是基于頻繁項集的,是以我們可以先把關聯規則先放一放,先來主要看頻繁項集的求解過程。既然頻繁項集的支援度本質上也是一個機率,那麼我們就可以使用一個門檻值來進行限制了。比如我們規定一個門檻值是0.5,那麼凡是支援度小于0.5的集合就不用考慮了。我們先用這個支援度過一遍全體資料,找出滿足支援度限制的單個元素的集合。之後當我們尋找兩個元素的頻繁項集的時候,它的候選集就不再是全體商品了,而隻有那些包含單個元素的頻繁項集。
同理,如果我們要尋找三項的頻繁項集,它的候選集就是含有兩項元素的頻繁項集,以此類推。表面上看,我們是把候選的範圍限制在了頻繁項集内進而簡化了運算。其實它背後有一個很深刻的邏輯,即不是頻繁項集的集合,一定不可能構成其他的頻繁項集。比如電冰箱每天的銷量很低,它和任何商品都不可能構成頻繁項集。這樣我們就可以排除掉所有那些不是頻繁項集的所有情況,大大減少了運算量。
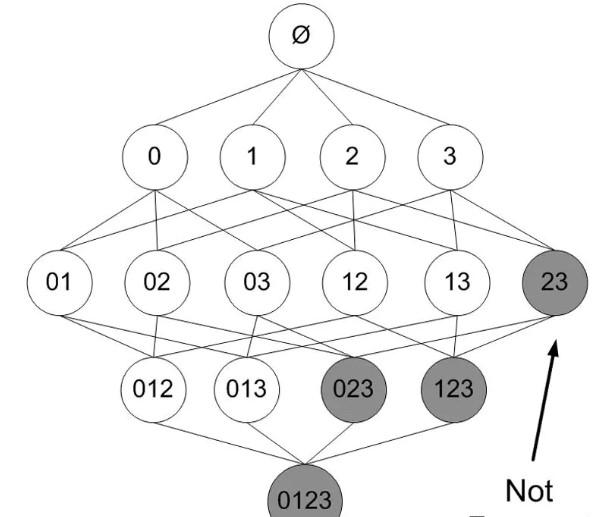
上圖當中的23不是頻繁項集,那麼對應的123和023顯然也都不是頻繁項集。其實我們把這些非頻繁的項集去掉,剩下的就是頻繁項集。是以我們從正面或者是反面了解都可以,邏輯的核心是一樣的。
Apriori算法及實作
其實Apriori的算法精髓就在上面的表述當中,也就是根據頻繁項集尋找新的頻繁項集。我們整理一下整個算法的流程,然後一點點用代碼來實作它,對照代碼和流程很容易就搞清楚了。
首先,我們來建立一批假的資料用來測試:

下面我們要生成隻有一個項的所有集合。這一步很好了解,我們需要對所有有交易的商品生成一個清單,也就是将所有交易記錄中的商品購買記錄進行去重。由于我們生成的結果在後序會作為dict的key,并且我們知道set也是可變對象,也是不可以作為dict中的key的。是以我們要做一點轉換,将它轉換成frozenset,它可以認為是不可以修改的set。
執行過後,我們會得到這樣一個序列:
[frozenset({1}), frozenset({2}), frozenset({3}), frozenset({4}), frozenset({5})] 上面的這個序列是長度為1的所有集合,我們稱它為C1,這裡的C就是component,也就是集合的意思。下面我們要生成的f1,也就是長度為1的頻繁集合。頻繁集合的選取是根據最小支援度過濾的,是以我們下面要實作的就是計算Ck中每一個集合的支援度,然後過濾掉那些支援度不滿足要求的集合。這個應該也很好了解:
frequent_components = []
supports = {}
<span class="hljs-keyword" style="color: #333; font-weight: bold; line-height: 26px;">for</span> k,v <span class="hljs-keyword" style="color: #333; font-weight: bold; line-height: 26px;">in</span> components_dict.items():
<span class="hljs-comment" style="color: #998; font-style: italic; line-height: 26px;"># 支援度就是集合在資料集中的出現次數除以資料總數</span>
support = v / rows
<span class="hljs-comment" style="color: #998; font-style: italic; line-height: 26px;"># 保留滿足支援度要求的資料</span>
<span class="hljs-keyword" style="color: #333; font-weight: bold; line-height: 26px;">if</span> support >= min_support:
frequent_components.append(k)
supports[k] = support 我們将支援度設定成0.5來執行一下,會得到以下結果:
可以發現資料中的4被過濾了,因為它隻出現了1次,支援度是0.25,達不到我們設定的門檻值,和我們的預期一緻。
現在我們有了方法建立長度為1的項集,也有了方法根據支援度過濾非頻繁的項集,接下來要做的已經很明顯了,我們要根據長度為1的頻繁項集生成長度為2的候選集,然後再利用上面的方法過濾得到長度為2的頻繁項集,再通過長度為2的頻繁項集生成長度為3的候選集,如此往複,直到所有的頻繁項集都被挖掘出來為止。
根據這個思路,我們接下來還有兩個方法要做,一個是根據長度為n的頻繁項集生成長度n+1候選集的方法,另一個方法是利用這些方法挖掘所有頻繁項集的方法。
我們先來看根據長度為n的項集生成n+1候選集的方法,這個也很好實作,我們隻需要用所有元素依次加入現有的集合當中即可。
這些方法都有了之後,剩下的就很好辦了,我們隻需要重複調用上面的方法,直到找不到更長的頻繁項集為止。我們直接來看代碼:
最後,我們運作一下這個方法檢視一下結果:
紅色框中就是我們從資料集合當中挖掘出的頻繁項集了。在一些場景當中我們除了想要知道頻繁項集之外,可能還會想要知道關聯規則,看看哪些商品之間存在隐形的強關聯。我們根據類似的思路可以設計出算法來實作關聯規則的挖掘。
關聯規則
了解了頻繁項集的概念之後再來算關聯規則就簡單了,我們首先來看一個很簡單的變形。由于我們需要計算頻繁項集之間的置信度,也就是條件機率。我們都知道P(A|B) = P(AB) / P(B),這個是條件機率的基本公式。這裡的P(A) = 出現A的資料條數/ 總條數,其實也就是A的支援度。是以我們可以用支援度來計算置信度,由于剛剛我們在計算頻繁項集的時候算出了所有頻繁項集的支援度,是以我們可以用這份資料來計算置信度,這樣會簡單很多。
我們先來寫出置信度的計算公式,它非常簡單:
這裡的comp表示集合,subset表示我們要推斷的項。也就是我們挖掘的是comp-item這個集合與subset集合之間的置信度。
接着我們來看候選規則的生成方法,它和前面生成候選集合的邏輯差不多。我們拿到頻繁項集之後,扣除其中的一個子集,将它作為一個候選的規則。
<span class="hljs-comment" style="color: #998; font-style: italic; line-height: 26px;"># 周遊所有子集</span>
<span class="hljs-keyword" style="color: #333; font-weight: bold; line-height: 26px;">for</span> i <span class="hljs-keyword" style="color: #333; font-weight: bold; line-height: 26px;">in</span> all_set:
<span class="hljs-comment" style="color: #998; font-style: italic; line-height: 26px;"># 周遊頻繁項集</span>
<span class="hljs-keyword" style="color: #333; font-weight: bold; line-height: 26px;">for</span> comp <span class="hljs-keyword" style="color: #333; font-weight: bold; line-height: 26px;">in</span> components:
<span class="hljs-comment" style="color: #998; font-style: italic; line-height: 26px;"># 如果子集關系成立,則生成了一條候選規則</span>
<span class="hljs-keyword" style="color: #333; font-weight: bold; line-height: 26px;">if</span> i <= comp:
rules.append((comp, i))
<span class="hljs-keyword" style="color: #333; font-weight: bold; line-height: 26px;">return</span> rules
最後,我們把上面兩個方法串聯在一起,先生成所有的候選規則,再根據置信度過濾掉符合條件的關聯規則。利用之前頻繁項集時候生成的資料,很容易實作這點。
我們運作一下這個方法,看一下結果:
從結果來看還不錯,我們挖掘出了所有的關聯規則。要注意一點A->B和B->A是兩條不同的規則,這并不重複。舉個簡單的例子,買乒乓拍的人往往都會買乒乓球,但是買乒乓球的人卻并不一定會買乒乓拍,因為乒乓拍比乒乓球貴得多。而且乒乓球是消耗品,乒乓拍不是。是以乒乓拍可以關聯乒乓球,但反之不一定成立。
結尾、升華
到這裡,Apriori算法和它的應用場景就講完了。這個算法的原理并不複雜,代碼也不困難,沒有什麼高深的推導或者是晦澀的運算,但是算法背後的邏輯并不簡單。怎麼樣為一個複雜的場景涉及簡單的名額?怎麼樣縮小我們計算的範圍?怎麼樣衡量資料的價值?其實這些并不是空穴來風,顯然算法的設計者是付出了大量思考的。
如果我們順着解法出發去試着倒推當時設計者的思考過程,你會發現看似簡單的問題背後其實并不簡單,看似自然而然的道理,也并不自然,這些看似尋常的背後都隐藏着邏輯,這些背後的思考和邏輯,才是算法真正寶貴的部分。
【雲栖号線上課堂】每天都有産品技術專家分享!
課程位址:
https://yqh.aliyun.com/live立即加入社群,與專家面對面,及時了解課程最新動态!
【雲栖号線上課堂 社群】
https://c.tb.cn/F3.Z8gvnK
原文釋出時間:2020-05-06
本文作者:承志
本文來自:“
掘金”,了解相關資訊可以關注“掘金”