好程式員Java教程之ZooKeeper面試題梳理彙總,随着疫情的好轉,各大企業開始以遠端面試的形式進行人才招聘,而Java行業依舊是需求量最大的人群,但招聘要求卻有很大提高。有學員擔心無法通過企業面試,其實隻要你技能過關、表現良好,高薪就不是問題。接下來的好程式員Java就業指導小編就給大家分享ZooKeeper相關的面試題。
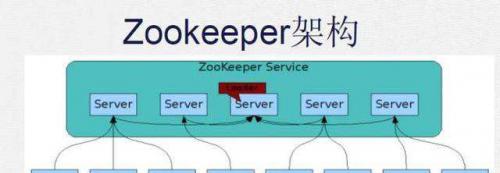
ZooKeeper是什麼?
ZooKeeper是一個開放源碼的分布式協調服務,它是叢集的管理者,監視着叢集中各個節點的狀态根據節點送出的回報進行下一步合理操作。最終,将簡單易用的接口和性能高效、功能穩定的系統提供給使用者。
分布式應用程式可以基于Zookeeper實作諸如資料釋出/訂閱、負載均衡、命名服務、分布式協調/通知、叢集管理、Master選舉、分布式鎖和分布式隊列等功能。Zookeeper保證分布式一緻性特性:順序一緻性、原子性、單一視圖、可靠性、實時性(最終一緻性)。
ZooKeeper負載均衡和nginx負載均衡差別
ZooKeeper
1)不存在單點問題,zab機制保證單點故障可重新選舉一個leader;
2)隻負責服務的注冊與發現,不負責轉發,減少一次資料交換(消費方與服務方直接通信);
3)需要自己實作相應的負載均衡算法。
nginx
1))存在單點問題,單點負載高資料量大,需要通過KeepAlived+LVS備機實作高可用;
2)每次負載,都充當一次中間人轉發角色,增加網絡負載量(消費方與服務方間接通信);
3)自帶負載均衡算法。
Zookeeper Watcher 機制--資料變更通知
Zookeeper允許用戶端向服務端的某個Znode注冊一個Watcher監聽,當服務端的一些指定事件觸發了這個Watcher,服務端會向指定用戶端發送一個事件通知來實作分布式的通知功能,然後用戶端根據Watcher通知狀态和事件類型做出業務上的改變。
工作機制:
用戶端注冊watcher
服務端處理watcher
用戶端回調watcher
ZooKeeper是如何保證事務的順序一緻性的?
ZooKeeper采用了全局遞增的事務Id來辨別,所有的proposal(提議)都在被提出的時候加上了zxid,zxid實際上是一個64位的數字,高32位是epoch(時期; 紀元; 世; 新時代)用來辨別leader周期,如果有新的leader産生出來,epoch會自增,低32位用來遞增計數。當新産生proposal的時候,會依據資料庫的兩階段過程,首先會向其他的server發出事務執行請求,如果超過半數的機器都能執行并且能夠成功,那麼就會開始執行。
Zookeeper對節點的watch監聽通知是永久的嗎?
不是。官方聲明:一個Watch事件是一個一次性的觸發器,當被設定了Watch的資料發生了改變的時候,則伺服器将這個改變發送給設定了Watch的用戶端,以便通知它們。
為什麼不是永久的,舉個例子,如果服務端變動頻繁,而監聽的用戶端很多情況下,每次變動都要通知到所有的用戶端,給網絡和伺服器造成很大壓力。
一般是用戶端執行getData(“/節點A”,true),如果節點A發生了變更或删除,用戶端會得到它的watch事件,但是在之後節點A又發生了變更,而用戶端又沒有設定watch事件,就不再給用戶端發送。
在實際應用中,很多情況下,我們的用戶端不需要知道服務端的每一次變動,我隻要最新的資料即可。
ZK節點當機如何處理?
Zookeeper本身也是叢集,推薦配置不少于3個伺服器。Zookeeper自身也要保證當一個節點當機時,其他節點會繼續提供服務。
如果是一個Follower當機,還有2台伺服器提供通路,因為Zookeeper上的資料是有多個副本的,資料并不會丢失;
如果是一個Leader當機,Zookeeper會選舉出新的Leader。
ZK叢集的機制是隻要超過半數的節點正常,叢集就能正常提供服務。隻有在ZK節點挂得太多,隻剩一半或不到一半節點能工作,叢集才失效。
是以:
3個節點的cluster可以挂掉1個節點(leader可以得到2票>1.5);
2個節點的cluster就不能挂掉任何1個節點了(leader可以得到1票<=1)。
![GitHub連夜封殺!這份阿裡 10W 字内部 Java 字面試手冊到底有多強?[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)