Classes 4 卷積神經網絡
1卷積神經網絡
1 計算機視覺
應用:
- 圖檔分類
- 圖檔識别
- 目标檢測
- 風格遷移
- .... ...
1.2 邊緣檢測
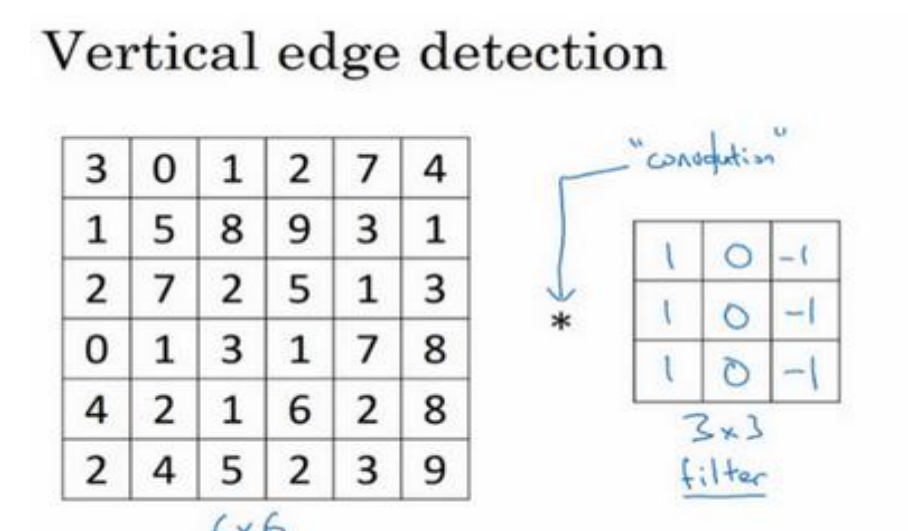

邊緣檢測算子中的數字用于進行邊緣檢測
計算機視覺不一定要去使用那些研究者們所選擇的這九個數字,而是将這 9 個數字當成學習參數
1.3 padding
valid: 不填充,卷積後尺寸變小
same: 填充,卷積後尺寸不變
這也是為什麼通常将卷積核設定為奇數的充分原因
1.4 步長
卷積操作:向下取整
1.5 三維卷積
按照計算機視覺的慣例,當你的輸入有特定的高寬和通道數時,你的過濾器可以有不同的高,不同的寬,但是必須一樣的通道數。
注意:
- 多個卷積核的情況,結果數與卷積核的數量一緻。
- 兩個過濾器,也就是有兩個特征(檢測兩個特征)。
參數計算:
(每個卷積核的參數+1個bias) * 卷積核的個數
1.6 簡單例子
逐層提取特征,在最後一層進行特征展開,為一個向量,輸入到邏輯回歸或者softmax分類器,得到最終分類結果。
1.7 池化層pooling
除了卷積層,卷積網絡也經常使用池化層來縮減模型的大小,提高計算速度,同時提高所提取特征的魯棒性。
- 最大池化: max pooling 輸出的每個元素都是其對應顔色區域中的最大元素值。
吳恩達深度學習課程筆記-Classes 4
最大化運算的實際作用就是,如果在過濾器中提取到某個特征,那麼保留其最大值。如果沒有提取到這個特征,可能在右上象限中不存在這個特征,那麼其中的最大值也還是很小,這就是最大池化的直覺了解。
- 平均池化: 選取的不是每個過濾器的最大值,而是平均值
吳恩達深度學習課程筆記-Classes 4 - 一般而言,最大池化比平均池化要常用些,但例外就是深度很深的神經網絡,可以用平均池化來分解規模為 7×7×1000 的網絡的表示層,在整個空間内求平均值,得到1×1×1000,取代全連接配接層。
- 輸入通道與輸出通道個數相同,因為我們對每個通道都做了池化。
- 池化過程中沒有需要學習的參數。執行反向傳播時,反向傳播沒有參數适用于最大池化。
池化層的反向傳播
需要保證傳遞的loss(或者梯度)總和不變
- mean pooling: 把一個patch中的值求取平均來做pooling,那麼反向傳播的過程也就是把某個元素的梯度等分為n份配置設定給前一層,這樣就保證池化前後的梯度(殘差)之和保持不變
- max pooling: 把梯度直接傳給前一層某一個像素,而其他像素不接受梯度,也就是為0
1.8 卷積神經網絡例子
- 人們在計算神經網絡有多少層時,通常隻統計具有權重和參數的層。因為池化層沒有權重和參數,隻有一些超參數。這裡,我們把 CONV1和 POOL1 共同作為一個卷積,并标記為Layer1
- 正常做法是,盡量不要自己設定超參數,而是檢視文獻中别人采用了哪些超參數,選一個在别人任務中效果很好的架構,那麼它也有可能适用于自己的應用程式
- 找到整合基本構造子產品最好方法就是大量閱讀别人的案例
1.9 為什麼使用卷積
和隻用全連接配接層相比,卷積層的兩個主要優勢在于參數共享和稀疏連接配接。
- 參數共享:每個特征檢測器以及輸出都可以在輸入圖檔的不同區域中使用同樣的參數,以便提取垂直邊緣或其它特征
- 稀疏連接配接:依賴于這個 3×3 的輸入的單元格,右邊這個輸出單元(元素 0)僅與 36 個輸入特征中 9 個相連接配接。而且其它像素值都不會對輸出産生任影響。
2 執行個體探究
在計算機視覺任務中表現良好的神經網絡架構往往也适用于其它任務, 完全可以借鑒别人的神經網絡架構來解決自己的問題。
2.1 經典網絡
- LeNet-5 的網絡結構
吳恩達深度學習課程筆記-Classes 4
左往右看,随着網絡越來越深,圖像的高度和寬度在縮小,從最初的 32×32 縮小到 28×28,再到 14×14、10×10,最後隻有 5×5。與此同時,随着網絡層次的加深,通道數量一直在增加,從 1 增加到 6 個,再到 16 個。
一種模式至今仍然經常用到,就是一個或多個卷積層後面跟着一個池化層,然後又是若幹個卷積層再接一個池化層,然後是全連接配接層,最後是輸出,這種排列方式很常用。
* AlexNet
- 這些層分别拆分到兩個不同的 GPU 上,同時還專門有一個方法用于兩個 GPU 進行交流
- 叫作“局部響應歸一化層”(Local Response Normalization),即 LRN 層
-
VGG
VGG16在這個網絡中包含 16 個卷積層和全連接配接層
- padding都是same,conv層輸出的尺寸沒有變化。
- 由 64 翻倍變成 128,再到 256 和 512。作者可能認為 512 已經足夠大了,是以後面的層就不再翻倍了。無論如何,每一步都進行翻倍,或者說在每一組卷積層進行過濾器翻倍操作,正是設計此種網絡結構的另一個簡單原則。
- 随着網絡的加深,圖像的高度和寬度都在以一定的規律不斷縮小,每次池化後剛好縮小一半,而通道數量在不斷增加,而且剛好也是在每組卷積操作後增加一倍。
2.2 殘差網絡ResNet
在殘差網絡中有一點變化,我們将𝑎[𝑙]直接向後,拷貝到神經網絡的深層,在 ReLU 非線性激活函數前加上𝑎[𝑙],這是一條捷徑。𝑎[𝑙]的資訊直接到達神經網絡的深層,不再沿着主路徑傳遞。
𝑎[𝑙+2] = 𝑔(𝑧[𝑙+2] + 𝑎[𝑙])
- 使用殘差塊能夠訓練更深的神經網絡
- 這種方式确實有助于解決梯度消失和梯度爆炸問題,讓我們在訓練更深網絡的同時,又能保證良好的性能
為什麼效果好:
- 殘差塊最差的效果是與原有的一樣(w、b為0),隻是多了幾層
- 隐藏層單元學到一些有用資訊,那麼它可能比學習恒等函數表現得更好
- ResNets 使用了許多 same 卷積,是以這個𝑎[𝑙]的次元等于這個輸出層的次元。之是以能實作跳躍連接配接是因為 same 卷積保留了次元,是以很容易得出這個捷徑連接配接,并輸出這兩個相同次元的向量
吳恩達深度學習課程筆記-Classes 4
2.3 為 1×1 卷積、 Network in Network
作用:
- 1×1 卷積是壓縮或增加通道數量,并減少計算量
- 提供非線性函數功能
2.4 inception網絡
使用 same 卷積,保持次元不變
- 基本思想是 Inception 網絡不需要人為決定使用哪個過濾器或者是否需要池化,而是由網絡自行确定這些參數,你可以給網絡添加這些參數的所有可能值,然後把這些輸出連接配接起來,讓網絡自己學習它需要什麼樣的參數,采用哪些過濾器組合。
吳恩達深度學習課程筆記-Classes 4
28×28×256 的輸出。通道連接配接實際就是把所有方塊連接配接在一起的操作。
- GoogleLeNet
吳恩達深度學習課程筆記-Classes 4
2.5 資料增強
當訓練計算機視覺模型的時候,資料增強會有所幫助。
- 垂直鏡像
吳恩達深度學習課程筆記-Classes 4 - 随機裁剪
吳恩達深度學習課程筆記-Classes 4 - 旋轉
- 扭曲變形
- 局部彎曲
- 彩色轉換: R、G 和 B 三個通道上加上不同的失真值
吳恩達深度學習課程筆記-Classes 4
2.6 計算機視覺現狀
- 資料量少:傳統機器學習方法,手工特征工程,遷移學習等
- 資料量大:深度學習方法
提升基準測試或者競賽:
- 內建:訓練多個分類器,取均值
- multi-crop:對同一張圖随機裁剪10次,得到10張圖,然後取平均結果
3 目标檢測
3.1 目标定位
算法判斷圖檔中是不是一輛汽車,還要在圖檔中标記出它的位置,用邊框或紅色方框把汽車圈起來,這就是定位分類問題
目标檢測在原有的圖像分類基礎上又增加了幾個輸出:邊界框𝑏𝑥,𝑏𝑦, 𝑏ℎ和𝑏𝑤,這四個數字是被檢測對象的邊界框的參數化表示。
标簽
:
第一個元件𝑝𝑐表示是否含有對象,如果對象屬于前三類(行人、汽車、機車),則𝑝𝑐 = 1,如果是背景,則圖檔中沒有要檢測的對象,則𝑝𝑐 = 0。我們可以這樣了解𝑝𝑐,它表示被檢測對象屬于某一分類的機率,背景分類除外。
𝑝𝑐 = 1,同時輸出𝑐1、𝑐2和𝑐3,表示該對象屬于 1-3 類中的哪一類。
損失函數:
3.2 特征點檢測
神經網絡可以通過輸出圖檔上特征點的(𝑥, 𝑦)坐标來實作對目标特征的識别
準備一個卷積網絡和一些特征集,将人臉圖檔輸入卷積網絡,輸出 1 或 0, 1 表示有人臉,0 表示沒有人臉,然後輸出(𝑙1𝑥,𝑙1𝑦)……直到(𝑙64𝑥,𝑙64𝑦)。這裡我用𝑙代表一個特征,這裡有129 個輸出單元,其中1表示圖檔中有人臉,因為有64個特征,64×2=128,是以最終輸出 128+1=129 個單元
人體姿态檢測,你還可以定義一些關鍵特征點,如胸部的中點,左肩,左肘,腰等。然後通過神經網絡标注人物姿态的關鍵特征點,再輸出這些标注過的特征點,就相當于輸出了人物的姿态動作。
3.3 目标檢測
滑動窗檢測:
滑動視窗目标檢測算法接下來會繼續處理第二個圖像,即紅色方框稍向右滑動之後的區域,并輸入給卷積網絡,是以輸入給卷積網絡的隻有紅色方框内的區域,再次運作卷積網絡,然後處理第三個圖像,依次重複操作,直到這個視窗滑過圖像的每一個角落。
- 優點:表現良好
- 缺點:計算成本太高,因為在圖檔中剪切出太多小方塊,卷積網絡要一個個地處理。如果間隔步伐太大,顯然會減少輸入卷積網絡的視窗個數,但是粗糙間隔尺寸可能會影響性能
3.4 滑動視窗的實作
不需要把輸入圖像分割成四個子集,分别執行前向傳播,
而是把它們作為一張圖檔輸入給卷積網絡進行計算,其中的公共區域可以共享很多計算。
3.5 bound box預測
在滑動視窗法中,你取這些離散的位置集合,然後在它們上運作分類器,在這種情況下,這些邊界框沒有一個能完美比對汽車位置。
yolo算法可以獲得準确的方格。在圖像上放一個網格。基本思路是使用圖像分類和定位算法。對于每個格子都指定一個标簽y
普通的卷積網絡,卷積層,最大池化層等等,最後你會有這個,選擇卷積層和最大池化層,這樣最後就映射到一個 3×3×8 輸出尺寸。是以你要做的是,有一個輸入𝑥,就是這樣的輸入
圖像,然後你有這些 3×3×8 的目标标簽𝑦。
優點在于神經網絡可以輸出精确的邊界框,但是每個格子隻能有一個對象
- 這和圖像分類和定位算法非常像
- 卷積實作,運作速度快,可以達到實時
讀不懂研究論文的時候,必須去讀源代碼,或者聯系作者之類的才能弄清楚這些算法的細節
3.6 交叉比IOU
一般約定,在計算機檢測任務中,如果𝑙𝑜𝑈 ≥ 0.5,就說檢測正确,如果預測器和實際邊界框完美重疊,loU 就是 1,因為交集就等于并集。但一般來說隻要𝑙𝑜𝑈 ≥ 0.5,那麼結果是可以接受的,看起來還可以。
3.7 非極大值抑制
非極大值抑制這個方法可以確定你的算法對每個對象隻檢測一次
會對同一個對象做出多次檢測,是以非極大值抑制做的就是清理這些檢測結果。這樣一輛車隻檢測一次,而不是每輛車都觸發多次檢測。
pc*c1、c2、c3
先用門檻值丢棄一些結果
然後去掉所有剩下的邊界框,任何沒有達到輸出标準的邊界框,之前沒有抛棄的邊界框,把這些和輸出邊界框有高重疊面積和上一步輸出邊界框有很高交并比的邊界框全部抛棄
3.8 anchor boxes
預先定義兩個不同形狀的 anchor box,或者 anchor
box 形狀,你要做的是把預測結果和這兩個 anchor box 關聯起來。
觀察哪一個 anchor box 和實際邊界框(編号1,紅色框)的交并比更高,不管選的是哪一個,這個對象不隻配置設定到一個格子,而是配置設定到一對,即(grid cell,anchor box)對,這就是對象在目标标簽中的編碼方式。是以現在輸出 𝑦 就是 3×3×16,上一張幻燈片中你們看到 𝑦 現在是 16 維的,或者你也可以看成是3×3×2×8,因為現在這裡有 2 個 anchor box,而 𝑦 是 8 維的。
anchor box 這個概念,是為了處理兩個對象出現在同一個格子的情況
對于每個類别單獨運作非極大值抑制,處理預測結果所屬類别的邊界框,用非極大值抑制來處理行人類别,用非極大值抑制處理車子類别,然後對機車類别進行非極大值抑制,運作
三次來得到最終的預測結果。是以算法的輸出最好能夠檢測出圖像裡所有的車子,還有所有的行人
3.9 候選區域
4 特殊應用
4.1 人臉識别
人臉驗證與人臉識别的差別
人臉驗證問題:如果你有一張輸入圖檔,以及某人的 ID 或者是名字,這個系統要做的是,驗證輸入圖檔是否是這個人。有時候也被稱作 1 對 1 問題,隻需要弄明白這個人是否和他聲稱的身份相符
人臉識别問題:比人臉驗證問題難很多,是1對k的問題
4.2 one-shot 學習
需要通過單單一張圖檔或者單單一個人臉樣例就能去識别這個人, 訓練樣本隻有一個。
不再是分類問題,而是要學習一個能夠衡量二者差別的函數
4.3 siamese 網絡(孿生網絡)
輸入不再是一個圖檔,而是圖檔對。輸出二者的次元為128維,然後比較二者的距離。
損失函數可以:
- Contrastive Loss
- cosine更适用于詞彙級别的語義相似度度量
- exp更适用于句子級别、段落級别的文本相似性度量
4.4 Triplet loss
應用三元組損失函數,你需要比較成對的圖像。一個 Anchor圖檔,想讓 Anchor 圖檔和 Positive 圖檔(Positive 意味着是同一個人)的距離很接近。然而,當 Anchor 圖檔與 Negative圖檔(Negative 意味着是非同一個人)對比時,會想讓其距離離得更遠一點。
anchor與正樣本之間的距離小于anchor與負樣本之間的距離
為了確定網絡對于所有的編碼不會總是輸出 0,也為了確定它不會把所有的編碼都設成互相相等的
𝑎是另一個超參數,這個就可以阻止網絡輸出無用的結果。
如何建構訓練樣本:
- 随機選擇的話太容易滿足限制條件
吳恩達深度學習課程筆記-Classes 4 -
盡可能選擇難訓練的三元組APN
𝐴、𝑃和𝑁的選擇使得𝑑(𝐴, 𝑃)很接近𝑑(𝐴, 𝑁),即𝑑(𝐴, 𝑃) ≈ 𝑑(𝐴, 𝑁),這樣學習算法會竭盡全力使右邊這個式子變大(𝑑(𝐴, 𝑁)),或者使左邊這個式子(𝑑(𝐴, 𝑃))變小,這樣左右兩邊至少有一個𝑎的間隔。
4.5 人臉驗證與而分類
最後兩個特征進行相減後,再送入logist回歸,輸出0/1
4.6 神經風格遷移
将使用𝐶來表示内容圖像,𝑆表示風格圖像,𝐺表示生成的圖像
代價函數:
- 内容代價:衡量c與g内容的相似性
- 風格代價:衡量s與g風格的相似性
吳恩達深度學習課程筆記-Classes 4
模型:
- 1.随機生成生成圖檔G像素矩陣
- 2.利用損失函數更新G像素矩陣值 𝐺: = 𝐺 − 𝜕𝐽(𝐺)/𝜕G
内容代價函數:
- 使用預訓練的cnn網絡模型抽特征,計算二者的特征距離,将其作為内容代價。
吳恩達深度學習課程筆記-Classes 4
風格代價函數
利用風格矩陣表示各自的風格,然後計算二者矩陣差,求和求均值
訓練