雲栖号資訊:【 點選檢視更多行業資訊】
在這裡您可以找到不同行業的第一手的上雲資訊,還在等什麼,快來!
概述
對于一些設計和端上展示的場景,布局都是一個非常重要的環節。在一個設計上的布局中,首先我們會對基礎元素定一些分類,這些分類的次元可以取決于目前的場景,比如把元素劃分成圖檔,文字,或是把元素劃分為标題,段落等。同時,每個元素會有其在這個設計文檔中的相應的位置。結合最近的一些樣本生成和樣本增強的研究,如何可以設計一個模型,自動的生成一些布局就成為了研究的一個方向。
'READ: Recursive Autoencoders for Document Layout Generation' 這篇論文提出了一種使用遞歸神經網絡和自編碼器結合的方法從随機的高斯分布中自動生成不同的布局,同時,引入了一個組合度量方法來衡量方法的好壞。後面的篇幅中我們将主要介紹這篇文章的方法以及在前端場景落地的一些思考。
遞歸神經網絡和自編碼器
在介紹這篇文章之前,我想要簡單的介紹一些遞歸神經網絡 (RVNN) 和 變分自編碼器 (VAE) 這兩種技術,這裡隻是一個概述,讀者可以通過查閱資料對這兩種技術進行更深入的了解。
遞歸神經網絡
遞歸神經網絡乍一聽可能很像循環神經網絡,正好兩者又都可以稱作 RNN,也都可以處理變長的資料,但是内在的思想還是不一樣的。其本質要解決是樣本空間蘊含着樹或者圖狀結構這一類問題。
如上圖所示,對于每一次神經網絡的輸入來說,都是兩個向量,這裡面我們把它叫做子向量,經過網絡的前向運算之後,将生成一個父向量,然後這個父向量再和另一個子節點進入網絡,産出一個向量,這樣子就形成了一個遞歸的過程,最終會生成一個根結點或者叫根向量

比如如上這個例子,如果每一個葉子節點都是一個詞語的表達,那麼最終訓練出來的網絡就可以把這些詞最終合為語義空間的一個向量,這個向量可以代表這句話,同時也意味着相近的向量可以表達相同的語義。
VAE
VAE 是自編碼器的一種,相信了解 GAN 的讀者也同樣對 VAE 很熟悉了,先簡單介紹一下自編碼器
自編碼器大概的思想就是說今天假如你有兩個網絡,第一個網絡負責将一個高維空間的向量 x 映射到一個低維空間的向量 z,例如圖中的我們把圖檔映射到一個一維的向量, 然後第二個網絡負責把這個 z 向量再映射到一個高維空間的向量 x1, 我們訓練的目标就是 x 和 x1 要盡可能的相近。這樣一來,我們就可以認為這個 z 向量是 x 的一種表示,同樣,我們把訓練好的 x1 拿出來也就成為了一個生成網絡,可以生成 z 表示的相應的圖檔。
而 VAE 在自編碼器上做了一些改進,VAE 即使就是在自編碼器的基礎上讓 encoder 再額外産生一個 varaince 的随機向量,同時這個 varaince 和 z 組合起來一起進入下一步進而讓模型更加穩定
怎麼表示訓練資料
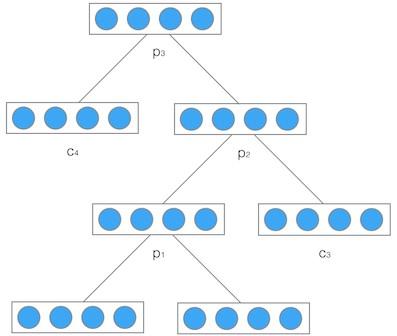
要解決自動生成布局的問題,首先我們需要一種表示資料的方式。在這個研究中,我們的原始資料是一些設計文檔和這個文檔相應的每個基礎元素的分類和位置大小,也就是注解。現在,為了訓練我們的遞歸神經網絡,我們需要一種方式把這些注解進行結構化的拆解,轉化成相應的訓練資料。
如上圖所示,為了更好的适配遞歸網絡,我們首先把資料轉化為二叉樹的形式,我們會對設計文檔進行從左到右,從上到下的掃描,對于每個基礎元素,實際就相當于一個葉子節點,然後按照掃描的順序自下而上 (bottom top) 進行節點的合并,合并後的節點我們稱之為内部節點,這樣,最終就會合并成為一個根結點。注意,每個内部節點實際上有一個相對位置的資訊,就是合并前的兩個元素的相對位置,可以分為 right, bottom right, bottom, enclosed, bottom left 等。每個葉子節點的 bounding box 的寬高都會首先被歸一化到 [0, 1] 中
遞歸模型搭建
對于訓練資料,我們會把每個葉子節點的寬高和分類資訊連接配接成一個向量,寬高數值在 [0, 1] 之間,分類是一個 one-hot vector,然後我們使用一個單層的神經網絡把這個連接配接向量映射成一個 n-D 稠密向量中,n 在論文中介紹的經驗值為 300。這樣,實際上輸入的就是一個 300 維的向量
編碼器 (spatial relationship encoder SRE)
遞歸網絡中的編碼器實際上就是一個多層感覺器,在論文中這個感覺器的隐藏層一般隻有一到兩層,這個感覺器輸入為兩個節點,輸出為合并後的節點
如公式所示,x1 x2 就是輸入的兩個節點的 n_D 向量,r 代表兩個向量的相對位置,以左邊的那個元素為基準。f 函數表示目前編碼器的多層感覺器的表達式。這樣不斷的在遞歸網絡中進行編碼,最終合并成一個代表根節點的向量
解碼器 (spatial relationship decoder SRD)
很簡單,解碼器就是上面的一個向過程,把父節點再給分解成兩個節點
在遞歸中,對于編碼器和解碼器是可以同一個重複使用的,例如可以根據相對位置的類别分成不同的編碼器和解碼器,相同類别的服用同一個網絡進行訓練,同時我們可以訓練一個神經網絡來判斷目前節點應該還是内部節點還是葉子節點,如果是内部節點,那麼将繼續解碼,如果是葉子節點,則把節點映射成為元素的 bounding box 和分類。
訓練模型
在我們模型确定好了之後現在我們來定義訓練的損失函數,我們先來看一下表達式
達标了葉子節點的 reconstruction error, 意思也就是一開始葉子節點的向量和最終解碼器解碼回來的葉子節點向量的差别。
衡量了相對位置的 reconstruction error, 也就是一開始的相對位置和解碼器解碼回來的相對位置的向量的差别。
衡量了相對位置類别的分類損失,也就是一個标準的交叉熵損失函數。
是最終根節點的向量所代表的空間 p(z) 和标準高斯分布 q(z) 的一個 KL divergence,這是由于我們最終希望我們解碼器的輸入是一個從高斯分布 sample 出來的一個随機向量,然後模型可以自動的生成一個布局,是以我們希望根節點的向量可以盡可能的像高斯分布
具體上面的四個損失函數的式子我在這裡就不一一贅述了,形式都非常的簡單,通過這一個合成的損失函數,我們就可以開始訓練我們的模型啦。
衡量模型
這篇文章提供了他們自己的衡量方法,他們把這套方法命名為 DocSim, 顧名思義就是衡量文檔的相似度。這套方法實際上是基于 BLEU 方法的,也就是用來衡量翻譯系統的一套方案。DocSim 類似地比較了兩個給定的文檔, D,D' , 對于任意一對 bounding box B ∈ D 和 B' ∈ D,我們配置設定一個名額衡量 B 和 B' 在形狀,位置和分類上有多相似,最終的衡量分數就是這個把很多對 bounding box 的衡量名額的總權重。
實驗資料集
ICDAR2015 資料集
ICDAR2015 資料集是一套公開的資料集,包含 478 個設計文檔,主要是雜志文章。對于這些文檔,我們考慮以下語義類别: 标題、段落、頁腳、頁碼和圖形。
User-Solicited (US) 資料集
一個包含了 2036 的設計文檔的資料集,主要是一些使用者送出表達的資料,包括稅務表格和銀行申請等。這些檔案通常表現出高度複雜的結構和大量的原子元素類型。這些特性為生成模型生成文檔提出了一個挑戰
實驗結果
這是将這篇論文中提出的方法和 probabilistic approach 在 ICDAR 資料集比較的結果,數值表示 latent distribution 的相似性,可以看出論文中提出的方法是更優的
這是這篇論文的方法和 LayoutGAN 比較的結果,可以看出,首先論文的方法對訓練資料樣本的數量要求更少,其次,這篇論文的方法可以産出更多的元素。
一些思考
這篇文章主要提出的方法是用來産出布局的,對于前端場景,同樣存在着從一個原始設計稿轉化為合理的布局的問題。例如,當我們有一個原始圖檔的時候,我們怎麼可以正确的對圖檔中的基礎元素進行提取,确定每個基礎元素的類型(圖檔還是文字圖層)和這個元素的位置。
毫無疑問,這個研究是需要大量的訓練資料作為支撐的,如果把論文中的方案應用到前端場景的資料中,或許可以為我們的目标提供一種樣本生成和樣本增強的方法,進而獲得一些合理的訓練資料。之後,我們也快在這塊做一些相應的研究以驗證這種方案的可行性。
【雲栖号線上課堂】每天都有産品技術專家分享!
課程位址:
https://yqh.aliyun.com/zhibo立即加入社群,與專家面對面,及時了解課程最新動态!
【雲栖号線上課堂 社群】
https://c.tb.cn/F3.Z8gvnK
原文釋出時間:2020-04-09
本文作者:設計稿智能生成代碼
本文來自:“掘金”,了解相關資訊可以關注“掘金”