LTM給NGINX做LB是一種較為典型的雙層負載均衡,也就是典型的L4.L7分離的雙層負載均衡解決方案。我們用了這個方案後,出現了 NGINX 後的伺服器過載,怎麼辦?應該如喝解決?
根絕我分析,如果LTM的pool member中的NGINX是位于不同的可用區或者不同的DC,此時LTM如僅做應用層負載均衡或僅monitor nginx本身,那麼LTM是無法感覺到 NGINX 背後(upstream)到底有多少可用的業務伺服器。如果某個 NGINX 的upstream中可用伺服器已經很少,此時LTM會依舊配置設定同等數量的連接配接請求給該NGINX,會導緻該 NGINX 後的伺服器過載,進而降低服務品質。
F5提供的負載均衡解決方案的思路如下:
如果能夠讓LTM感覺到NGINX的upstream中目前有多少可用的伺服器,并設定一個閥值,如低于該可用數量則LTM不再向該NGINX執行個體配置設定連接配接。這樣就可以較好的避免上述問題。運維人員可根據LTM報出的日志或 Telemetry Streaming輸出,及時觸發相關自動化流程對該NGINX下的服務執行個體進行快速擴容,當可用服務執行個體數量恢複大于閥值後,LTM則又開始向該NGINX配置設定新的連接配接。
NGINX Plus本身提供了一個API endpoint,通過擷取該API并做相應處理即可獲得可用的伺服器執行個體數量,在LTM上則可以利用external monitor實施對該API的自動化監控與處理。
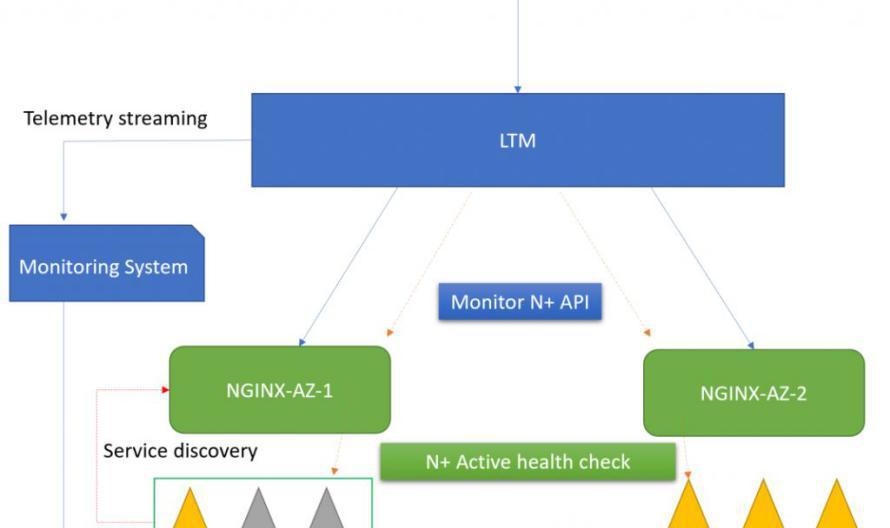
F5給出的負載均衡解決方案的具體操作
1.擷取的API資源路徑是:安裝可在中國使用的VPN。注:api後的版本6可能會因nginx plus的版本不同而不同.
2.傳回的内容示例如下,主要關心state: up, 隻要擷取到總的state: up數量即可
{
"peers": [
"id": 0,
"server": "10.0.0.1:8080",
"name": "10.0.0.1:8080",
"backup": false,
"weight": 1,
"state": "up",
"active": 0,
"requests": 3468,
"header_time": 778,
"response_time": 778,
"responses": {
"1xx": 0,
"2xx": 3435,
"3xx": 6,
"4xx": 20,
"5xx": 4,
"total": 3465
},
"sent": 1511086,
"received": 99693373,
"fails": 0,
"unavail": 0,
"health_checks": {
"checks": 1754,
"fails": 0,
"unhealthy": 0,
"last_passed": true
},
"downtime": 0,
"selected": "2020-01-03T07:52:57Z"
{
"id": 1,
"server": "10.0.0.1:8081",
"name": "10.0.0.1:8081",
"backup": true,
"state": "unhealthy",
"requests": 0,
"2xx": 0,
"3xx": 0,
"4xx": 0,
"5xx": 0,
"total": 0
},
"sent": 0,
"received": 0,
"checks": 1759,
"fails": 1759,
"unhealthy": 1,
"last_passed": false
},
"downtime": 17588406,
"downstart": "2020-01-03T03:00:00.427Z"
}
]
3.可以編寫如下python腳本:
#!/usr/bin/python
# -- coding: UTF-8 --
import sys
import urllib2
import json
def get_nginxapi(url):
ct_headers = {'Content-type':'application/json'}
request = urllib2.Request(url,headers=ct_headers)
response = urllib2.urlopen(request)
html = response.read()
return html
api = sys.argv[3]
try:
data = get_nginxapi(api)
data = json.loads(data)
except:
data = ''
m = 0
lowwater = int(sys.argv[4])
for peer in data['peers']:
state = peer['state']
if state == 'up':
m = m + 1
m = 0
#print data['peers'][]['state']
#print m
if m >= lowwater:
print 'UP'
4.将該腳本上傳至LTM,上傳路徑:system–file management–external monitor–import, 效果如下

5.配置external-monitor, 注意arguments部分填寫:
注意空格前填寫的是相關API的URL,空格後填寫閥值
6.随後将該monitor 關聯到某個nginx pool member上
可以看到,該member 此時标記為up
7.如果将閥值改為3,由于目前upstream中僅有2台可用,是以LTM将标記該NGINX執行個體為down
其它:
輸入錯誤的url或者錯誤的endpoints 等,都直接置為down,這樣使用者可以比較容易發現問題?Upstream中被設定為backup的狀态的成員認為是可用的?此方法還可以避免實際伺服器被LTM和nginx兩次monitor
如果nginx有很多個upstream的話,LTM怎麼設定?
從前端ltm到nginx來說,如果此nginx後端的任何upstream容量不足的話,都不應該給這個nginx再分連結,是以多個upstream的話,可以ltm上設定多個monitor,并設定 all need up。
如果nginx的上的配置有問題,實際業務通路不了,上述方案似乎無法發現此場景問題?
是的,對于nginx本身可用性及配置問題,可考慮在LTM上加一個穿透性的7層健康檢查,但是如果NGINX本身有很多server/location段落配置,又想發現所有這些段落可能存在的問題,那就意味着要對每個服務都進行7層健康檢查,這個在服務特别多場景下,需要思考,或許過度追求探測的完美性會對業務伺服器帶來更多的探測壓力。理論上,LTM上一個穿透性檢查+所有upstream的API檢查,能夠滿足大部分場景。
在大規模NGINX部署場景下,如何降低NGINX健康檢查對後端服務的壓力?
可考慮nginx做動态服務發現app,app的可用性由注冊中心類工具來解決,從分布式的健康檢查變成注冊中心集中式的健康檢查; 或者借助NGINX plus的upstream API 通過集中健康檢查系統來動态性更新upstream,這樣可避免頻繁reload配置, 進而減低健康檢查帶來的壓力。
以上内容就是局部NGINX後業務執行個體過載後F5負載均衡解決方案的實際操作方法,希望對您有所幫助。如果您看完還不會操作,建議聯系F5客服,F5将會快速的,針對性的幫您解決問題。
【文章來源】F5軟體方向解決方案架構師林靜的《F5社群好文推薦:多可用區雙層負載下,如何借助F5避免局部NGINX後業務執行個體過載》。