雲栖号資訊:【 點選檢視更多行業資訊】
在這裡您可以找到不同行業的第一手的上雲資訊,還在等什麼,快來!
引言
大搜車日志分為兩種:業務日志和鍊路日志。
業務日志是業務開發人員在代碼裡面自己列印的日志,為友善開發人員快速查閱分布在多台機器上的日志,我們提供了業務日至平台,供開發自助接入。目前接入的系統 400+,每天産生的日志量 7 億 +,高峰時期每秒要處理 5W+ 的日志。
鍊路日志對應的則是鍊路追蹤平台(trace),通過 traceID 把跨系統調用的所有下遊系統串聯起來,想要了解詳細的話可以參考開源的 pinpoint 。 鍊路日志每天日志量 30 億 +,高峰每秒要處理 8W+ 的日志。我們隻保留七天的資料,大概 45T。
開源社群有很多優秀的日志收集元件,如 logkit,logstack,flume 等。我們公司因為早前就在其它場景下使用過 flume,運維同學也積累了豐富的運維經驗,是以采集元件直接使用的 flume。個人感覺而已,logkit 和 logstack 更輕量,作為采集端更合适~
下面開始進入正題,介紹下我們的整體架構以及遇到的坑,還有就是根據自身的業務特點做的特殊優化~
整體架構圖
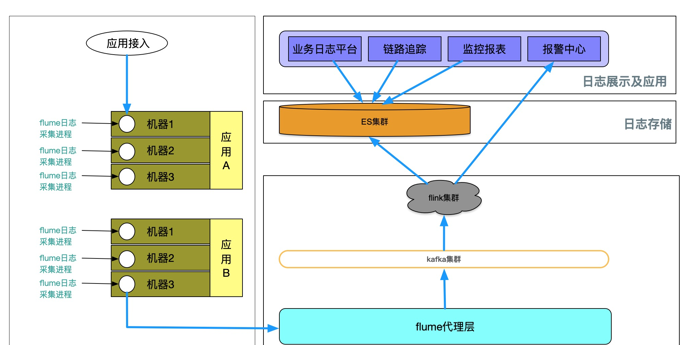
詳細說明
如上圖所示,整體上分為四個子產品:日志采集,日志處理,日志存儲以及展示和應用,下面開始詳細介紹每個子產品。
日志采集
日志采集最大的難題就是業務日志在機器山存放的路徑以及檔案名稱并不統一 (運維最開始沒有制定标準),而且日志格式和滾動政策等都是業務開發人員自己配置的。是以接入我們的系統需要使用方自己錄入日志存放目錄以及通過 正規表達式 指定日志格式 (如下圖)。 配置好日志目錄和格式,系統會把這些配置推送給 flume(開源版本不支援該推送配置的功能,我們修改了開源版本使其支援),日志采集就開始了。

第一步我就遇到了一個大坑,先說現象:有的應用莫名其妙的最新日志就收集不上來了,登入到機器上檢視,發現采集程序還在,用 top 指令檢視,發現日志采集程序占用 cpu 達到 100%
cpu100% 問題排查我就不詳訴了, 可以點超連結自行檢視。通過線程堆棧,可以看到是正規表達式在搞鬼。這裡需要引入正規表達式的執行原理:
傳統的 NFA 引擎運作所謂的“貪婪的”比對回溯算法(longest-leftmost),以指定順序測試正規表達式的所有可能的擴充并接受第一個比對項。傳統的 NFA 回溯可以通路完全相同的狀态多次,在最壞情況下,它的執行速度可能 非常慢,但它 支援子比對。代表性有:GNU Emacs,Java,ergp,less,more,.NET 語言, PCRE library,Perl,PHP,Python,Ruby,sed,vi 等,一般進階語言都采用該模式。
在通過下面這個執行個體了解下:
源字元 DEF, 比對正規表達式是:/Dw+F/
比對開始:
第一步,/D 正确比對到 D, 而w+ 會貪婪的比對最長的字元串,也就是 EF。然後 F 因為比對不到任何字元,導緻比對失敗。
第二步,因為上面的比對失敗了,回溯算法往後退一位, /D 正确比對到 D, 而w+ 比對到 E,F 比對到 F, 比對成功。
上面的例子因為源字元串比較短,正規表達式也不複雜,是以隻回溯了一次。但是我們的真實場景一條業務日志長度幾百設定上千,而使用者寫的正則可能不止 有w+,還會有.+ 等等。是以這也就造成了上面的問題,最新日志收集不上來(解析日志耗費的時間太長了),而且 CPU100%(因為一直在運算,并不是卡住)。
明确了問題直接上解決方案吧,不想鋪墊了。。。
第一步就是要快速失敗,如果解析一條日志超過 100ms,就應該把它歸類為解析失敗,繼續後面的日志處理。是以可以把日志解析丢到異步線程池中,主線程通過拿到的 Future 控制逾時時間。
第二步就是如果逾時了,要能夠中斷正在比對的正規表達式。這個時候遇到的問題是正規表達式本身是不響應中斷,不過好在天無絕人之路,觀察發現正規表達式源字元串要求傳入的類型是 CharSequence,而每次回溯時,都會調用 charAt 方法,是以可以通過建立一個新的類,實作 CharSequence,并且在 charAt 中判斷是否被中斷。這樣的話,就可以讓正規表達式的解析過程響應中斷了~~,CharSequence 實作類代碼如下
public class InterruptibleCharSequence implements CharSequence {
CharSequence inner;
public InterruptibleCharSequence(CharSequence inner) {
super();
this.inner = inner;
}
@Override
public char charAt(int index) {
if (Thread.currentThread().isInterrupted()) {
throw new RuntimeException("Interrupted!");
}
return inner.charAt(index);
}
@Override
public int length() {
return inner.length();
}
@Override
public CharSequence subSequence(int start, int end) {
return new InterruptibleCharSequence(inner.subSequence(start, end));
}
@Override
public String toString() {
return inner.toString();
}
} 日志處理
所有機器上的 flume 采集程式,收集到的日志會先上報給單獨搭建的 flume 代理層叢集,這是因為運維不希望太多的機器直連 kaka。代理層沒有做任何處理,直接把日志丢到 kafka。
kafka 的性能和穩定性是經過曆史驗證的,是以選它作為中間緩存層沒什麼争議。當然,其它的 mq 也更有優勢,可以根據公司技術棧靈活選擇。像号稱下一代的 mq:pulsar 我們也打算調研試用下~
為什麼不直接寫後端的 ES 呢?這是因為需要緩沖層來削峰填谷,可能有點抽象,舉個實際的例子,我們的業務高峰期,日志的産生速度高于 ES 的寫入速度。業務系統那邊基本都會配置了日志檔案翻滾,這樣就有可能造成還沒來得及收上來的日志被沖掉了。
kafka 後面挂的是 flink 叢集,上面跑了四個 job:
業務日志 Job: 負責存儲業務日志
鍊路日志的 Job:負責存儲鍊路日志
監控報表的 Job: 主要是統計一些名額,如 qps,錯誤率等等,利用到了 flink 的視窗
報警中心的 Job:業務日志可以根據使用者自定義的報警規則報警,而鍊路日志則可以對架構層面的逾時,錯誤報警,如 dubbo 調用逾時~
日志存儲
日志存儲主要是把資料寫入 ES,單獨來講是因為不同的産品存儲方式不同。這塊也是整個系統最大的短闆,為了優化寫入做了很多工作。
業務日志存儲
首先分析下業務日志的場景,大家基本上隻檢視自己應用的日志,痛點是可能分布在不同的機器上,經常使用的姿勢是根據關鍵字全文比對。而且以前使用 kibana 的時候,因為分詞導緻查詢出來的結果不精确很不爽。
針對這個特點,我們設計的後端存儲方式是:每個應用每天一個索引,同時建立索引的時候通過 MappingTemplate 禁用掉分詞。
優缺點: 這是設計方式是面向單應用查詢的,是以查詢速度比較快,而且是全文比對的暴力查詢,使用者體驗比較好。但是也導緻了 ES 叢集中索引的數量過多,會多占用一些記憶體。
還有一個小坑,是關于限流功能的。我們想實作的功能是,針對打日志特别多的應用,比如說一天打幾千萬條的日志,超過門檻值就自動限流該應用,後面的日志就不采集了。 統計應用每天的日志量,是放在 flink 叢集做的,但是實際應用中發現,當 flink 統計到某個應用采集量已經達到上限,比如說 1000W,想要限流已經為時已晚,因為這時候這個應用可能已經有 5000W 日志堆在 kafka 了。 也就是說,在 flink 叢集統計有嚴重的滞後性,後來我們又在 flume 采集的時候增加了單機限流。
鍊路日志存儲
鍊路日志的資料量特别龐大,同時因為經常需要跨系統查詢,是以不能按照系統的次元建索引。不過相對于業務日志,因為都是架構層面列印的,是以格式是統一的。針對這種特點,按照每小時建一個索引,保證索引資料量不會太大。Mapping 政策上,也是禁用分詞,提前解析出(應用,路徑,環境,線程)字段,讓 ES 索引起來。這樣使用者在界面上根據這些字段過濾就會有比較好的性能表現。
其它的寫入性能優化
在接入量快速增長的階段,ES 首先扛不住了,寫入性能無法滿足快速增長的日志量。雖然可能通過加機器緩解問題,但成本也要控制,是以優化 ES 寫入性能迫在眉睫,下面列出的是實踐過程中最有效的方式,其它的可以自行百度~
- 增大刷盤時間 (refresh_interval): 預設是 1s,我們時間過程中調到了 5s。調大之後寫入性能上升還是比較明顯的,帶來的問題是日志寫入 5s 之後才能被查詢到,不過 5s 延遲延遲業務上是完全可以接受的。
- 0 備份并且關掉事務日志(“durability”: “async”):這個對寫入性能的提高是大幅度的,幾乎是兩倍的提升,我們的叢集最高可以寫到 15W+。但是問題是無法保證可靠性,萬一挂了怎麼辦? 我們的解決方式是 kafka 儲存 12 小時的資料 + 低峰期(晚上)備份。 首先 kafka 儲存 12 小時的資料保證了即使 flink 挂了或者 ES 挂了,都可以通過重置消費位點把資料找回來。晚上備份的話,保證了十二小時之前的資料就不會丢了
- 提前建立索引:業務日志每到晚上零點的時候,都會堆積資料。這是因為這個時候在大量的建立索引,寫入速度自然受影響。解決思路就是提前把索引建立好
- 第三方幂等:首先說明這個我還沒嘗試過,因為現在寫入性能夠了,就沒怎麼在折騰,思路寫出來供大家參考。 我們為了防止 ES 資料重複寫入,是通過指定 id 的方式實作了幂等。這個對 ES 性能消耗還是比較大的(大概 15%)。并且 index 的資料規模越大,性能越低,因為它要判斷這個 id 是否已經存在。 如果把這個幂等控制拿到外面去做,讓 ES 直接存就好了,性能肯定有進一步提升
日志應用
日志展示
可以根據關鍵字或者過濾條件快速搜尋日志,免去了登入多台機器的麻煩
日志報警
把查詢條件設定為報警規則,如下圖,10 分鐘類日志中出現 Exception 關鍵字,次數大于 1 次,将觸發報警。技術實作是通過 flink,擴充視窗機制,實作了動态視窗(有時間這塊可以詳細寫下)。
資料大盤
基于 trace 日志形成的資料大盤,QPS、耗時百分位圖等資訊,詳細可以看另一片文章。
【雲栖号線上課堂】每天都有産品技術專家分享!
課程位址:
https://yqh.aliyun.com/zhibo立即加入社群,與專家面對面,及時了解課程最新動态!
【雲栖号線上課堂 社群】
https://c.tb.cn/F3.Z8gvnK
原文釋出時間:2020-04-01
本文作者:楊光躍
本文來自:“
InfoQ”,了解相關資訊可以關注“
”