雲栖号資訊:【 點選檢視更多行業資訊】
在這裡您可以找到不同行業的第一手的上雲資訊,還在等什麼,快來!
随着 Netflix 原創内容的逐年增長,我們要建構一些可提升整個創作過程效率的應用。我們的一個大型部門,Studio 工程組織已經建構衆多應用,去幫助從劇本制作到内容播出的全套流程,涉及的環節涵蓋劇本内容擷取、交易談判和供應商管理,以及日程安排、簡化生産流程等。
從開始就高度內建
大約一年前,我們的 Studio 流程團隊開始開發一款跨多個業務領域的全新應用。
當時,我們面臨一項有意思的挑戰:
一方面我們需要從頭開始建構應用的核心,另一方面我們所需的資料分布在衆多不同的系統之中。
我們所需要的一些資料,比如有關影片資訊、制作日期、員工和拍攝地點的資料,分布于許多服務中。并且,它們使用的協定也各有不同,包括 gRPC、JSON API、GraphQL 等等。
對我們應用程式的行為和業務邏輯而言,已有資料非常重要。我們從一開始就需要高度內建。
可切換資料源
早期的一款應用程式用來為我們的産品引入可見性,它被設計為單體架構。
在領域知識體系尚未建立的情況下,單體架構可以實作快速開發和快速變更。後來,使用它的開發人員超過 30 人,有超過 300 個資料庫表。
随着時間流逝,應用程式從涉及面廣泛的服務演變成高度專業化的産品。在這樣的背景下,團隊決定将單體架構解構為一系列專用服務。
做出這一決策并非性能問題,而是要對所有這些領域設定界限,并讓各個專屬團隊能獨立開發針對每個特定領域的服務。
我們的新應用所需的大量資料依舊是之前的單體提供的,但我們知道這個單體将在某一天分解開來。我們不能确定具體時間,但知道這一時刻不可避免,是以需要做好準備。
這樣的話,我們能在一開始利用某些來自單體的資料,因為它們仍然是可信來源;但我們也要做好準備,在新的微服務上線後立刻切換到這些資料源上。
利用六邊形架構
我們需要有在不影響業務邏輯的前提下切換資料源的能力,是以我們需要讓它們保持解耦狀态。
我們決定基于六邊形架構的原則來建構應用。
六邊形架構的思想是将輸入和輸出都放在設計的邊緣部分。不管我們公開的是 REST 還是 GraphQL API,也不管我們從何處擷取資料——是通過資料庫、通過 gRPC 還是 REST 公開的微服務 API,或者僅僅是一個簡單的 CSV 檔案——都不應該影響業務邏輯。
這種模式讓我們能将應用程式的核心邏輯與外部的關注點隔離開來。核心邏輯隔離後,意味着我們可以輕松更改資料源的細節,而不會造成重大影響或需要在代碼庫重寫大量代碼。
我們還看到,在應用中具有清晰邊界的另一大優勢就是測試政策——我們的大多數測試在驗證業務邏輯時,都不需要依賴那些很容易變化的協定。
定義核心概念
借鑒六邊形架構,定義我們業務邏輯的三大概念分别是實體、存儲庫和互動器。
- 實體(Entities)指的是域對象(例如一部影片或一個拍攝地點),它們不知道自身的存儲位置(不像是 Ruby on Rails 中的 Active Record 或者 Java Persistence API 那樣)。
- 存儲庫(Repositories)是擷取實體及建立和更改實體的接口。它們儲存一系列方法,用來與資料源通信并傳回單個實體或實體清單。(例如 UserRepository)
- 互動器(Interactors)是用來編排和執行域動作(domain action)的類——可以考慮服務對象或用例對象。它們實作複雜的業務規則和針對特定域動作(例如上線一部節目)的驗證邏輯。
有了這三大類對象,我們就可以在定義業務邏輯時無需知曉或者關心資料的存儲位置,也不用理會業務邏輯是怎樣觸發的。業務邏輯之外是資料源和傳輸層:
- 資料源(Data Sources)是針對不同存儲實作的擴充卡(Adaptor)。資料源可能是 SQL 資料庫的擴充卡(Rails 中的 Active Record 類或 Java 中的 JPA)、彈性搜尋擴充卡、REST API,甚至是諸如 CSV 檔案或 Hash 之類的簡單擴充卡。資料源實作在存儲庫上定義的方法,并存儲擷取和推送資料的實作。
- 傳輸層(Transport Layer)可以觸發互動器來執行業務邏輯。我們将其視為系統的輸入。微服務最常見的傳輸層是 HTTP API 層和一組用來處理請求的控制器(Controller)。将業務邏輯提取到互動器後,我們就不會耦合到特定的傳輸層或控制器實作上。互動器不僅可以由控制器觸發,還能由事件、cron 作業或從指令行觸發。
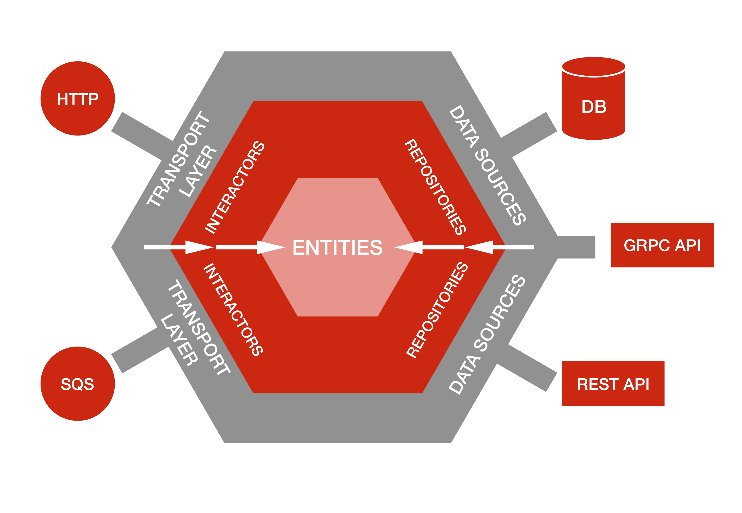
在傳統的分層架構中,我們所有的依賴項都會指向一個方向,上面的每一層都會依賴自己下面的層。傳輸層會依賴互動器,而互動器會依賴持久存儲層。
在六邊形架構中,所有依賴項都指向中心方向。我們的核心業務邏輯對傳輸層或資料源一無所知。但傳輸層仍然知道如何使用互動器,資料源也知道如何對接存儲庫接口。
這樣,我們就可以為将來切換到其他 Studio 系統的更改做好準備,并且當需要邁出這一步時,我們很容易就能完成切換資料源的任務。
切換資料源
切換資料源的需求比我們預期來得更早一些——我們的單體架構突然遇到一個讀取瓶頸,并且需要将某個實體的特定讀取切換到一個在 GraphQL 聚合層上公開的新版微服務上。這個微服務和單體保持同步,資料相同,并且它們從各個服務中讀取時産生的結果也是一緻。
我們設法在 2 小時内就将資料讀取從一個 JSON API 切換到一個 GraphQL 資料源上。
我們之是以能如此快地完成這一操作,主要歸功于六邊形架構。我們沒有讓任何持久存儲細節洩漏到業務邏輯中。我們建立了一個實作存儲庫接口的 GraphQL 資料源。是以,隻需要做簡單的一行代碼更改,即可開始從新的資料源讀取資料。

到這個時候,我們就知道使用六邊形架構沒錯了。
單行代碼更改有一大優勢,那就是它可以減小釋出風險。如果下遊微服務在初始部署時失敗,復原也會非常容易。這也讓我們能解耦部署和激活作業,因為可以通過配置來決定使用哪個資料源。
隐藏資料源細節
這種架構的一大優勢是讓我們能封裝資料源的實作細節。
我們遇到這樣一種情況:有一次,我們需要一個尚不存在的 API 調用——有一個服務用一個 API 來擷取單個資源,但沒有實作批量擷取。與提供該 API 的團隊交流後,我們得知這個批量擷取端點需要一些時間才能傳遞。是以,我們決定在這個端點建構的同時,使用另一種方案來解決這個問題。
我們定義了一個存儲庫方法,該方法可以在給定多個記錄辨別符的情況下擷取多個資源——并且該方法在資料源的初始實作會向下遊服務發送多個并發調用。我們知道這是一個臨時的解決方案,資料源實作的下一步改進是在批量 API 建構完畢後切換到新 API 上。
這樣的設計讓我們能繼續開發以滿足業務需求,同時不會積累太多技術債,也無需事後更改任何業務邏輯。
測試政策
當我們開始嘗試六邊形架構時,就知道需要提出一種測試政策。要提升開發速度的先決條件就是擁有可靠且非常快的測試套件。我們不認為這是錦上添花,而是必要條件。
我們決定在三個不同的層上測試應用:
- 我們測試了互動器,業務邏輯的核心存在于此,但與任何類型的持久層或傳輸層無關。我們用上了依賴注入,并 mock 任意類型的存儲庫互動。在這裡我們詳細測試業務邏輯,大部分測試都位于此處。
- 我們測試資料源,以确定它們是否與其他服務正确內建,它們是否對接上存儲庫接口,并檢查它們在出現錯誤時的行為。我們試着盡量減少這些測試的數量。
- 我們具有遍及整個棧的內建規範,從我們的 Transport/API 層到互動器、存儲庫、資料源以及重要的下遊服務全部包含在内。這些規範測試的是我們是否正确“布線”了一切。如果一個資料源是一個外部 API,我們将命中該端點并記錄響應(并将其存儲在 git 中),進而讓我們的測試套件可以在每次後續調用時快速運作。我們不會在這一層進行廣泛測試,通常每個域動作隻有一個成功場景和一個失敗場景。
我們不會測試存儲庫,因為它們是資料源實作的簡單接口;并且我們很少測試實體,因為它們是定義了屬性的普通對象。我們會測試實體是否有其他方法(這裡不涉及持久層)。
我們還有改進空間,比如我們将來可以不 ping 所依賴的任何服務,而是 100%依賴合同測試。有了上述方式編寫的測試套件,我們可以 100 秒内在單個過程中運作大約 3000 個 specs。
能輕松在任何機器上運作的測試套件,它用起來非常棒,我們的開發團隊可以在不中斷的前提下做日常功能測試。
延遲決策
現在我們可以輕松将資料源切換到不同的微服務上。關鍵的一大好處是,我們能延遲一些關于是否以及如何存儲應用程式内部資料的決策。根據功能用例,我們甚至可以靈活确定資料存儲的類型——可以是關系型也可以是文檔型。
當這個項目開始時,我們對正在建構的這個系統的了解是非常少的。我們不應該将自己鎖定在一個會導緻項目悖論和不明智決策的架構中。
我們現在做的決策符合我們需求,并且讓我們能快速行動。六邊形架構的最大優點在于,它可以讓我們的應用程式靈活适應未來需求。
【雲栖号線上課堂】每天都有産品技術專家分享!
課程位址:
https://yqh.aliyun.com/zhibo立即加入社群,與專家面對面,及時了解課程最新動态!
【雲栖号線上課堂 社群】
https://c.tb.cn/F3.Z8gvnK
原文釋出時間:2020-03-26
本文作者:Netflix技術部落格
本文來自:“
InfoQ”,了解相關資訊可以關注“
”