前言
InfluxDB作為
DB-Engines上排名第一的時序資料庫,從設計和實作上都針對時序資料的特性進行了優化,其高成本效益特性與資料壓縮有着直接關系,本文将介紹InfluxDB使用的資料壓縮算法。
資料存儲模型
首先簡單介紹下時序資料在influxdb中是如何存儲的。
時序資料場景中,每個資料點都包含資料值和時間戳,以及measurement和tag-set組成的series key,比如下面的例子中,第一個空格前面的部分就是series key,後面跟着的是值和時間戳:
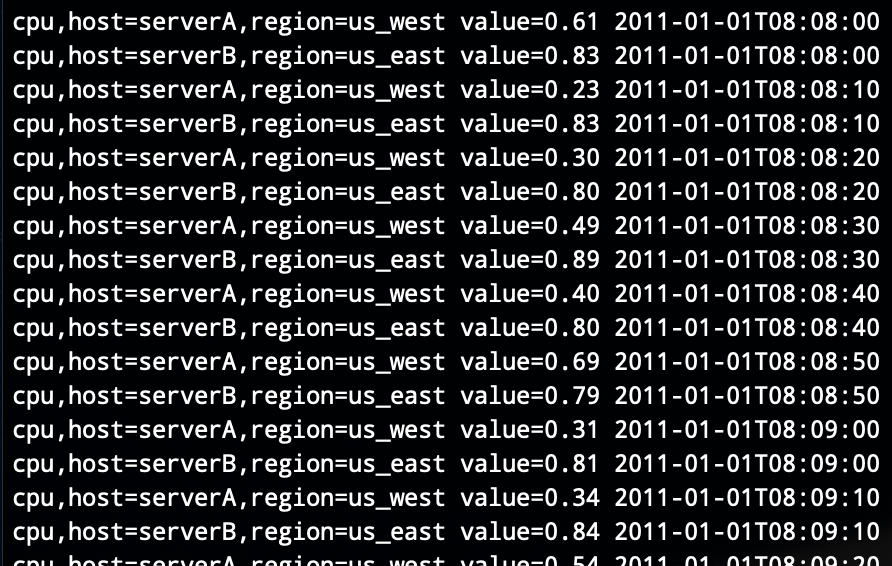
InfluxDB的資料存儲是基于series key來組織的,上面的資料有兩個series key(對應兩台主機)。

每個series key對應的資料根據時間戳進行排序後,以一個block進行存儲;存儲是列式的,即時間戳和資料是獨立存儲的:
下面讨論的壓縮算法就是針對時間戳和值進行無損壓縮。
壓縮算法
InfluxDB中值是有類型的,目前支援整形,浮點數,布爾類型和字元串四種類型,而時間戳是64位整形,壓縮算法是根據不同的資料類型來選擇的。
時間戳
時間戳都是64位的無符号整數,其編碼方式是自适應的:
- 因為時間戳是排序的,首先進行delta編碼,第一個資料不變,其他資料轉換為與上一個資料的delta;同時計算出10為因子的最大公約數。
- 如果最大值(即最後一個原始值與第一個原始值的差)過大(超過1 << 60,大約36年,基本不會出現),則不壓縮,直接存儲數組。否則,
- 如果delta都相同,就直接使用遊程編碼,隻記錄第一個值,delta值,以及數量即可。一般監控資料都是定時采集的,比如十秒一個點,那遊程編碼方式可以達到很高的壓縮比;否則
- 所有的delta值都除以最大公約數(最大公約數是編碼在資料中的),然後使用simple8b算法進行編碼。
simple8b是一種整數編碼算法,2010年由墨爾本大學的一位博士生提出的。simple8b将多個整數(0到1<<60-1 之間)打包到一個64位的整數中,其中前4位用作selector,用來标記每個值使用多少bit。
浮點數
浮點型的資料編碼方式采用了facebook的Gorilla算法,較長的描述可以參考
paper或者内網的
翻譯,這裡僅簡單介紹下。
多數時序場景下相鄰值變化不大,浮點數也不會有明顯的變化,Gorilla也采用了delta編碼原理,但是與整形的delta編碼不同,Gorilla使用XOR來計算兩個浮點值的差異。
首先我們看下常用的浮點數機器編碼,也就是ieee754标準:
符号位和指數位在高位,是以相近的值高位是相同的,XOR的值會有很多高位的零。XOR的值會再進行變長編碼。
整形
整數類型也是基于資料特征自适應地選擇兩種編碼方式。
- 首先使用zig-zag編碼資料,将有符号整數編碼成無符号整形
- 如果所有的delta都相同,則使用遊程編碼,否則
- 如果可以使用simple8b,則使用simple8b算法編碼(與時間戳編碼一樣),否則
- 不壓縮直接存儲
zigzag編碼是一種針對有符号數的變長編碼,其計算十分簡單:
(n << 1) ^ (n >> 63) 也就是将符号位移動到最後面,這樣絕對值小的數在變長編碼中可以占用更少的位,編碼效果如下:
布爾類型
布爾值使用簡單的bit pack方式編碼,每個值使用1位,沒有使用二次壓縮。
字元串
使用snappy算法進行編解碼。Google snappy的設計原則不是追逐壓縮比,而是更看中壓縮性能。代碼實作上,snappy也針對x86系統做了優化,比如使用little-endian,使用SSE指令直接操作128bit的整數,等等。influxdb使用go語言開發,snappy是實作中直接使用了x86彙編語言。