Scrapy是一個比較好用的Python爬蟲架構,你隻需要編寫幾個元件就可以實作網頁資料的爬取。但是當我們要爬取的頁面非常多的時候,單個伺服器的處理能力就不能滿足我們的需求了(無論是處理速度還是網絡請求的并發數),這時候分布式爬蟲的優勢就顯現出來。
而Scrapy-Redis則是一個基于Redis的Scrapy分布式元件。它利用Redis對用于爬取的請求(Requests)進行存儲和排程(Schedule),并對爬取産生的項目(items)存儲以供後續處理使用。scrapy-redi重寫了scrapy一些比較關鍵的代碼,将scrapy變成一個可以在多個主機上同時運作的分布式爬蟲。
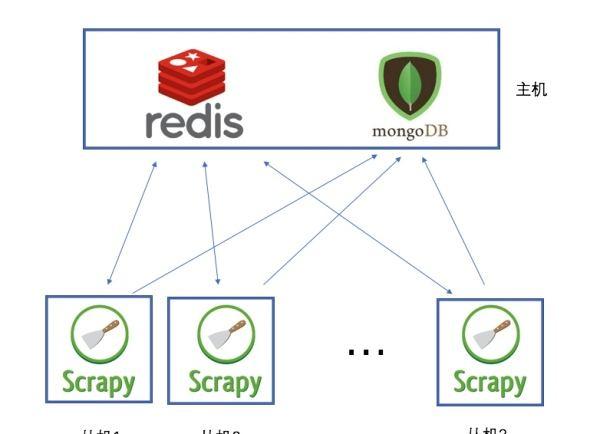
說白了,就是使用redis來維護一個url隊列,然後scrapy爬蟲都連接配接這一個redis擷取url,且當爬蟲在redis處拿走了一個url後,redis會将這個url從隊列中清除,保證不會被2個爬蟲拿到同一個url,即使可能2個爬蟲同時請求拿到同一個url,在傳回結果的時候redis還會再做一次去重處理,是以這樣就能達到分布式效果,我們拿一台主機做redis 隊列,然後在其他主機上運作爬蟲.且scrapy-redis會一直保持與redis的連接配接,是以即使當redis 隊列中沒有了url,爬蟲會定時重新整理請求,一旦當隊列中有新的url後,爬蟲就立即開始繼續爬
首先分别在主機和從機上安裝需要的爬蟲庫
pip3 install requests scrapy scrapy-redis redis
在主機中安裝redis
點我領取阿裡雲2000元代金券 ,(阿裡雲優惠券的作用:購買阿裡雲産品,最後支付結算的時候,阿裡雲優惠券可抵扣一部分費用。安裝redis
yum install redis
啟動服務
systemctl start redis
檢視版本号
redis-cli --version
設定開機啟動
systemctl enable redis.service
修改redis配置檔案 vim /etc/redis.conf 将保護模式設為no,同時注釋掉bind,為了可以遠端通路,另外需要注意阿裡雲安全政策也需要暴露6379端口
改完配置後,别忘了重新開機服務才能生效
systemctl restart redis
然後分别建立爬蟲項目
scrapy startproject myspider
在項目的spiders目錄下建立test.py
導包
import scrapy
import os
from scrapy_redis.spiders import RedisSpider
定義抓取類
class Test(scrapy.Spider):
class Test(RedisSpider):
#定義爬蟲名稱,和指令行運作時的名稱吻合
name = "test" 定義redis的key
定義redis的key
redis_key = 'test:start_urls'
定義頭部資訊
定義頭部資訊
haders = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/73.0.3683.86 Chrome/73.0.3683.86 Safari/537.36' }
def parse(self, response):
print(response.url)
pass 然後修改配置檔案settings.py,增加下面的配置,其中redis位址就是在主機中配置好的redis位址:
BOT_NAME = 'myspider'
SPIDER_MODULES = ['myspider.spiders']
NEWSPIDER_MODULE = 'myspider.spiders'
設定中文編碼
FEED_EXPORT_ENCODING = 'utf-8'
scrapy-redis 主機位址
REDIS_URL = 'redis://[email protected]:6379'
隊列排程
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
不清除緩存
SCHEDULER_PERSIST = True
通過redis去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
不遵循robots
ROBOTSTXT_OBEY = False
最後,可以在兩台主機上分别啟動scrapy服務
此時,服務已經起來了,隻不過redis隊列中沒有任務,在等待狀态
進入主機的redis
redis-cli
将任務隊列push進redis
lpush test:start_urls
https://yq.aliyun.com/go/articleRenderRedirect?url=http%3A%2F%2Fbaidu.com http://baidu.com https://yq.aliyun.com/go/articleRenderRedirect?url=http%3A%2F%2Fchouti.com http://chouti.com可以看到,兩台伺服器的爬蟲服務分别領取了隊列中的任務進行抓取,同時利用redis的特性,url不會重複抓取

爬取任務結束之後,可以通過flushdb指令來清除位址指紋,這樣就可以再次抓取曆史位址了。
阿裡雲伺服器: 活動位址
購買可領取:
阿裡雲代金券