作者:閑魚技術-景松
背景
使用者來閑魚,主要是為了獲得自己關心的内容。随着閑魚的體量越來越大,内容也變得越來越豐富。閑魚基于使用者畫像,可以将使用者關心的内容推送給使用者。例如,租客在浏覽租房首頁時,在特定的場景下,閑魚會給使用者推送超值的房源資訊,進而提高使用者的租房效率。具體在哪些場景下才需要觸發推送?我們定義了很多觸發規則,包括停留時長、點選路徑等。
開始我們把觸發規則的邏輯放在服務端(Blink)運作。但實踐下來發現,Blink存在諸多限制。首先,服務端要對用戶端埋點進行資料清洗,考慮到閑魚的DAU已經突破2000w,這個量是非常龐大的,非常消耗服務端資源;于此同時,Blink的政策是實時執行的,同樣因為資源問題,現在隻能同時上線十幾個政策。
如何解決這些問題呢?是以,我們就在考慮能否将Blink的政策跑在用戶端!
CEP模型
Blink,作為是Flink的一個分支,最初是阿裡巴巴内部建立的,針對Flink進行了改進,是以我們這裡還是圍繞Flink讨論。CEP(Complex Event Process)是Flink中的一個子庫,用來快速檢測無盡資料流中的複雜模式。
Flink CEP
Flink的CEP的核心是NFA(Non-determined Finite Automaton),全稱叫不确定的有限狀态機。提到NFA,就不得不提Jagrati Agrawal等撰寫的關于NFA模型的論文
《Efficient Pattern Matching over Event Streams》,本篇論文中描述了NFA的比對原理。
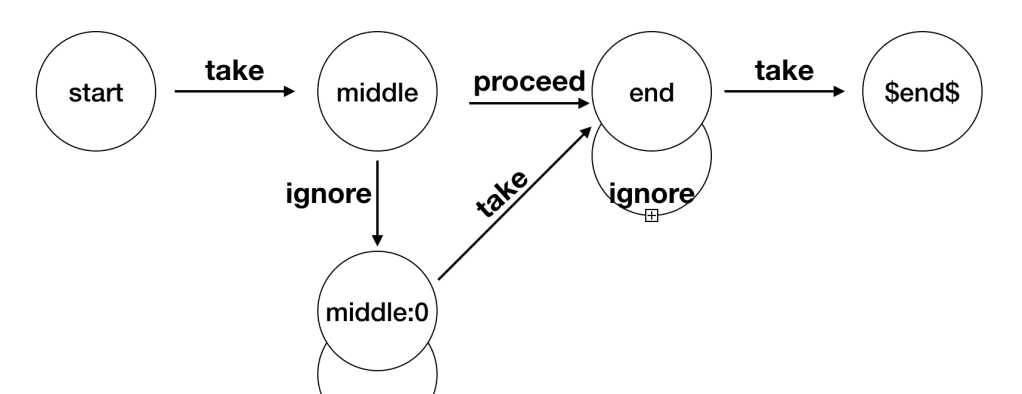
上面這張圖,就是一個不确定的有限狀态機,它由狀态(State)還有之間的連線(StateTransition)組成的。
- 狀态(State):狀态是根據flink腳本裡面的代碼來決定的,最終會有一個
$end$
- 轉換(StateTransition):State的轉換條件,包括
take/proceed/ignore
不同的條件,代表的含義不同:
-
take
-
proceed
-
ignore
我們隻要在端上實作這樣一個狀态機,就可以實作一個CEP引擎。
Python CEP
對于用戶端來說,首先要解決的問題是如何建構一個CEP環境。經過調研,可以複用集團的端智能容器(Walle),作為Python容器可以執行cep的政策。
在建構NFA之前,首先要解決的一個問題是資料來源,手淘資訊流團隊有一套完整的解決方案BehaviX/BehaviR,可以對UT埋點進行結構化,能很好的結合Walle容器來觸發政策。有了事件來源,還需要解決的是Python腳本如何執行。Walle平台可以将多個Python腳本打包下載下傳并執行,是以,我們可以将CEP封裝成一個Python的庫,然後跟政策腳本一起下發。
最終的整體架構設計如下圖所示:

本片文章重點介紹下如何用Python來實作一個CEP的編譯器,這個編譯器主要用來将CEP的描述語言轉換成為NFA。
編譯器原理
在Flink中,java側會有一套完善的API來編寫一個政策腳本,《efficient Pattern Matching over Event Streams》論文中還定義了一套完備的DSL描述語言,也是會轉化成java檔案去調用這些API去完成比對。那麼接下來會重點讨論,flink是如何将上述API轉化成NFA去比對,以及Python CEP如何實作上述一套完整API接口。
Pattern
在Flink裡面,是通過
Pattern
來建構這個NFA,首先用它描述這個不确定性狀态機。首先是建構一個
Pattern
的一個連結清單,得到這個連結清單之後,會将每個Pattern映射成為
State
的圖,點與點之間會通過
StateTransition
來連接配接。以下面的Python代碼為例,看下如何API是如何工作的:
例如,需要建立這樣一個規則,描述如下:
以start事件開始,後續跟随一個middle的事件,後面緊跟着一個end事件作為結尾
用Pattern編寫如下所示:
Pattern.begin("start").where(SimpleCondition())\
.followed_by('middle').where(SimpleCondition())\
.next_('end').where(SimpleCondition()) 這個代碼裡面聲明了3個Pattern,依次命名為
start
、
middle
end
。Pattern裡面儲存了指向前面節點的引用
previous
,整個Pattern連結清單建構完如下圖所示:
最終拿到的是
end
節點的一個引用
Ref
,Pattern中會有一個變量指向前一個節點,這樣就可以得到一個Pattern的反向連結清單。
Pattern的對外接口定義如下:
class Pattern:
# 靜态方法,用來生成起始的pattern
@staticmethod
def begin(self, name):
pass
# 标記緊接着的事件
def followed_by(self, name):
pass
# 标記不需要緊跟的事件
def not_followed_by(self, name):
pass
# 标記緊跟的事件
def next_(self, name):
pass
# 标記事件循環次數
def times(self, times):
pass
# 标記目前事件觸發的條件
def where(self, condition):
pass
# 标記目前事件的and條件
def and_(self, condition):
pass
# 标記目前事件的or條件
def or_(self, condition):
pass
# 用于聚合
def group_by(self, fields):
pass
# 用于聚合,管道特定字段的值
def fields(self, key_by_state_name, field):
pass
# 用于聚合,統計事件具體的數量
def count(self, field, condition):
pass 不同接口會生成不同的消費政策的節點,具體細節可以參考
StateTransition
。有了Pattern連結清單,接下來就需要編譯器(Compiler)了,它主要是将Pattern連結清單轉化成NFA圖,首先來看下NFA的2個核心元件:
State
和
StateTransition
。
State
結構定義如下:
class State(object):
def __init__(self, name, state_type):
self.__name = name # 節點的名稱,同Pattern的名稱
self.__state_type = state_type # 節點的類型:Start/Normal/Stop/Final
self.__state_transitions = [] # 到其他節點的邊 State一共有4種類型:
Start/Final/Normal/Stop
生成NFA的過程就是将反向解析Pattern連結清單的過程,大概的過程如下:
- 建立一個
$end$
Final
- 再從後往前建立每個state節點,作為中間節點(
Normal/Stop
- 最後建立一個開始節點(
Start
State的名稱就是Pattern的節點名稱,建立完成之後如下圖所示。
Transition
State代表了目前狀态機的狀态,不同狀态之前的切換定義成
StateTransition
class StateTransition:
def __init__(self, source_state, action, target_state, condition):
self.__source_state = source_state # 開始的State節點
self.__action = action # 具體action類型:take/ignore/proceed
self.__target_state = target_state # 結束的State節點
self.__condition = condition # 節點之間的判斷條件 邊的生成邏輯跟Pattern的事件消費政策相關,以下是事件消費政策:
class ConsumingStrategy:
STRICT = 0 # 嚴格比對下個
SKIP_TILL_NEXT = 1 # 跳過下一個
SKIP_TILL_ANY = 2 # 跳過任意一個
NOT_FOLLOW = 3 # 非跟随模式
NOT_NEXT = 4 # 非緊鄰模式 不同的消費政策,得到的狀态機如下圖所示:
-
STRICT
-
SKIP_TILL_NEXT
-
SKIP_TILL_ANY
-
NOT_FOLLOW
-
NOT_NEXT
在Pattern中,不同的接口會建立出不同的消費政策節點,例如
followed_by
接口會建立
SKIP_TILL_NEXT
的節點。
Times
如果有的規則,要求特定的事件,循環出現幾次,那現在就要用到times接口。比如浏覽3次寶貝這個規則,規則就可以寫成:
Pattern.begin('e1').where(SimpleCondition()).times(3); 最終就會得到一個
Times = 3
的Pattern,編譯器在拿到這個Pattern之後,一樣先建立一個$end$的Final節點,在處理times的時候,會建立重複的節點,隻不過名稱不同,不同的點之間用take連結起來,如下圖所示:
Python CEP聚合
Flink是通過InputStream将比對的事件轉移給CEPOperator,執行聚合操作;但是在用戶端的聚合,一次執行就一個事件流,是以可以将聚合簡化到一次比對過程中,是以我們對于Flink的聚合操作做了改造,使其更适合端上的場景。
那麼聚合的腳本寫法如下:
_pattern = Pattern.begin("start").where(self.start_filter)\
.followed_by('middle').where(SimpleCondition())\
.next_('end').where(self.end_filter)\
.group_by('group_by').fields('start', 'userId') 這裡聲明了,以
start
節點中的
userId
作為聚合的節點,我們就會得到如下的
Pattern
連結清單:
在解析
group_by
節點的時候,我們需要做個特殊處理,判斷如果有聚合節點,我們就需要再
$end$
節點和前面節點之間插入一個聚合的節點和哨兵位節點,哨兵位節點命名為
$aggregationStartState$
,最終效果如下圖所示:
在NFA比對的過程中,當比對結束,就可以将比對到的事件流,傳到聚合節點,再進一步聚合。
$aggregationStartState$
節點和
group_by
節點之間,是通過proceed結合,不需要滿足特定條件就可以執行。
具體的實作過程如下,可見與Flink不同的是,我們建立了一個特殊的
State
節點
AggregationState
:
# 建立聚合節點
def __create_aggregation_state(self, sink_state):
# 管道聚合節點的condition
_aggregation_condition = self.__current_pattern.get_aggregation_condition()
# 建立AggregationState
not_next = AggregationState(
self.__current_pattern.get_name(),
StateType.Normal,
_aggregation_condition.get_key_by_state_name(),
_aggregation_condition.get_field())
self.__states.append(not_next)
# 擷取take的條件
take_condition = self.__get_take_condition(self.__current_pattern)
not_next.add_take(sink_state, take_condition)
# 将遊标指向上一個節點
self.__following_pattern = self.__current_pattern
self.__current_pattern = self.__current_pattern.get_previous()
return not_next Show Me The Code
講了太多原理的東西,接下來看下代碼裡面如何工作的,先來看下如何來編寫一個CEP政策。
政策腳本
現在看下如何寫一個完整的python版本的cep規則,以寶貝詳情頁為例,規則描述如下:
需要比對使用者檢視3次寶貝詳情頁
那規則的寫法如下:
# 1. 建立用來比對的Pattern
_pattern = Pattern.begin('e1').where(KVCondition('scene', 'Page_xyItemDetail')).times(3)
# 2. 将需要比對的事件流_batch_data和待比對的Pattern
# CEP内部會先将pattern轉化成NFA,然後再用NFA去比對事件流
_cep = CEP.pattern(_batch_data['eventSeq'], _pattern)
# 用來選擇的邏輯
def select_function(data):
pass
# 3. 比對完成,通過cep的select接口查詢比對到的結果
self.result = _cep.select(select_function) 在
CEP.pattern()
函數裡面,會先建立
NFA
,然後去進行比對,可見整個比對政策腳本非常的短小精悍。
生成NFA
如下代碼用來将
Pattern
連結清單轉化成
NFA
圖:
# 最後一個Pattern節點不允許是NotFollowedBy
if self.__current_pattern.get_quantifier().get_consuming_strategy() == ConsumingStrategy.NOT_FOLLOW:
raise Exception('NotFollowedBy is not supported as a last part of a Pattern!')
# 校驗Pattern的名稱,必須唯一
self.__check_pattern_name_uniqueness()
# 校驗Pattern的政策
self.__check_pattern_skip_strategy()
# 首先建立Final節點
sink_state = self.__create_ending_state()
# 判定是否有聚合節點
if self.__current_pattern.get_aggregation_condition() is not None:
# 首先建立聚合節點
sink_state = self.__create_aggregation_state(sink_state)
# 然後建立聚合幾點的起始節點
sink_state = self.__create_aggregation_start_state(sink_state)
# 建立狀态機中的中間節點,此函數會循環知道Start節點的Pattern
sink_state = self.__create_middle_states(sink_state)
# 最後建立Start節點
self.__create_start_state(sink_state)
# 根據state清單和window來建立NFA
return NFA(self.__states, self.__window_time, False) 總結
閑魚已經上了幾個政策,整體看來比較穩定,不過還有很多優化的空間。從實測效果來看,端側從觸發政策到執行Action用時不會超過1s,其中還包含了一次網絡請求的時間。
性能資料
- 執行時間
單個腳本,執行時間大概在100ms左右。
- 記憶體使用
現在記憶體使用峰值還是比較高,大概在15M左右。關于記憶體過大的問題,目前正在讨論一個方案:Python CEP可以持久化目前NFA的狀态,然後再觸發政策的時候,隻帶從未觸發過的事件流,避免很多重複計算。之前運作一次腳本要處理500個事件,現在可能就縮減到100之内,可以極大的減小記憶體消耗。同時帶來另外一個問題,就是執行腳本的都會有一個IO操作,耗時會增加。
Flink與用戶端對比
現在對于Flink和用戶端Python CEP做一個簡單的對比:
相比Flink,端側CEP還是有它的優勢,在端側可以直接利用用戶端的埋點資訊進行計算,運作時長縮減了80%,而且也支援動态釋出。Python腳本支援2端通投,在保證2端埋點一緻的前提下,也極大的減少了維護成本。
未來
現在端計算還存在很多待優化的地方:
- 端計算是用Python實作,無法做到像Flink的狀态機常駐記憶體,每次都要重新建立比對,帶來了額外的消耗
- 在事件流的清洗上面,現在是通過回朔拿到之前的事件流,存在大量的重複計算,後續可以借鑒Flink的Window機制來進行優化。
- 目前編譯器暫時還不支援Group Pattern,後續還要對其進行擴充。
- Python腳本現在還是需要手動編寫,後續還可以考慮通過DSL來自動生成。
整體看來,Python腳本執行政策還是有一定的性能損耗,不管是在建立NFA或者是比對過程,後續可以考慮将比對引擎用C++實作,然後真正做到常駐記憶體,進而做到高效的執行效率。後期做到NFA持久化之後,C++也可以複用整套持久化協定,進而優化整個引擎的執行效率。除此之外,政策在執行的過程中,還可以考慮用TensorFlowLite優化參數政策參數,進而真正做到千人前面的政策。