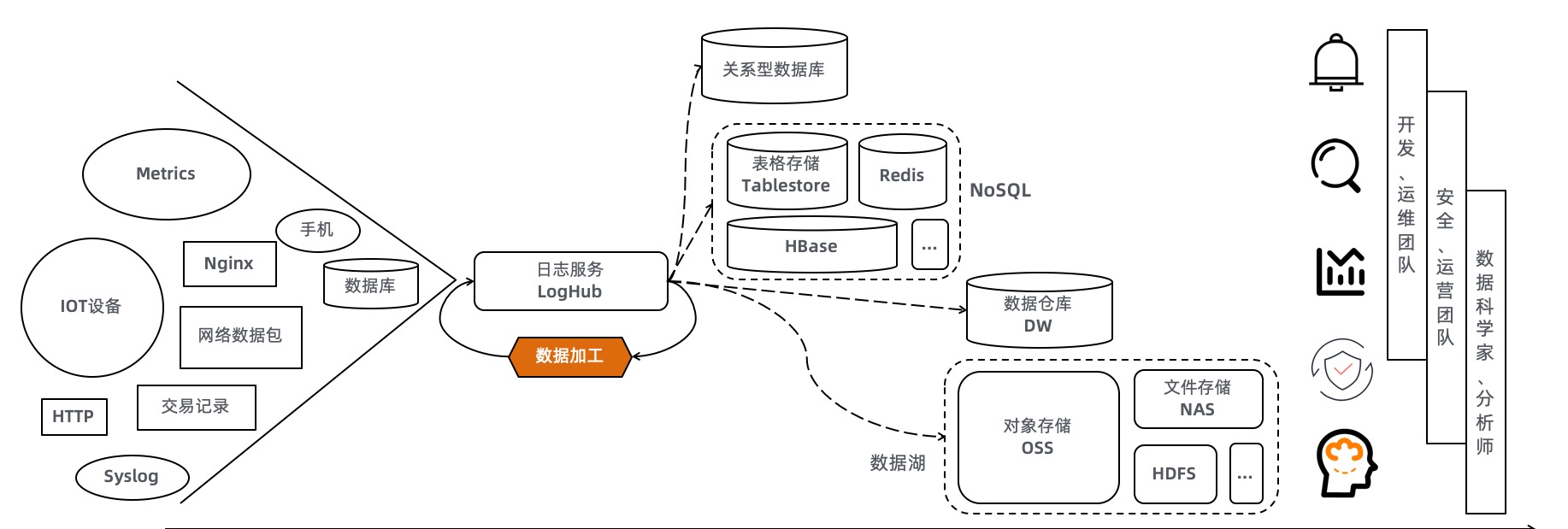
在日志服務,資料加工功能( 功能介紹 )用于完成對Logstore資料的預處理,為後續的分析階段準備資料。本文主要介紹資料加工實踐中可能遇到的延遲問題,幫助大家理清延遲現象背後的原因,以及如何去監控、解決延遲問題。
什麼是加工延遲
Logstore
資料加工作業是銜接源Logstore到目标Logstore的一個管道,在這個管道上完成富化、預處理、清洗等工作。
日志服務的Logstore首先是一個流式資料的存儲,在Logstore下有多個Shard(Shard可以類比為Kafka的Partition概念)。每個Shard即是一個資料分片,像是一個無限大隊列(基于落盤檔案),它是FIFO的:
- 當生産者向Logstore寫入資料的時候,資料預設會随機選擇一個Shard做存儲(追加到Shard的末尾,每個資料包在Shard上有一個位置,定義為Cursor)。
- 在讀Logstore的時候,消費者標明一個位置(Cursor)開始,按從頭到尾的方向順序讀出資料。
時間定義
在定義加工延遲之前,再來看幾個時間概念:
- 資料時間(EventTime):在資料上可以選擇一對Key/Value(例如是自定義的timestamp字段)存儲業務上的時間;一般建議在日志服務的保留字段
__time__

- 資料接收時間(ServerReceiveTime):生産者寫出的資料被服務端接收的系統時間,随着資料的順序寫入,ServerReceiveTime總是在遞增。
- 資料消費時間(ProcessingTime):消費者讀取這個資料做處理的系統時間。
把
ProcessingTime - ServerReceiveTime
定義為加工延遲。在流計算的理論情況下,兩者內插補點逼近0。在SLS實際的加工延遲可以做到1秒内,如果超出了一定門檻值,即是加工延遲。
怎樣發現延遲
确認目标寫入情況
當加工發生延遲的時候,直覺的情況是目标Logstore資料缺失。
- 如果目标Logstore建立了索引,可以選擇一個更大範圍的時間視窗,隔幾秒種查詢一次,看日志條資料是否有變化。如果日志集中在之前的時間段且資料量有逐漸增加,那比較大機率是發生了延遲(且加工在繼續工作)。
- 另一種情況,目标Logstore上沒有索引,可以通過預覽的方式,确認是否有新的資料在寫入。重複查詢幾次,例如最近15分鐘有資料寫入且寫入的資料EventTime比較老,也有可能是加工延遲的原因。
這兩個方法,除了用于确認加工延遲以外,也推薦用來觀察加工延遲的恢複進度、解決加工結果資料找不到的情況。
檢視名額
資料加工預設包含一個診斷儀表盤(
儀表盤介紹),登入
SLS控制台,選擇對應的加工作業進行檢視。
下圖就是一個延遲嚴重的情況:
而理想情況下加工延遲是:
配置告警
如果需要時刻關注加工延遲,可以配置一個告警,當延遲穩定發生時,SLS把告警推送釘釘群或者短信。
如何對加工配置告警,可以參考
加工告警配置指南操作。
在告警通知政策上,設定連續N次觸發再做消息推送,可以過濾偶爾抖動的情況。
加工全量資料導緻的延遲
這是一種預期内的延遲現象,主要發生在作業剛建立時,有兩種場景:
- 儲存加工作業時,選擇從曆史上一個時間點(按ServerReceiveTime是計算)開始處理資料
- 儲存加工作業時,選擇處理Logstore中的全量資料
加工耗時取決于時間段内的資料規模,加工作業需要從舊資料開始直到追趕進度完成。在加工并發足夠的情況下,會發現加工延遲有變小的趨勢。
如果觀察到加工追趕得比較慢,推薦對任務按照時間段做切分來實作加速。例如,要處理9/1到9/10的曆史日志,則按照天将任務切分成9個,分治處理:
Job_1: [9/1, 9/2)
Job_2: [9/2, 9/3)
....
Job_9: [9/9, 9/10]
加工邏輯複雜導緻的延遲
從Logstore的寫能力來看,SLS對一個Shard提供5MB/s(原始資料)以上的寫入能力,在日志服務叢集資源允許時可能支援10MB/s或者更高的寫入吞吐。
當真實的大量資料寫入源Logstore的Shard後,加工的業務複雜度是不确定的,是以可能發生瓶頸:加工的速率跟不上資料寫入的速率。
一個思路是降低加工的複雜度,從邏輯層面優化DSL代碼:
- 使用了e_regex,檢視正規表達式的複雜度。對正則做優化往往收到不錯的效果,盡量讓比對的邊界明确化,可以參考 如何優化正規表達式 。
- 提前對不需要的資料做過濾:例如對e_drop相關代碼做前置,在需要丢棄的資料上可以避免無意義的計算。
- 對于一連串複雜操作,通過使用條件判斷語句(例如e_if、e_switch等)設定分支條件。
- 使用了e_split等函數對JSON數組進行分裂寫出,1份輸入對應10倍或更多的寫出。
- 其它情況,持續更新中。。。
如果在加工邏輯層面難以做優化,更直接的方式是按照下一節處理(對源Logstore做Shard分裂),加工會根據Shard數目增加并發度。
源Shard數不足導緻的延遲
伴随着加工作業的線上上運作,業務流量變化也可能帶來源Logstore的流量增長。對源Logstore做Shard分裂(
Shard操作說明),可以讓每個Shard上的資料量少一些,并有機會得到更多的加工并發。
分裂Shard的限制
分裂Shard不會對曆史上已寫入的資料做重分布,也就是說老的資料還在舊Shard上,隻有新的資料會落到更多的Shard上。
是以,在分裂Shard後,觀察加工延遲名額,可能會發現部分Shard的加工延遲高,部分低的情況:
較為可能的原因是老的Shard曆史上積攢資料較多,追上進度需要時間,而新的Shard上的資料可以立刻被處理,從Logstore屬性檢視Shard建立時間可以确認這一點:
關注Shard的狀态
源Logstore上,隻有readwrite狀态的Shard數目對于加工并發有意義,在執行操作時可以選擇将Shard一次性分裂為N個。絕大部分情況下不用關注Shard上的BeginKey/EndKey,因為資料預設是随機Shard寫入的。
關于自動分裂
Logstore設定的自動分裂屬性,僅對資料寫入生效,請仔細閱讀該開關的說明。
從加工角度來說,加工延遲不會觸發自動分裂。
寫出目标受阻導緻的延遲
SLS對Logstore寫入有
速率限制,例如有每秒鐘要寫入10萬條日志(每條512 Bytes),則需要規劃5~10個Shard。
當目标Logstore readwrite狀态Shard數目不足時,加工有類似WriteQuotaExceed或QuotaExceed字樣的報錯,可以在診斷儀表盤中看到。
處理方法是:對目标Logstore做Shard分裂。解決寫出瓶頸後,加工作業停止阻塞,自動恢複資料處理。
總結
參考
加工性能指南,建議在部署加工作業之前,從三個層面進行規劃:
- 源Logstore,根據資料量調整Shard數目(readwrite狀态),滿足一定的加工并發度。
- 加工DSL代碼邏輯優化,例如對正則的優化、合理做條件剪枝、資料過濾盡量前置。
- 目标Logstore設定足夠的Shard數目(readwrite狀态),避免加工寫出資料受阻。