前言
NeurlPS 2019 大會剛結束,看了看相關的内容,絕大部分是各種前沿理論的文章。這些和我工作的内容還有比較長的距離:不論是知識領域空間上的距離,還是相關理論轉為工業界實踐的時間上的距離。但有兩篇還是吸引了我的注意。一篇是用于普及的教程:“Efficient Processing of Deep Neural Networks: from Algorithms to Hardware Architectures". 另一篇是PyTorch的簡短設計理念的介紹:“PyTorch: An Imperative Style, High-Performance Deep Learning Library“。今天,談一下對前一篇的細讀和體會。
教程是一系列的主題的集合,主題是從算法模型到硬體架構,以及兩者如何共同設計(co-design),高效地處理深度神經網絡。涉及的面還是比較廣的。演講人是Vivienne Sze,MIT副教授,來自MIT的高效能多媒體組。裡面的内容是團隊的合作研究的一個總結。
教程的主要内容大家可以仔細看視訊,也有對應的Slides。Slides裡面有很多的連結,可以找到對應的論文,代碼等,非常有用。他們團隊的首頁在這裡
https://www.rle.mit.edu/eems/publications/tutorials/。裡面有對應的材料。
總結
首先,上幹貨圖,我總結的學習思維導圖。
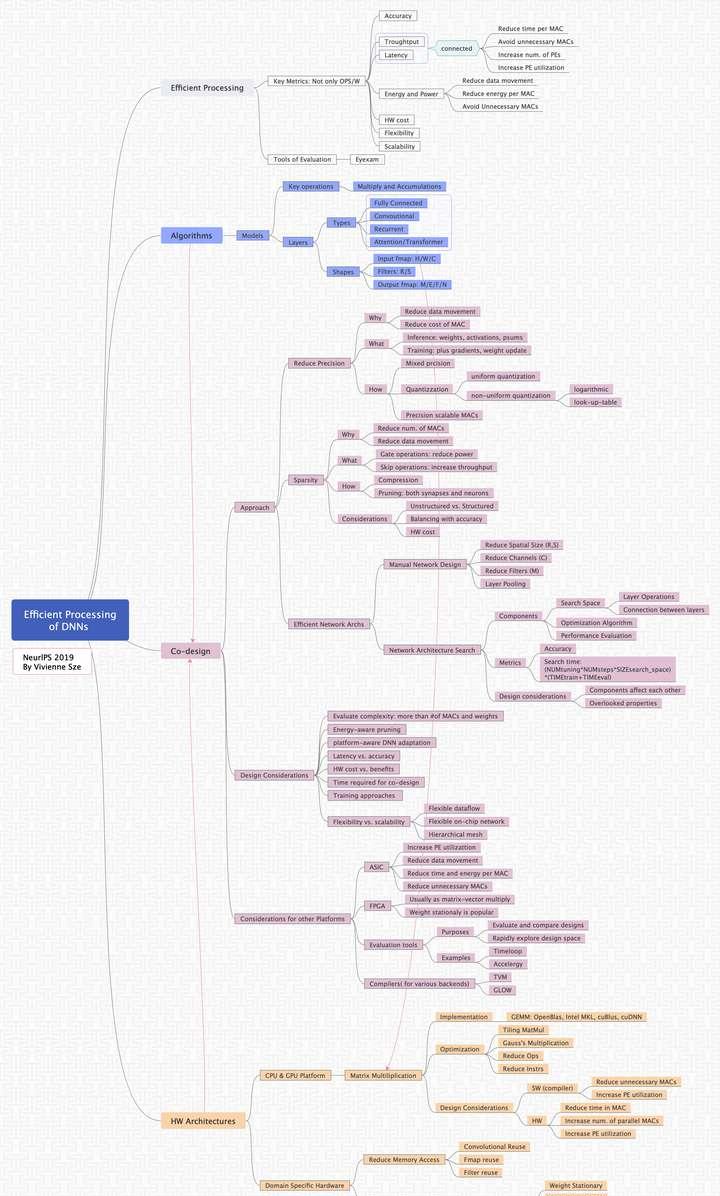
思維導圖-Efficient Processing of DNNs: From Algorithm to HW
總體來說,裡面談到的内容挺廣的了。因為是作為教程,裡面的内容偏初級,偏理論一些,非常适合用于學習和總結。我選擇一些自己認為比較感興趣,或者值得讨論的地方來和大家一起讨論一下,并做适當地展開。
1. DNN運算
教程裡的大部分篇幅強調的是MAC(Multiply and Accumulate)。為此,還特别地提到了矩陣乘在recurrent和attention層也使用得非常的多。可能一方面因為這是初級教程,另一方面也是因為有些材料是兩年前就有的,稍顯有些過時,屬于所謂AI1.0的重點,是以會過于強調MAC。
目前AI2.0階段,應用更豐富,作為對比,我們可以看看工業界的資料。來自Facebook的資料:

我們實際上也是同樣遇到這樣一個問題:随着深度神經網絡在各方面的應用越來越多,DNN裡面的操作也變得多樣化起來。工業界對這些問題更需要進一步的研究:包括各類應用場景中,DNN的各類操作的比例,包括目前的以及未來一段時間的。
然後,對這個問題的解決有多種方式,并且這些方案可能結合起來:
- 采用多種可并行的硬體計算單元:MatMul, vector op, reshape/transpose, etc. 做好比例的調研工作。
- 靈活可變的(flexible)微架構(HW pipe),也就是同一個硬體子產品可以用作不同的操作。可以由軟體,比如編譯器調整比例,驅動控制使用類型。
- 軟體棧做優化,包括算法,架構,編譯器等,将一種類型的操作轉化成另一種類型的操作,以适應硬體的能力。
2. 主要的效能評估标準
教程關于效能的評估标準談得比較的全面,覆寫了計算準确性,吞吐,延遲,能耗,硬體費用,以及應用的靈活性。詳細地介紹了一些對應的主要的設計目标,如何達到更高效的DNN處理器。
同時,教程也談到了一些評估的規範标準,特别強調了各個度量标準有自己獨立的意義,所有的評估度量都需要綜合考慮,遺漏其中的一些度量會導緻評估的不公平。
這通常需要一系列比較複雜的基準測試,比如相對比較成熟和全面的MLperf,它通過多種不同的方式來盡量地讓評估全面和公平。比如推理基準測試,
- 包含4種模式:single stream, multiple stream, server, offline
- 包含多種不同類型的模型,覆寫image classification,object detection,語言模型,翻譯,語音識别,情感分析。
- 定義了比較詳細的一些規則。( https://github.com/mlperf/policies/blob/master/submission_rules.adoc )
- 可以提供不同的scale: x1, x2, x4, x8,...,x32等多種成績
除了使用主流的Benchmark外,在工業界,針對激烈的市場競争,産品設計者需要考慮的是在多元評估度量之間如何定位自己的産品。通常會根據設計者對相應的産品定位,對上面提到的評估度量排出一定的優先級。比如,性能優先,還是通用性優先等。通常,還會使用一些組合的度量,比如PPA(Power-Performance-Area: power area per w)。會正對這些不同的度量具體化,給出一個可以度量的數字以明确設計目标。
3. 高效的資料流
這非常非常重要的一個話題。教程首先強調DNN計算,存儲通路是瓶頸,資料流動是非常昂貴的。教程提供了四層存儲架構(RF-寄存器,PE-本地存儲,Buffer-全局存儲,DRAM)的通路能量消耗比。從矩陣乘法MAC計算的角度,總結了各種類型的資料重用方法。這些資料重用的方法很基礎,在各種不同的架構中,可能都有一些使用,雖然具體的方法有些差别。
教程在最後“Other Platforms"章節裡提到了ASIC使用定制的存儲層次架構和資料流來減少資料的移動。但比較遺憾的針對這個話題,教程沒有繼續展開深入的讨論。
導讀:
近存計算(NMC: Near-memory Computing):
https://arxiv.org/pdf/1908.02640.pdfarxiv.org http://www.emc2-ai.org/assets/docs/neurips-19/emc2-neurips19-verma-talk.pdfwww.emc2-ai.org存内計算(IMC: In-memory Computing) NeurlPS正好也有一篇IMC的文章:
https://www.emc2-workshop.com/assets/docs/neurips-19/emc2-neurips19-verma-talk.pdfwww.emc2-workshop.com4. 算法硬體協同設計(Co-Design)
這是整個教程的後半部分。Sze教授從幾個主要的協同設計點來講述DSH(Domain Specific Hardware)的協同設計思想和實踐:
首先是如何選擇合适的精度,包括混合精度以及可變精度的一些實作。降低計算精度的目的是減少操作數的存儲和計算量,教程裡給出了各種精度乘/加/讀的能量消耗。也提到了量化的問題。
其次如何利用和降低稀疏性。不過壓縮的問題最近也不是熱點了。這要是硬體代價和收益的對比比較大。
然後用了較大的篇幅講高效DNN的網絡架構。包括手動設計和自動的網路架構搜尋。後面這個話題挺有意思的,雖然和我的工作沒有直接關系,但這種自動搜尋的理念是很友善應用在其他場景的。
協同設計時,很多方面需要考慮的是如何做平衡(Tradeoff):性能和延遲,延遲和準确性,硬體成本和精度,等等。做難的一個方面,是既要保證主流DNN計算高效能,又要保證整個設計的靈活性和擴充性,以能滿足日益增長的多種類型的計算需求。
感興趣的同學可以去學習一下相關的兩個架構裡的設計思想:
導引1: Graphcore IPU,已經在微軟 AZURE 上開測。
https://www.graphcore.ai/www.graphcore.aiIPU創新的使用BSP(Bulk Synchronous Parallel)架構,在資料流處理上完全不同于傳統的系統。感興趣的同學可以去仔細閱讀。我也還在學習當中。
導引2:AWS Inferentia推理晶片,存儲層次和互聯都是亮點,可惜我還沒有找到更進一步材料。
https://www.eetimes.com/aws-rolls-out-ai-inference-chip/www.eetimes.comAWS: Each chip has 4 “Neuron Cores” alongside “a large amount” of on-chip memory. There is an SDK for the chip which can split large models across multiple chips using a high-speed interconnect.
讨論
整體來說這一教程作為初級入門學習非常好。建議感興趣的同學可以慢慢品讀一下。如果我來介紹的話,我還會多研究學習工業界Facebook,Graphcore,Habana,AWS等,加上其他的一些其他的話題,比如
軟硬體的協同設計
首先是軟體和硬體的協同設計。在上層應用和研究者眼裡,通常會認為算法和硬體就是DNN計算的兩大塊。其實從真正的從業人員的角度來看,我們跟偏向于算法-軟體-硬體的協同設計。比如上面引用的Facebook的在AI Hardware Submit 2019的一篇演講: 《AI System Co-Design: How to Balance Performance & Flexibility》。演講人是Facebook的AI Systems Co-Design Director。演講裡比較明确地談論了一些軟體和硬體協同的思想和方法。
DSH的架構,必然加大上層應用和底層硬體之間的邏輯距離。從架構,到DSL,通過編譯器到特有的ISA。中間的轉化和對接工作,是特定領域的軟硬體協同核心價值所在。隻有這個從算法到軟體棧到硬體的通路設計得合理和高效,才能充分展現DSA的意義。
• Dave Kuck, software architect for Illiac IV (circa 1975)
“What I was really frustrated about was the fact, with Iliac IV, programming the machine was very difficult and the architecture probably was not very well suited to some of the applications we were trying to run. The key idea was that I did not think we had a very good match in Iliac IV between applications and architecture.”
• Achieving cost-performance in this era of DSAs will require matching the applications, languages, architecture, and reducing design cost.
很多的公司都在進行軟硬體協同設計的實踐,特别是AI方面的ASIC,FPGA。這些實踐離理想的軟硬體協同設計概念還比較遠,但不可否認,這些實踐在晶片和軟體棧上的落地,推動了這一理念的發展。通過對相關行業和公司的研究,可以比較明顯地看到,在硬體/晶片設計前期,如果脫離軟體(架構,編譯,驅動)的協同,即使硬體/晶片成功出來了,也會有很大的業務落地問題,包括但不限于:
- 算法對接硬體難,編譯,驅動實作工作量大,
- 應用程式設計難,程式設計模型和程式設計接口不好用
- 硬體性能很難發揮,算力的使用率低下
這大概就是大家在實踐中體會到的“硬體好做,軟體困難”的問題。而實踐好的設計,在前期如果協同考慮和系統性地解決了一些主要問題,就能比較好的加速後期業務落地。
導引:
唐杉:AI晶片“軟硬體協同設計”的理想與實踐 https://semiengineering.com/hardware-software-co-design-reappears/在原來的思維導圖的基礎上,我搜集并添加了相關的一些資料,産生一個新的知識圖譜: