本文介紹了如何在GPU執行個體上基于NGC環境使用RAPIDS加速庫,加速資料科學和機器學習任務,提高計算資源的使用效率。
背景資訊 {#section_koh_7rx_iga .section}
RAPIDS,全稱Real-time Acceleration Platform for Integrated Data Science,是NVIDIA針對資料科學和機器學習推出的GPU加速庫。更多RAPIDS資訊請參見
官方網站。
NGC,全稱NVIDIA GPU CLOUD,是NVIDIA推出的一套深度學習生态系統,供開發者免費通路深度學習和機器學習軟體堆棧,快速搭建相應的開發環境。
NGC網站提供了RAPIDS的Docker鏡像,預裝了相關的開發環境。
JupyterLab是一套互動式的開發環境,幫助您高效地浏覽、編輯和執行伺服器上的代碼檔案。
Dask是一款輕量級大資料架構,可以提升并行計算效率。
本文提供了一套基于NVIDIA的RAPIDS Demo代碼及資料集修改的示例代碼,示範了在GPU執行個體上使用RAPIDS加速一個從ETL到ML Training端到端任務的過程。其中,ETL時使用RAPIDS的cuDF,ML Training時使用XGBoost。本文示例代碼基于輕量級大資料架構Dask運作,為一套單機運作的代碼。
說明: NVIDIA官方RAPIDS Demo代碼請參見
Mortgage DemoRAPIDS預裝鏡像已經釋出到阿裡雲鏡像市場,建立GPU執行個體時,您可以在鏡像市場中搜尋NVIDIA RAPIDS并使用RAPIDS預裝鏡像。
說明: 該RAPIDS預裝鏡像使用Ubuntu 16.04 64-bit作業系統。
gn5優惠活動詳情請參見
異構計算GPU執行個體活動頁前提條件 {#section_qz1_22r_qt8 .section}
操作步驟 {#section_4st_emv_868 .section}
如果您建立GPU執行個體時使用了RAPIDS預裝鏡像,隻需運作RAPIDS Demo,從
啟動JupyterLab服務開始操作即可。
如果您建立GPU執行個體時沒有使用RAPIDS預裝鏡像,按照以下步驟使用RAPIDS加速機器學習任務:
步驟一:擷取RAPIDS鏡像下載下傳指令 {#section_6nn_fh6_3ro .section}
- 打開MACHINE LEARNING頁面,單擊RAPIDS鏡像。
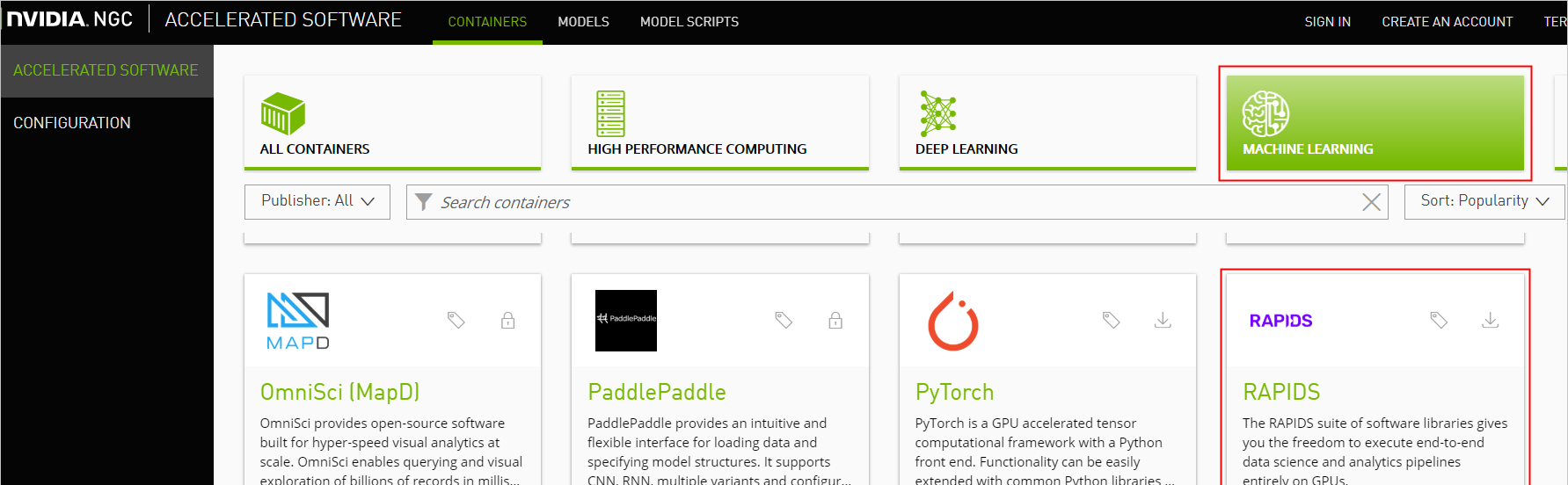
GPU加速資料科學之-如何在GPU執行個體上使用RAPIDS加速機器學習任務 -
擷取docker pull指令。
本文示例代碼基于RAPIDS 0.8版本鏡像編寫,是以在運作本示例代碼時,使用Tag為0.8版本的鏡像。實際操作時,請選擇您比對的版本。
- 選擇Tags頁簽。
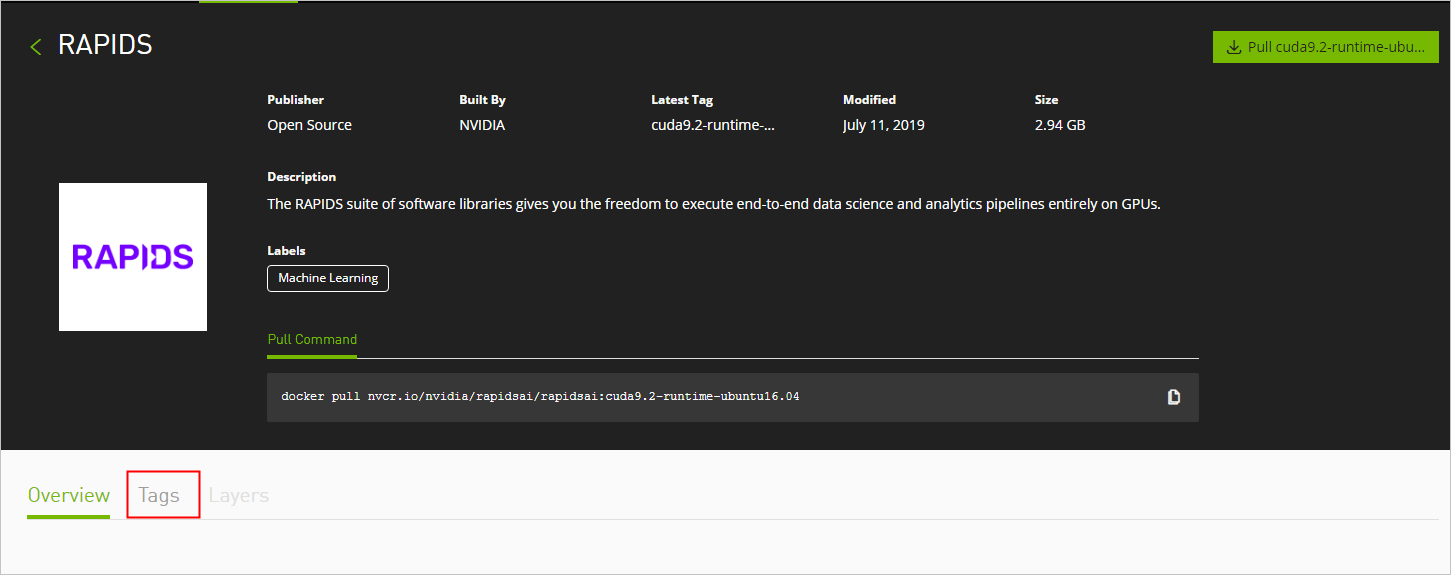 - 找到并複制Tag資訊。本示例中,選擇
0.8-cuda10.0-runtime-ubuntu16.04-gcc5-py3.6
 - 傳回頁面頂部,複制Pull Command中的指令到文本編輯器,将鏡像版本替換為對應的Tag資訊,并儲存。 本示例中,将
cuda9.2-runtime-ubuntu16.04
0.8-cuda10.0-runtime-ubuntu16.04-gcc5-py3.6
儲存的docker pull指令用于在[步驟二](#section_4tf_rho_1gy)中下載下傳RAPIDS鏡像。 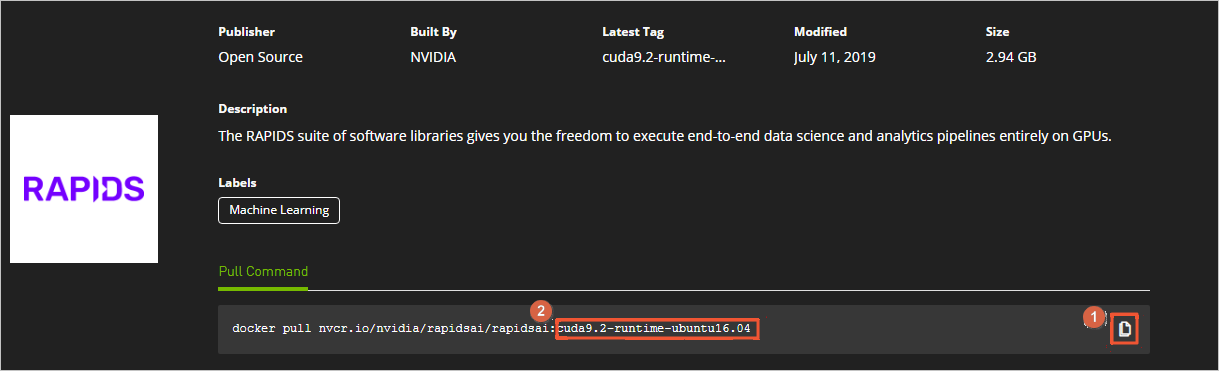
- 選擇Tags頁簽。
步驟二:部署RAPIDS環境 {#section_4tf_rho_1gy .section}
-
建立一台GPU執行個體。
詳細步驟請參見
使用向導建立執行個體- 執行個體:RAPIDS僅适用于特定的GPU型号(采用NVIDIA Pascal及以上架構),是以您需要選擇GPU型号符合要求的執行個體規格,目前有gn6i、gn6v、gn5和gn5i,詳細的GPU型号請參見 執行個體規格族 。建議您選擇顯存更大的gn6i、gn6v或gn5執行個體。本示例中,選用了顯存為16 GB的GPU執行個體。
- 鏡像:在鏡像市場中搜尋并使用
NVIDIA GPU Cloud VM Image

GPU加速資料科學之-如何在GPU執行個體上使用RAPIDS加速機器學習任務 - 公網帶寬:選擇配置設定公網IPv4位址或者在執行個體建立成功後 綁定EIP位址
- 安全組:選擇的安全組需要開放以下端口:
- TCP 22 端口,用于SSH登入
- TCP 8888端口,用于支援通路JupyterLab服務
- TCP 8787端口、TCP 8786端口,用于支援通路Dask服務
-
連接配接GPU執行個體。
連接配接方式請參見
連接配接Linux執行個體 - 輸入NGC API Key後按Enter鍵,登入NGC容器環境。
GPU加速資料科學之-如何在GPU執行個體上使用RAPIDS加速機器學習任務 -
(可選)運作nvidia-smi檢視GPU型号、GPU驅動版本等GPU資訊。
建議您了解GPU資訊,預判規避潛在問題。例如,如果NGC的驅動版本太低,新Docker鏡像版本可能會不支援。
- 運作在 步驟一 中擷取的docker pull指令下載下傳RAPIDS鏡像。
docker pull nvcr.io/nvidia/rapidsai/rapidsai:0.8-cuda10.0-runtime-ubuntu16.04-gcc5-py3.6 -
(可選)檢視下載下傳的鏡像。
建議您檢視Docker鏡像資訊,確定下載下傳了正确的鏡像。
docker images - 運作容器部署RAPIDS環境。
docker run --runtime=nvidia \ --rm -it \ -p 8888:8888 \ -p 8787:8787 \ -p 8786:8786 \ nvcr.io/nvidia/rapidsai/rapidsai:0.8-cuda10.0-runtime-ubuntu16.04-gcc5-py3.6
步驟三:運作RAPIDS Demo {#section_jlv_sqz_hzk .section}
- 在GPU執行個體上下載下傳資料集和Demo檔案。
# Get apt source address and download demos. source_address=$(curl http://100.100.100.200/latest/meta-data/source-address|head -n 1) source_address="${source_address}/opsx/ecs/linux/binary/machine_learning/" cd /rapids wget $source_address/rapids_notebooks_v0.8.tar.gz tar -xzvf rapids_notebooks_v0.8.tar.gz cd /rapids/rapids_notebooks_v0.8/xgboost wget $source_address/data/mortgage/mortgage_2000_1gb.tgz -
在GPU執行個體上啟動JupyterLab服務。
推薦直接使用指令啟動。
# Run the following command to start JupyterLab and set the password. cd /rapids/rapids_notebooks_v0.8/xgboost jupyter-lab --allow-root --ip=0.0.0.0 --no-browser --NotebookApp.token='YOUR PASSWORD' # Exit JupyterLab. sh ../utils/stop-jupyter.sh
- 除使用指令外,您也可以執行腳本`sh ../utils/start-jupyter.sh`啟動jupyter-lab,此時無法設定登入密碼。
- 您也可以連續按兩次`Ctrl+C`退出JupyterLab服務。 - 打開浏覽器,在位址欄輸入
http://您的GPU執行個體IP位址:8888
遠端通路JupyterLab 。
說明: 推薦使用Chrome浏覽器。
如果您在啟動JupyterLab服務時設定了登入密碼,會跳轉到密碼輸入界面。
GPU加速資料科學之-如何在GPU執行個體上使用RAPIDS加速機器學習任務 -
運作NoteBook代碼。
該案例是一個抵押貸款回歸的任務,詳細資訊請參見
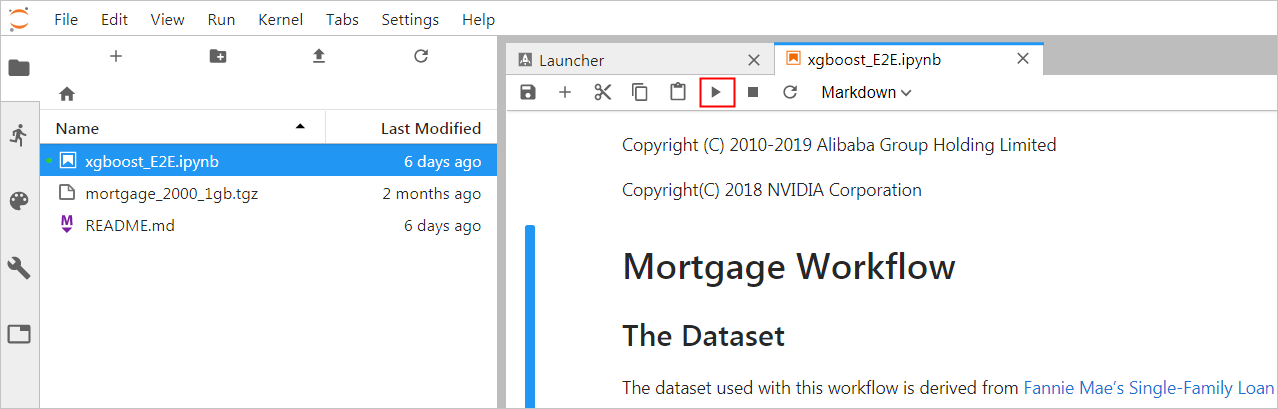
代碼執行過程 。登入成功後,可以看到NoteBook代碼的代碼包括以下内容:- xgboost_E2E.ipynb檔案: XGBoost Demo檔案。輕按兩下檔案可以檢視檔案詳情,單擊下圖中的執行按鈕可以逐漸執行代碼,每次執行一個Cell。
 - mortgage_2000_1gb.tgz檔案: 2000年的抵押貸款回歸訓練資料(1G分割的perf檔案夾下的檔案不會大于1G,使用1G分割的資料可以更有效的利用GPU顯存)。
- xgboost_E2E.ipynb檔案: XGBoost Demo檔案。輕按兩下檔案可以檢視檔案詳情,單擊下圖中的執行按鈕可以逐漸執行代碼,每次執行一個Cell。
代碼執行過程 {#section_88w_0mw_i43 .section}
該案例基于XGBoost示範了資料預處理到訓練的端到端的過程,主要分為三個階段:
- ETL(Extract-Transform-Load):主要在GPU執行個體上進行。将業務系統的資料經過抽取、清洗轉換之後加載到資料倉庫。
- Data Conversion:在GPU執行個體上進行。将在ETL階段處理過的資料轉換為用于XGBoost訓練的DMatrix格式。
- ML-Training:預設在GPU執行個體上進行。使用XGBoost訓練梯度提升決策樹 。
NoteBook代碼的執行過程如下:
- 準備資料集。
本案例的Shell腳本會預設下載下傳2000年的抵押貸款回歸訓練資料(mortgage\_2000\_1gb.tgz)。 如果您想擷取更多資料用于XGBoost模型訓練,可以設定參數download\_url指定下載下傳路徑,具體下載下傳位址請參見[Mortgage Data](https://docs.rapids.ai/datasets/mortgage-data)。 示例效果如下 : 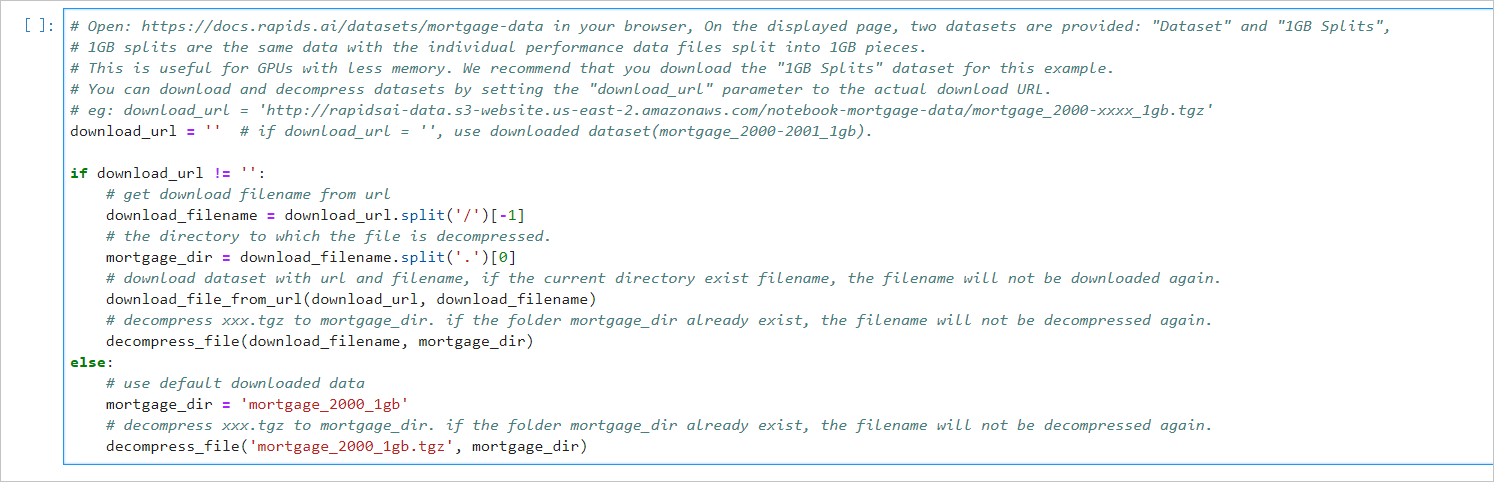 - 設定相關參數。
|參數名稱|說明| |----|--| |start\_year|指定選擇訓練資料的起始時間,ETL時會處理start\_year到end\_year之間的資料。| |end\_year|指定選擇訓練資料的結束時間,ETL時會處理start\_year到end\_year之間的資料。| |train\_with\_gpu|是否使用GPU進行XGBoost模型訓練,預設為True。| |gpu\_count|指定啟動worker的數量,預設為1。您可以按需要設定參數值,但不能超出GPU執行個體的GPU數量。| |part\_count|指定用于模型訓練的performance檔案的數量,預設為 2 \* gpu\_count。如果參數值過大,在Data Conversion階段會報錯超出GPU記憶體限制,錯誤資訊會在NoteBook背景輸出。| 示例效果如下: 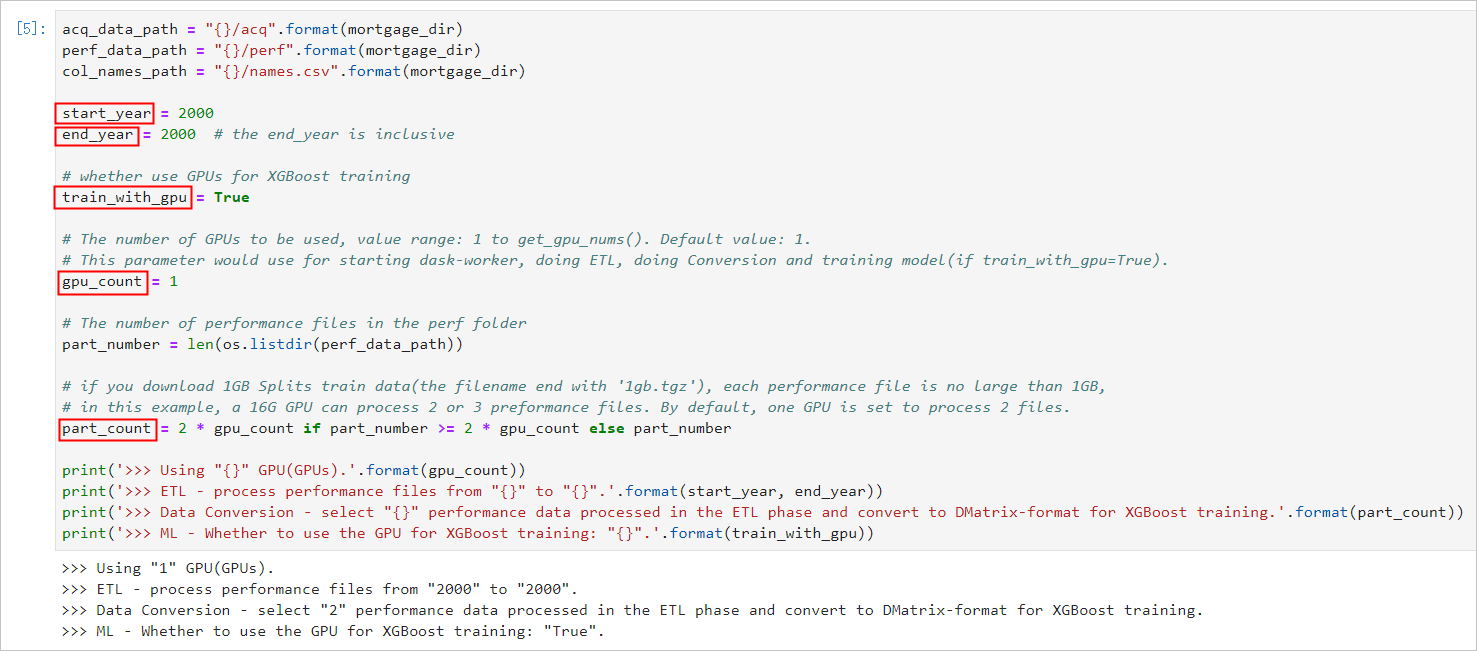 - 啟動Dask服務。
代碼會啟動Dask Scheduler,并根據gpu\_count參數啟動worker用于ETL和模型訓練。啟動Dask服務後,您也可以通過Dask Dashboard直覺地監控任務,打開方法請參見[Dask Dashboard](#section_x15_g1t_2f7)。 示例效果如下:  - 啟動ETL。
ETL階段會進行到表關聯、分組、聚合、切片等操作,資料格式采用cuDF庫的DataFrame格式(類似于pandas的DataFrame格式)。 示例效果如下: 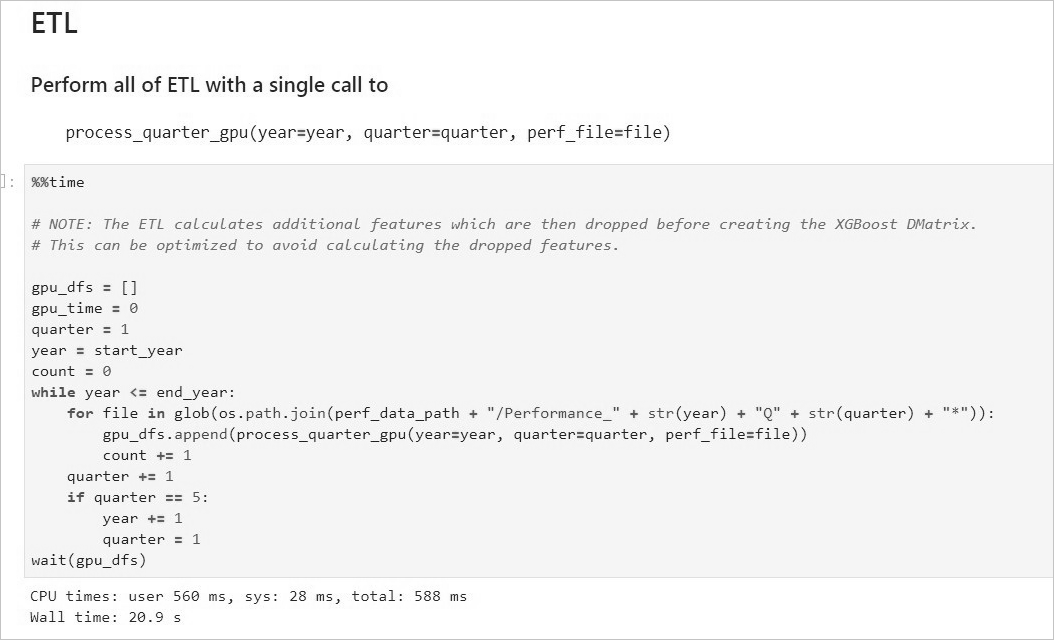 - 啟動Data Conversion。
将DataFrame格式的資料轉換為用于XGBoost訓練的DMatrix格式,每個worker處理一個DMatrix對象。 示例效果如下: 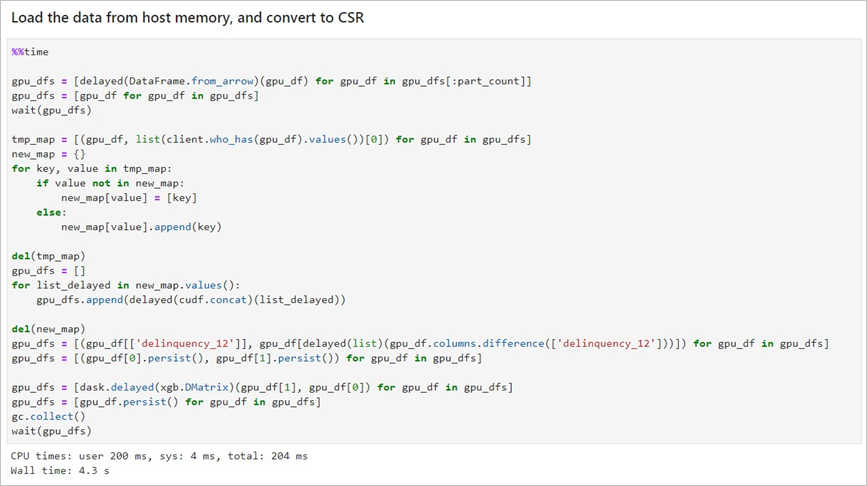 - 啟動ML Training。
使用dask-xgboost啟動模型訓練,dask-xgboost負責多個dask worker間的通信協同工作,底層仍然調用xgboost執行模型訓練。 示例效果如下: 
Dask Dashboard {#section_x15_g1t_2f7 .section}
Dask Dashboard支援任務進度跟蹤、任務性能問題識别和故障調試。
Dask服務啟動後,在浏覽器位址欄中通路
http://您的GPU執行個體IP位址:8787/status
即可進入Dashboard主界面。
相關函數 {#section_whh_v8f_nnc .section}
| 函數功能 | 函數名稱 |
|---|---|
| 下載下傳檔案 | def download_file_from_url(url, filename): |
| 解壓檔案 | def decompress_file(filename, path): |
| 擷取目前機器的GPU個數 | def get_gpu_nums(): |
| 管理GPU記憶體 | - def initialize_rmm_pool(): |
- def initialize_rmm_no_pool():
- def run_dask_task(func, **kwargs):
|
|送出DASK任務| - def process_quarter_gpu(year=2000, quarter=1, perf_file=""):
- def run_gpu_workflow(quarter=1, year=2000, perf_file="", **kwargs):
|使用cuDF從CSV中加載資料| - def gpu_load_performance_csv(performance_path, **kwargs):
- def gpu_load_acquisition_csv(acquisition_path, **kwargs):
- def gpu_load_names(**kwargs):
|處理和提取訓練資料的特征| - def null_workaround(df, **kwargs):
- def create_ever_features(gdf, **kwargs):
- def join_ever_delinq_features(everdf_tmp, delinq_merge, **kwargs):
- def create_joined_df(gdf, everdf, **kwargs):
- def create_12_mon_features(joined_df, **kwargs):
- def combine_joined_12_mon(joined_df, testdf, **kwargs):
- def final_performance_delinquency(gdf, joined_df, **kwargs):
- def join_perf_acq_gdfs(perf, acq, **kwargs):
- def last_mile_cleaning(df, **kwargs):
更多資訊 {#section_2v1_q0o_h4k .section}
GPU執行個體和RAPIDS組合适用于加速更多類型的任務,請參見
在GPU執行個體上使用RAPIDS加速圖像搜尋任務