引言
從計算到感覺再到認知是業内學者都認同的人工智能技術發展路徑。機器具備認知智能,進而實作推理、規劃乃至聯想和創作,在一定程度上需要一個充滿知識的大腦,而資訊抽取是擷取知識的重要途徑之一。 在具體的業務場景如搜尋推薦,結構化的領域知識有利于實作細粒度文本了解,有利于實作精準的複雜問答,有利于召回更相關的文檔。在醫療、法律、金融等垂直領域,建構高品質的垂直知識圖譜,是實作知識賦能搜尋、問答、推薦等業務場景的基石,而資訊抽取則是建構圖譜最為重要的環節之一。然而什麼是資訊抽取?它有哪些挑戰?發展狀況如何?未來趨勢又是怎麼樣?本文旨在回答以上幾個問題。
什麼是資訊抽取?
資訊抽取(information extraction),即從自然語言文本中,抽取出特定的事件或事實資訊,幫助我們将海量内容自動分類、提取和重構。 這些資訊通常包括實體(entity)、關系(relation)、事件(event)如下所示。
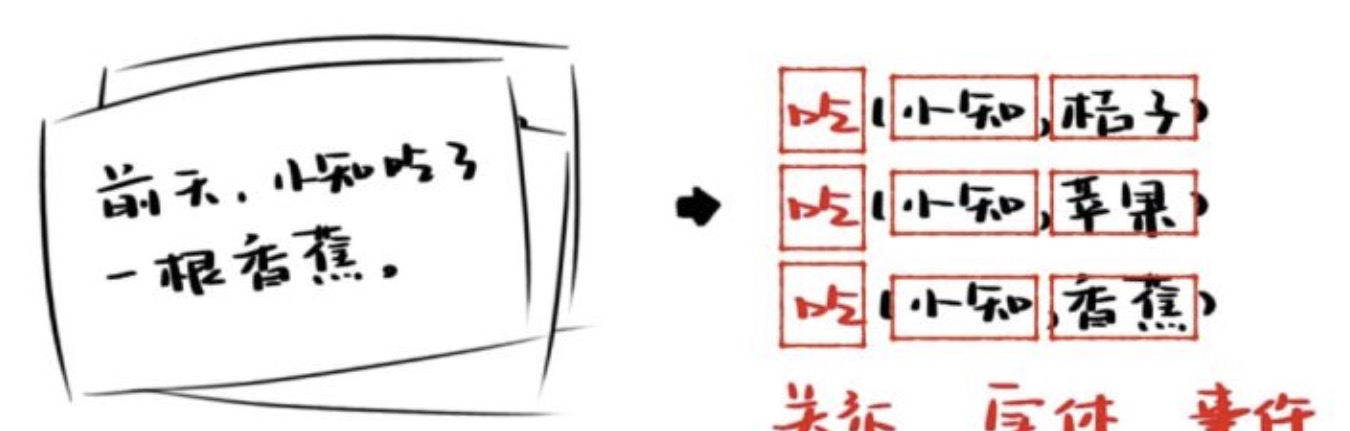
通常而言,資訊抽取技術主要包含命名實體識别、關系/屬性抽取、事件抽取等任務。命名實體識别(NER)一般是一個序列标注任務,如對于文本"娃娃(PEO)進娃娃機抓娃娃",在上下文語境下,實體識别任務需要對第一個娃娃标注為PEO。關系/屬性抽取一般為分類任務,如給定實體對和文本,判斷在上下文語境下實體之間是什麼關系。比如,給定實體“特朗普”、實體“紐約”和文本“特朗普出生于紐約”,關系抽取需要抽取“出生于”這個關系。事件抽取最為複雜,一般分為事件識别(Trigger Identification/ Classification)、元素分類(Argument Identication)、元素角色分類(Argument Role Classification)等幾個子任務。例如,對于文本“賈乃亮離婚後現身綜藝!談及家人滿臉心酸,前妻李小璐” 事件抽取需要首先識别觸發詞"離婚"并分類為"離婚事件",再識别元素"賈乃亮"和"李小璐"并分類為"丈夫"和"妻子"。
資訊抽取的挑戰
命名實體識别任務是資訊抽取中發展最為成熟的任務,從古老的HMM、CRF到BiLSTM-CRF,再到Lattice LSTM ,TENNER[1],實體識别任務在标準資料集上取得了很大的進步,在BERT等預訓練模型出現後,實體識别更獲得了進一步的提升。 而關系抽取任務,由于标準資料擷取的困難,效果相對較差。關系抽取任務一般采用有監督或遠監督分類模型,在深度學習出現之前主要通過人工特征和基于核函數的模型;在深度學習時代,主流模型有CNN、PCNN等。事件抽取最為困難,方法發展和關系抽取類似,代表研究有中科院陳玉博研究員提出的DMCNN[2]等。除此之外,資訊抽取還包含通用領域資訊抽取,代表工作有TextRunner,Open IE等。
資訊抽取主要面臨以下幾個挑戰:
- 樣本擷取困難。如何在有限的标注樣本下訓練高品質的資訊抽取模型是一個嚴峻的挑戰。比如,垂直領域如醫療标注命名實體需要專業的知識,标注成本極高;擷取關系抽取、事件抽取樣本也代價高昂。
- 文本語義複雜。如何在複雜歧義的上下文和長文本語境抽取實體、關系、事件是一個嚴峻的挑戰。比如“姨媽(人物)來了大姨媽(生理)怎麼辦”,“紐約是美國首都”同時包含了“首都” 和“位于” 兩個關系,"李小璐和賈乃亮會複婚嗎" 根本沒有包含觸發詞。
- 泛化能力差。如何訓練一個能在資料、标簽分布不同的真實場景仍具有較好泛化能力的模型是一個嚴峻的挑戰。比如,如果訓練樣本僅有短文本Title、Query,模型在預測長文本文檔時性能會大打折扣,又比如對于新出現的關系、事件、實體類型,資訊抽取模型性能也會嚴重下降。
- 實用性差。如何訓練一個通用模型進行端到端的資訊抽取是一個嚴峻的挑戰。目前現有的資訊抽取模型分為pipeline、end2end、join inferecne 、 joint modeling等,一般需要多個模型進行級聯,極其複雜,不同方法各有優劣,訓練一個通用的資訊抽取模型同時抽取實體、關系、事件是非常困難的。
低資源資訊抽取
低資源資訊抽取旨在基于少量标注樣本和大量無标注樣本,獲得高性能的資訊抽取模型,技術路線主要包含基于元學習的方法、基于遷移學習的方法、引入外部資料的方法、基于預訓練的方法和基于樣本增廣的方法等。本質上,低資源資訊抽取方法主要目标是獲得更加魯棒的表征和更多的樣本來實作低資源場景下模型性能的提升。下面介紹幾篇代表性工作。
DMB-PN(WSDM2020)[3]
考慮到現實世界中的新事件層出不窮,本人及合作者将事件檢測模組化成少樣本學習任務,并提出了一個基于動态記憶的原型網絡模型。

LW-BiLSTM-PCRF(EMNLP2019) [4]
UIUC Ji heng 組提出了基于弱監督标簽的實體識别模型,模型主要通過同時使用高品質和低品質的弱監督資料并共享參數訓練Partial-BiLSTM-CRF模型,本質上這是一個遷移學習過程。
GCNRE(NAACL2019)[5]
針對關系抽取中大量長尾關系抽取難的特點,本人基于關系之間的顯式關聯和知識圖譜隐式知識,提出基于圖神經網絡的關系抽取模型,在長尾關系抽取中取得較好效果。
Match Blank(ACL2019)[6]
谷歌團隊提出的一種關系抽取算法,本文貢獻主要在于新穎的預訓練模式和多種encoder的經驗結果。此方法效果極好,且在FewRel資料集超過人類,然而中文領域仍缺乏此類預訓練模型。
MTDS(NAACL2019)[7]
阿裡達摩院司羅老師團隊提出了基于一緻性的資料選擇和知識驅動和生成的實體識别算法,此算法本質上也是一種新穎的遷移學習算法,具有一定的實用價值。
Reading the Manual(AAAI2020)[8]
約翰霍普金斯大學的學者提出了一個新穎的事件抽取模型,核心想法是引入标注的規則文本,此方法類似資料增廣,在低資源場景效果較好。
複雜語境下資訊抽取
複雜語境下資訊抽取的難點首先是overlapping, 如存在實體之間互相包含、關系互相重疊。其次是遠端監督帶來的噪音以及長文檔跨句帶來的表征學習困難。
Capsule(EMNLP2018)[9]
關系抽取中存在大量的多關系情況,樣本分布不均衡的資料集上很難進行實體對中的多關系抽取,本人提出了基于膠囊網絡的多關系抽取模型,此模型基于無監督路由算法學習關系的魯棒向量,以減輕不均衡樣本對表征的影響,在多關系抽取取得較好的效果。
ARNOR(ACL2019)[10]
針對關系抽取遠監督導緻的噪音問題,百度學者提出了基于模闆比對和注意力正則的降噪方法。
ConstrainRE(AAAI2020)[11]
關系抽取中,某些關系之間存在很強的語義先驗限制,比如如果存在關系"首都"則大機率會存在關系"位于",北大的學者提出了ConstrainRE,通過顯式引入關系之間的限制Loss來增強關系抽取性能。
Out of Distribution資訊抽取
對于未知實體、關系等的資訊抽取,可采取前面提到的低資源資訊抽取模型,也可以采用開放域資訊抽取的方法。
RSN(EMNLP2019)[12]
清華劉知遠老師團隊提出了基于關系孿生網絡的開放領域關系抽取模型,此方法主要動機為遷移已有的遠監督關系知識到未知的開放領域關系,并通過Metric Learning 和聚類實作未知關系的抽取。
聯合資訊抽取
聯合資訊抽取主要分為實體、關系聯合抽取,實體事件聯合抽取等。
Novel Tagging(ACL2017) [13]
針對關系抽取和實體識别聯合抽取任務,中科院自動化所的學者提出了一種新穎的标注方法,開創了實體關系聯合抽取的先河,并啟發了一系列聯合抽取工作,然而此方法無法抽取overlapping的元組。
CopyRE (ACL2018) [14]
中科院學者創新得将實體關系抽取任務定義為seq2seq任務,并實作多關系多實體聯合抽取,且能夠處理overlapping問題。
CopyMTL(AAAI2020)[15]
針對CopyRE存在無法區分頭尾實體和無法預測多個token的實體的問題,UIUC學者提出了CopyMTL模型,此模型主要通過多任務學習方式,将實體抽取部分單獨作為序列标注任務,方法簡單易懂,效果不錯。
FSA&PDA(EMNLP2019)[16]
針對标簽之間存在一定強關系限制的特點,谷歌和賓夕法尼亞大學學者提出了基于自動機限制的序列預測模型,此模型雖然僅應用在序列标注任務,且存在一定的局限性,但是模型的思考角度非常新穎,且自動機的自動學習和限制機制帶來的很大的啟發,這種機制是否可以應用在關系、事件抽取值得探索。
LogicRE(AAAI2020)[17]
針對實體識别和關系抽取之間存在一定的邏輯限制現象,南洋理工大學王文雅老師團隊提出了基于描述邏輯的實體識别和關系抽取模型,此方法也是少有的融合符号主義和聯結主義的工作,值得一讀。
資訊抽取新的征程
随着NLP的不斷發展,也湧現了一些新的資訊抽取路線,這裡總結如下:
基于預訓練模型的直接資訊抽取
這裡的方法主要是通過預訓練模型以構造完形填空或序列标注的方式直接抽取元組,代表工作有COMET[18] , 這些方法一般直接基于Transformer,有些類似于通用資訊抽取, 詳見 [從感覺到認知:淺談知識賦能自然語言處理]()
基于閱讀了解的資訊抽取
香濃科技學者在ACL2019論文[19]将實體、關系抽取改造成為機器閱讀了解任務,角度新穎,然而對于長文檔此方法存在資訊遺忘和性能問題。
基于序列生成的文本資訊抽取
此類方法将抽取任務定義為seq2seq任務,主要代表方法有CopyRE和CopyMTL等。
開源工具
實體識别
bert-ner
https://github.com/macanv/BERT-BiLSTM-CRF-NER關系抽取
DeepNRE 清華劉志遠老師團隊
https://github.com/thunlp/OpenNREDeepKE 浙大陳華鈞老師團隊
https://github.com/zjunlp/deepke通用工具
StanfordNLP
https://stanfordnlp.github.io/stanfordnlp/DeepDive
http://deepdive.stanford.edu/Snorkel
https://github.com/snorkel-team/snorkelOpenIE
https://nlp.stanford.edu/software/openie.htmlTextrunner
http://openie.cs.washington.edu/Fastnlp
https://github.com/fastnlp/fastNLP中文開放領關系抽取
https://github.com/lemonhu/open-entity-relation-extraction哈工大LTP
https://www.ltp-cloud.com/Snownlp
https://github.com/isnowfy/snownlpHanLP
https://github.com/hankcs/HanLP資料集
CoNLL2003
https://github.com/synalp/NER/tree/master/corpus/CoNLL-2003OntoNotes
https://github.com/yhcc/OntoNotes-5.0-NERMSRA
https://github.com/buppt/ChineseNER/tree/master/data/MSRAWeibo NER
https://github.com/OYE93/Chinese-NLP-Corpus/tree/master/NER/WeiboResume NER
https://github.com/jiesutd/LatticeLSTM/tree/master/ResumeNERFewer、 semeval 、Wiki80、NYT10
https://github.com/thunlp/OpenNRE/tree/master/benchmarkTECRED
https://nlp.stanford.edu/projects/tacred/ACE05 (實體、關系、事件抽取)
https://catalog.ldc.upenn.edu/LDC2006T06下一代資訊抽取系統暢想
- 更少的樣本,更強的泛化能力。未來的資訊抽取模型也許隻需要少量的樣本就可以獲得更好的性能和更強的泛化能力。
- 多模态資訊抽取。未來的資訊抽取模型也許可以從圖像、視訊、音頻等資料中抽取知識。
- 自動化端到端。未來的資訊抽取模型可以自動進行網絡架構設計、自動超參數優化,實作AutoML based Information Extraction 。
- 通用資訊抽取。未來資訊抽取也許範圍更廣,可以實作細粒度情感标簽、通用槽位、觀點等資訊的抽取。
- 可解釋資訊抽取。未來資訊抽取也許可以生成可解釋的抽取規則、預測結果的置信度等,實作模型的可解釋、可控制。
[1]TENER: Adapting Transformer Encoder for Named Entity Recognition
[2]Event Extraction via Dynamic Multi-Pooling Convolutional Neural Networks
[3]Meta-Learning with Dynamic-Memory-Based Prototypical Network for Few-Shot Event Detection
[4]Low-Resource Name Tagging Learned with Weakly Labeled Data
[5]Long-tail Relation Extraction via Knowledge Graph Embeddings and Graph Convolution Networks
[6]Matching the Blanks : Distributional Similarity for Relation Learning
[7]Improve Neural Entity Recognition via Multi-Task Data Selection and Constrained Decoding
[8]Reading the Manual : Event Extraction as Definition Comprehension
[9]Attention-Based Capsule Networks with Dynamic Routing for Relation Extraction
[10]ARNOR : Attention Regularization based Noise Reduction for Distant Supervision Relation Classification
[11]Integrating Relation Constraints with Neural Relation Extractors
[12]Open Relation Extraction : Relational Knowledge Transfer from Supervised Data to Unsupervised Data
[13]Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme
[14]Extracting Relational Facts by an End-to-End Neural Model with Copy Mechanism
[15]CopyMTL: Copy Mechanism for Joint Extraction of Entities and Relations with Multi-Task Learning
[16]A General-Purpose Algorithm for Constrained Sequential Inference
[17]Integrating Deep Learning with Logic Fusion for Information Extraction
[18]COMET: Commonsense Transformers for Automatic Knowledge Graph Construction
[19]Entity-Relation Extraction as Multi-Turn Question Answering