一、概述
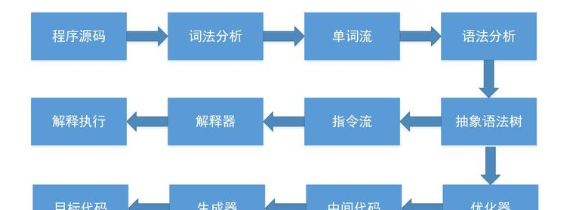
如今,基于實體機、Java虛拟機或者是非 Java 的其他進階語言虛拟機(HLLVM)的語言,大多數都遵循如下現代經典編譯原理的思路,在執行前先對程式源碼進行詞法分析和文法分析處理,把源碼轉化為抽象文法樹。對于一門具體語言的實作來說,詞法和文法分析乃至後面的優化器和目标代碼生成器都可以選擇獨立于執行引擎,形成一個完整意義的編譯器去實作,這類代表是 C/C++ 語言。也可以選擇把其中一部分步驟(如生成抽象文法樹之前的步驟)實作為一個半獨立的編譯器,這類代表是 Java 語言(以下介紹的 javac 編譯器)。又或者把這些步驟和執行引擎全部集中封裝在一個封閉的黑匣子之中,如大多數的 JavaScript 語言。
我們都知道 *.java 檔案要首先被編譯成 *.class 檔案才能被 JVM 認識,這部分的工作主要由 Javac 來完成,類似于 Javac 這樣的我們稱之為
前端編譯器;
但是 *.class 檔案也不是機器語言,怎麼才能讓機器識别呢?就需要 JVM 将 *.class 檔案編譯成機器碼,這部分工作由
JIT 編譯器完成;
除了這兩種編譯器,還有一種直接把 *.java 檔案編譯成本地機器碼的編譯器,我們稱之
AOT 編譯器。

AOT 編譯器一直以來都沒有掀起什麼大風浪,直到 JDK9 中出現的 Jaotc 提前編譯器,這是一個基于 Graal 編譯器實作的新工具,目的是讓使用者可以針對目标機器,為應用程式進行提前編譯。HotSpot 運作時可以直接加載這些編譯的結果,實作加快程式啟動速度,減少程式達到全速運作狀态的時間。但是提前編譯器無可避免的具有破壞平台中立性、導緻位元組膨脹等特點,盡管如此,提前編譯無疑已經成為了一種極限榨取性能的手段,且被官方 JDK 關注,可以預想未來會有一個好的發展。
此外,由于 Jaotc 是基于 Graal 編譯器開發的,是以現在 ZGC 和 Shenandoah 收集器還不支援 Graal 編譯器,自然它們在 Jaotc 上也是無法使用的。事實上,目前 Jaotc 隻支援 G1 和 Parallel 兩種垃圾收集器。
二、javac 的編譯過程
首先,我們先導一份 javac 的源碼(基于 openjdk8)出來,下載下傳位址:https://hg.openjdk.java.net/jdk8/jdk8/langtools/archive/tip.tar.gz,然後将 JDK_SRC_HOME/langtools/src/share/classes/com/sun 目錄下的源檔案全部複制到工程的源碼目錄中,生成的 目錄 如下:
我們執行 com.sun.tools.javac.Main 的 main 方法,就和我們在指令視窗中使用 javac 指令一樣:
從 Sun Javac 的代碼來看,編譯過程大緻可以分為三個步驟:
- 解析和填充符号表過程
- 插入式注解處理器的注解處理過程
- 分析和位元組碼生成過程
這三個步驟所做的工作内容大緻如下:
這三個步驟之間的關系和互動順序如下圖所示,可以看到如果注解處理器在處理注解期間對文法樹進行了修改,編譯器将回到解析和填充符号表的過程進行重新處理,直到注解處理器沒有再對文法樹進行修改為止。
Javac 編譯的入口是 com.sun.tools.javac.main.JavaCompiler 類,上述三個步驟的代碼都集中在這個類的 compile() 和 compile2() 中: