背景
SQLServer為實時更新資料同步提供了CDC機制,類似于Mysql的binlog,将資料更新操作維護到一張CDC表中。
開啟cdc的源表在插入INSERT、更新UPDATE和删除DELETE活動時會插入資料到日志表中。cdc通過捕獲程序将變更資料捕獲到變更表中,通過cdc提供的查詢函數,可以捕獲這部分資料。
CDC的使用條件
1.SQL server 2008及以上的企業版、開發版和評估版;
2.需要開啟代理服務(作業)。
3.CDC需要業務庫之外的額外的磁盤空間。
4.CDC的表需要主鍵或者唯一主鍵。
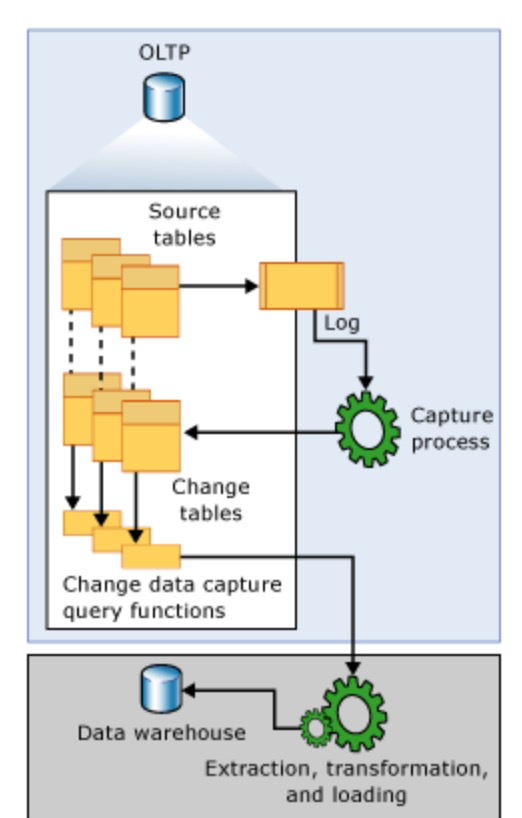
圖1:Sqlserver CDC原理
ADB4PG Sink使用條件
- 需要提前使用建表語句,在ADB4PG端建表,系統不會自動建立(如果有需要可以加這部分功能)
- 每張表需要有主鍵或唯一主鍵
- 目前支援的資料格式:INTEGER,BIGINT,SMALLINT,NUMERIC,DECIMAL,REAL,DOUBLEPERICISION,BOOLEAN,DATE,TIMESTAMP,VARCHAR
環境準備
SQLServer環境準備
- 已有自建SQLServer或雲上RDS執行個體(示例使用雲上RDS SQLServer執行個體)
- 已有windows環境,并安裝SSMS(SQL Server Management Studio),部分指令需要在SSMS執行
SQLServer環境建表
-- 建立源表
create database connect
GO
use connect
GO
create table t1
(
a int NOT NULL PRIMARY KEY,
b BIGINT,
c SMALLINT,
d REAL,
e FLOAT,
f DATETIME,
g VARCHAR
);
-- 開啟db級的cdc
exec sp_rds_cdc_enable_db
-- 驗證資料庫是否開啟cdc成功
select * from sys.databases where is_cdc_enabled = 1
-- 對源表開啟cdc
exec sp_cdc_enable_table @source_schema='dbo', @source_name='t1', @role_name=null; ADB4PG端建立目标表
CREATE DATABASE connect;
create table t1
(
a int NOT NULL PRIMARY KEY,
b BIGINT,
c SMALLINT,
d REAL,
e FLOAT,
f TIMESTAMP,
g VARCHAR
); Kafka環境準備
安裝Kafka Server
1. 下載下傳kafka安裝包,并解壓
SQL Server Source Connect目前隻支援2.1.0及以上版本的Kafka Connect,故需要安裝高版本kafka,執行個體使用kfakf-2.11-2.1.0。 http://kafka.apache.org/downloads?spm=a2c4g.11186623.2.19.7dd34587dwy89h#2.1.0
2. 編輯$KAFKA_HOME/config/server.properties
修改以下參數
...
## 為每台broker配置一個唯一的id号
broker.id=0
...
## log存儲位址
log.dirs=/home/gaia/kafka_2.11-2.1.0/logs
## kafka叢集使用的zk位址
zookeeper.connect=zk1:2181,zk2:2181,zk3:2181
... 3. 啟動kafka server
bin/kafka-server-start.sh config/server.properties 安裝Kafka Connect
1. 修改kafka connect配置檔案
修改$KAFKA_HOME/config/connect-distributed.properties
## kafka server位址
bootstrap.servers=broker1:9092,broker2:9092,broker3:9092
## 為kafka connector標明一個消費group id
group.id=
## 安裝插件的位址,每次kafka connector啟動時會動态加載改路徑下的jar包,可以将每個插件單獨放到一個子路徑
plugin.path= 安裝需要的kafka-connect插件
1. 将插件jar包放在我們在前面已經配置過的配置的plugin.path路徑下
sqlserver-source-connector
https://repo1.maven.org/maven2/io/debezium/debezium-connector-sqlserver/?spm=a2c4g.11186623.2.18.7dd34587dwy89h
oss-sink-connector, 需要使用代碼自行編譯,注意在pom修改依賴的kafka及scala版本号
https://github.com/aliyun/kafka-connect-oss
adb4pg-jdbc-sink-connector,需要下載下傳以下jar包及對應ADB For PG的JDBC驅動
https://yq.aliyun.com/attachment/download/?spm=a2c4e.11153940.0.0.70ed10daVH6ZQO&id=72822. 編輯配置檔案
# CDC connector的配置檔案 sqlserver-cdc-source.json
▽
{
"name": "sqlserver-cdc-source",
"config": {
"connector.class" : "io.debezium.connector.sqlserver.SqlServerConnector",
"tasks.max" : "1",
"database.server.name" : "server1",
"database.hostname" : "database hostname",
"database.port" : "1433",
"database.user" : "xxxx",
"database.password" : "xxxxxx",
"database.dbname" : "connect",
"schemas.enable" : "false",
"mode":"incrementing",
"incrementing.column.name":"a",
"database.history.kafka.bootstrap.servers" : "kafka-broker:9092",
"database.history.kafka.topic": "server1.dbo.t1",
"value.converter.schemas.enable":"false",
"value.converter":"org.apache.kafka.connect.json.JsonConverter"
}
} # oss sink的配置檔案 oss-sink.json
{
"name":"oss-sink",
"config": {
"name":"oss-sink",
"topics":"server1.dbo.testdata",
"connector.class":"com.aliyun.oss.connect.kafka.OSSSinkConnector",
"format.class":"com.aliyun.oss.connect.kafka.format.json.JsonFormat",
"flush.size":"1",
"tasks.max":"4",
"storage.class":"com.aliyun.oss.connect.kafka.storage.OSSStorage",
"partitioner.class":"io.confluent.connect.storage.partitioner.TimeBasedPartitioner",
"timestamp.extractor":"Record",
"oss.bucket":"traffic-csv",
"partition.duration.ms":"10000",
"path.format":"YYYY-MM-dd-HH",
"locale":"US",
"timezone":"Asia/Shanghai",
"rotate.interval.ms":"30000"
}
} 有關oss sinker更詳盡的配置,見文檔
## adb4pg-jdbc-sink配置檔案
{
"name":"adb4pg-jdbc-sink",
"config": {
"name":"adb4pg-jdbc-sink",
"topics":"server1.dbo.t1",
"connector.class":"io.confluent.connect.jdbc.Adb4PgSinkConnector",
"connection.url":"jdbc:postgresql://gp-8vb8xi62lohhh2777o.gpdb.zhangbei.rds.aliyuncs.com:3432/connect",
"connection.user":"xxx",
"connection.password":"xxxxxx",
"col.names":"a,b,c,d,e,f,g",
"col.types":"integer,bigint,smallint,real,doublepericision,timestamp,varchar",
"pk.fields":"a",
"target.tablename":"t1",
"tasks.max":"1",
"auto.create":"false",
"table.name.format":"t1",
"batch.size":"1"
}
} 由于OSS sinker使用了hdfs封裝的FileSystem,需要将OSS相關的資訊維護到$KAFKA_HOME/config/core-site.xml檔案中
<configuration>
<property>
<name>fs.oss.endpoint</name>
<value>xxxxxxx</value>
</property>
<property>
<name>fs.oss.accessKeyId</name>
<value>xxxxxxx</value>
</property>
<property>
<name>fs.oss.accessKeySecret</name>
<value>xxxxxxx</value>
</property>
<property>
<name>fs.oss.impl</name>
<value>org.apache.hadoop.fs.aliyun.oss.AliyunOSSFileSystem</value>
</property>
<property>
<name>fs.oss.buffer.dir</name>
<value>/tmp/oss</value>
</property>
<property>
<name>fs.oss.connection.secure.enabled</name>
<value>false</value>
</property>
<property>
<name>fs.oss.connection.maximum</name>
<value>2048</value>
</property>
</configuration> 3. 啟動已經配置好的kafka-connector插件
啟動及删除connect任務指令
## 啟動指令
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/ -d @sqlserver-cdc-source.json
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/ -d @adb4pg-jdbc-sink.json
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/ -d @oss-sink.json
## 删除指令
curl -s -X DELETE http://localhost:8083/connectors/sqlserver-cdc-source
curl -s -X DELETE http://localhost:8083/connectors/adb4pg-jdbc-sink
curl -s -X DELETE http://localhost:8083/connectors/oss-sink 在ADB For PG擷取更新資料
SQLServer插入贈/更/删資料記錄
insert into t1(a,b,c,d,e,f,g) values(1, 2, 3, 4, 5, convert(datetime,'24-12-19 10:34:09 PM',5), 'h'); 在kafka topic擷取更新結果
先确認是否生成了kafka-connect所需的topic資訊
bin/kafka-topics.sh --zookeeper zk_address --list 
如截圖,connect-configs, connect-offsets, connect-status為kafka-connect用來存儲任務資料更新狀态的topic。schema-changes-inventory是維護sqlserver表結構的topic。
可以通過kafka consloe-consumer上擷取到的topic資訊,以确認cdc資料正确被采集到kafka topic
bin/kafka-console-consumer.sh --bootstrap-server xx.xx.xx.xx:9092 --topic server1.dbo.t1 在ADB For PG上查詢同步過來的資料
注意:因為是不同資料庫之間的同步,時區設定的不同可能會導緻同步結果産生時區偏移,需要在兩側資料庫做好設定。
在OSS檢視更新的資料