日志服務SLS是一款飛天團隊自研産品,服務雲上雲下3W+客戶,并在阿裡經濟體中作為日志資料的基礎設施,在過去幾年中經曆多次雙十一、雙十二、新春紅包錘煉。
在2019雙十一中:
- 服務阿裡經濟體3W+ 應用,1.5W外部獨立客戶
- 峰值30TB/min、單叢集峰值11TB/min
- 單日志峰值600GB/min
- 單業務線峰值1.2TB/min
- 支援核心電商、媽媽、螞蟻、菜鳥、盒馬、優酷、高德、大文娛、中間件、天貓精靈等團隊日志的全量上雲
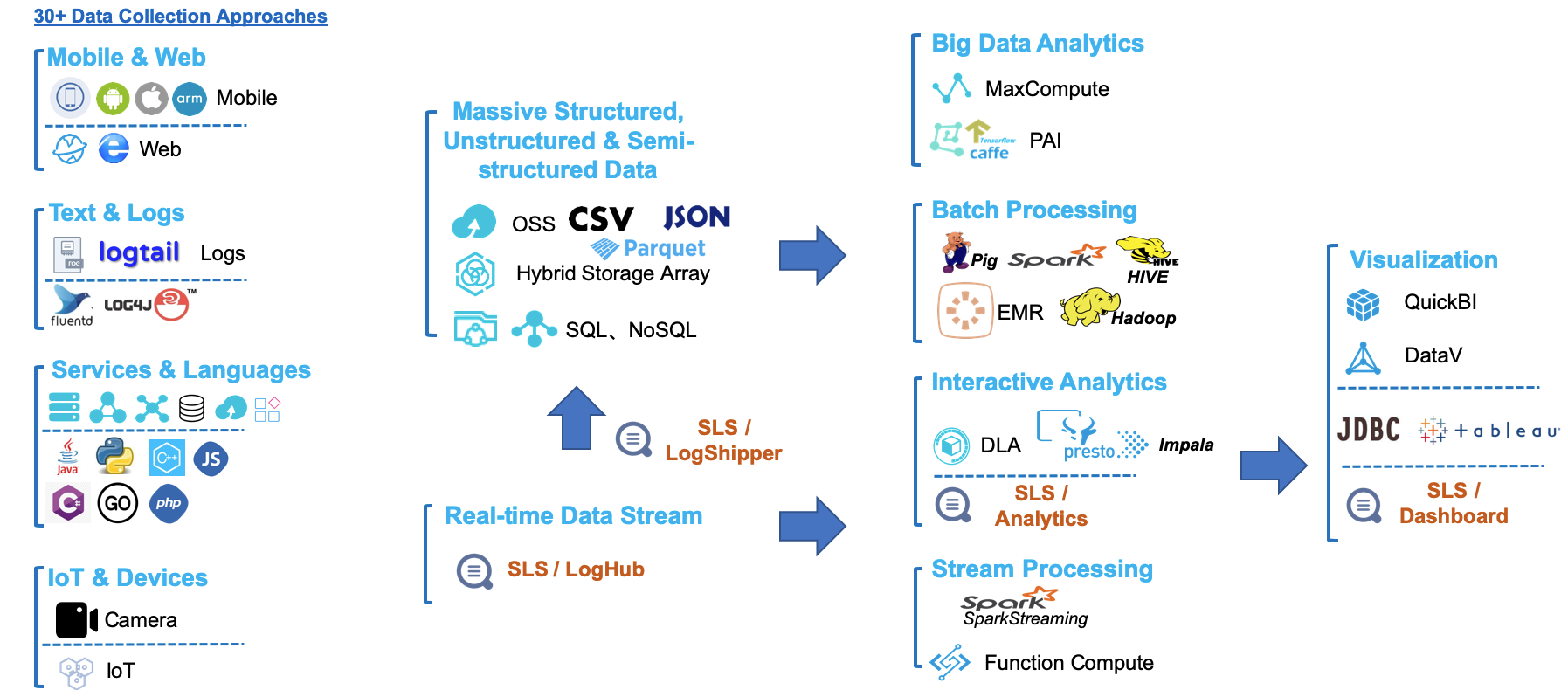
- 與30+資料源、20+資料處理、計算系統無縫打通(如下)
能夠服務這個體量和使用者規模,對産品的功能、體驗、系統的穩定性和可靠性的要求是很高的。感謝阿裡經濟體獨一無二的環境與挑戰,使得我們過去五年中持續不斷地對産品與技術進行考驗與磨煉。
資料管道是企業的基礎設施
資料管道是什麼?
資料管道概念誕生在2009年,提出的是LinkedIn工程師Jay Krep,Jay也是Apache Kafka作者+Confluent公司CEO。2012年他在文章《The Log: What every software engineer should know about real-time data's unifying abstraction》中提到設計管道設施的兩個初衷:
- 解耦生産者與消費者,降低系統對接複雜性
- 定義出統一格式與操作語義

這兩個核心痛點的解決+實時系統的興起使得Kafka類産品在幾年間有了一個量的飛躍,成了脍炙人口的基礎軟體。随着資料分析系統成為企業标配,各大廠商也逐漸将資料管道産品化成服務網際網路的服務,比較有代表性的有:
- AWS:Kinesis
- Azure:EventHub
- IBM:BlueMix Event Pipeline
資料管道(Data Pipeline)是實作系統之間資料遷移的載體,是以包括資料的采集、傳輸鍊路、存儲隊列、消費/轉儲等都屬于資料管道的範疇。在SLS這裡,我們專為資料管道相關的功能集合起了一個單獨的名稱:LogHub,LogHub提供數30+種資料接入方式、提供實時資料管道、對接各類下遊系統等功能。
然而資料管道因足夠底層,在企業數字化過程中擔任重要的業務,必須足夠可靠、足夠穩定、確定資料的通暢,并且能夠彈性滿足流量變化需求。我們把過去5年來我們遇到的挑戰展開,和大家回顧下。
資料管道的挑戰
管道這個概念非常簡單,以至于每個開發者都能用20行代碼寫一個原型出來:
- Immutable隊列,隻支援寫入,不支援更改
- 消費者寫入後傳回,寫入時保序
- 消費者可以根據點位來消費資料
- 資料無法更改,隻能根據TTL(寫入先後順序)進行删除
但在現實過程中,維護一個每天讀寫百億次,幾十PB資料流量,并且被萬級使用者依賴的管道是一件很有挑戰的事情,舉幾個例子:
- 生産者:某個消費者程式寫錯了,突然引起一大波流量把管道入口都占滿了。某些資料源因促銷活動,流量在一個小時内上漲至原先十幾倍或幾百倍
- 消費者:對一個資料源,同時有20+訂閱者來同時消費資料
- 每天有幾百個資料源接入,方式各不相同,需要大量适配
這樣例子每天都在發生,如何把簡單的管道做得不簡單,需要大量的工作,在下面篇幅中我們娓娓道來。
挑戰1:生産者适配
SLS 第一版本支援一類資料源-- 飛天格式的日志檔案,在五年中逐漸擴充到各語言SDK,移動端,嵌入式晶片,物聯網和雲原生等環境:
飛天日志
SLS起源與阿裡雲的飛天項目,當時我們飛天有一個基礎的日志子產品,幾乎所有的系統都會使用這個子產品列印日志,是以最開始我們開發了Logtail用于采集飛天日志,當時的Logtail還隻是一個阿裡雲飛天系統内部使用的工具。
SDK可擴充
随着非阿裡雲團隊使用,是以我們擴充了Logtail,支援通用的日志格式,比如正則、Json、分隔符等等。同時還有很多應用不希望落盤,是以我們提供了各種語言的SDK用于日志上傳的代碼內建。
多平台接入
随着移動網際網路興起,我們專門針對移動端開發了Android、IOS的SDK,便于使用者快速接入日志;這個時間點阿裡也開始了微服務改造、pouch開始上線,Logtail開始相容pouch,同時我們還專門為Java微服務提供Log4J、LogBack的Appender,提供資料直傳的服務。
對ARM平台、嵌入式系統、國産化系統也定制适配用戶端進行接入。
Logtail平台化
在2018年初,為了應對多樣化的需求,我們為Logtail增加了插件功能,有自定義需求的使用者可以通過開發插件的方式擴充Logtail,實作各種豐富的功能;同時我們也緊跟時代步伐,支援雲原生、智能裝置、IoT等新興領域的資料采集
雲原生支援
随着雲原生落地,Logtail的資料采集在18年初就開始全面支援Kubernetes,并提供了CRD(CustomResourceDefinition)用于日志和Kubernetes系統的內建,目前這套方案已經應用在了集團内、公有雲幾千個叢集中。
雲原生後的無盤化
在阿裡高度虛拟化的場景中,一台實體機可能運作上百個容器,傳統的日志落盤采集方式對實體機磁盤的競争很大,會影響日志寫入性能,間接影響應用的RT;同時每天實體機需要為各個容器準備日志的磁盤空間,造成巨大的資源備援。
是以我們和螞蟻系統部合作開展了日志無盤化項目,基于使用者态檔案系統,為應用虛拟出一個日志盤,而日志盤的背後直接通過使用者态檔案系統對接Logtail并直傳到SLS,以最快的方式實作日志可看、可查。
挑戰2:多協定支援
SLS服務端支援HTTP協定寫入,也提供了衆多SDK和Agent,但在很多場景下還是和資料源間有巨大鴻溝,例如:
- 客戶基于開源自建系統,不接受二次改造,希望隻修改一下配置檔案就能接入;
- 很多裝置(交換機、路由器)提供的固定協定,無法使用HTTP協定;
- 各種軟體的監控資訊、二進制格式等,而這些開源Agent可以支援。
為此SLS開展了通用協定适配計劃,除HTTP外還相容Syslog,Kafka、Promethous和JDBC四種協定來相容開源生态。使用者現有系統隻需要修改寫入源即可實作快速接入;已有的路由器、交換機等可以直接配置寫入,無需代理轉發;支援衆多開源采集元件,例如Logstash、Fluentd、Telegraf等。
挑戰3:用戶端(Agent)流控
在2017年前後,我們遇到了另外一個挑戰:單機Agent的多租戶流控,舉一個例子:
- 某主機上有20+種日志,其中有需要對賬的記錄檔,也有級别為Info的程式輸出日志
- 因日志生産者的不可控,在一段時間内可能會大量産生程式輸出日志
- 該資料源會在短時間将采集Agent打爆,引起關鍵資料無法采集、或延遲采集
我們對Agent(Logtail)進行了一系列多租戶隔離優化:
- 通過時間片采集排程保證各個配置資料入口的隔離性和公平性
- 設計多級高低水位回報隊列保證在極低的資源占用下依然可以保證各處理流程間以及多個配置間的隔離性和公平性,
- 采用事件處理不阻塞的機制保證即使在配置阻塞/停采期間發生檔案輪轉依然具有較高的可靠性
- 通過各個配置不同的流控/停采政策以及配置動态更新保證資料采集具備較高的可控性
該功能上線後,經過不斷調優,較好解決了單機上多個資料源(租戶)公平配置設定的問題。
五年雙十一:SLS資料管道發展之路資料管道是企業的基礎設施資料管道的挑戰挑戰1:生産者适配挑戰2:多協定支援挑戰3:用戶端(Agent)流控挑戰4:服務端流控挑戰5:消費端(高并發)挑戰6:消費端(多執行個體與并發)挑戰7:自動化運維其他挑戰:正在解決的問題
挑戰4:服務端流控
除了用戶端流控外,我們在服務端也支援兩種不同的流控方式(Project級、Shard級反壓),防止單執行個體異常在接入層、或後端服務層影響其他租戶。我們專門開發QuotaServer子產品,提供了Project全局流控和Shard級流控兩層流控機制,在百萬級的規模下也能實作秒級的流控同步,保證租戶之間的隔離性以及防止流量穿透導緻叢集不可用。
粗粒度流控:Project級
- 每秒上千個Nginx前端,将各種接收到的Project的流量、請求次數進行彙總,發送至QuotaServer(也是分布式架構,按照Project的進行分區)
- Quota Server彙總所有來自各Nginx的Project統計資訊,計算出每個Project的流量、qps是否超過設定的quota上限,确定否需要禁用Project的各類操作,以及禁用時間
- 對于超過Quota的Project清單,QuotaServer能秒級通知到所有的Nginx前端
- Nginx前端擷取禁用Project清單之後,立刻做出反應,拒絕這些Project的請求
Project全局流控最主要的目的是限制使用者整體資源用量,在前端就拒絕掉請求,防止使用者執行個體的流量穿透後端把整個叢集打爆。真正做到流控更加精細、語義更加明确、可控性更強的是Shard級别流控。
細粒度流控:Shard級
- 每個shard明确定義處理能力, 如5MB/sec寫入,10MB/sec的讀取
- 在shard所在的機器資源有空閑的時候,盡量處理(也有資源消耗上限限制)
- 當shard隊列出現堵塞,根據shard流量是否超過quota,傳回使用者是限流還是系統錯誤(傳回的Http錯誤碼是403還是500),同時将Shard限流資訊通知QuotaServer
- QuotaServer接收到限流資訊後,通過Nginx和QuotaServer之間存在Long pull通道,可瞬時将限流資訊同步至所有的Nginx
- Nginx端獲得Shard的流控資訊之後,對shard進行精确的流控
通過shard級别流控,好處非常明顯:
- 每個shard接收的流量有上限,異常流量在前端Nginx直接被拒絕,在各種情況下,都無法穿透至後端
- Project的流控不作為主要流控手段,隻作為使用者保護手段,防止代碼異常等情況而導緻的流量劇增
- 根據錯誤碼(http code是403還是500),使用者可以和明确知道是被限流了,還是後端日志服務出現問題
- 出現403流控錯誤後,使用者可以直接通過分裂shard方式,來擷取更高的吞吐,使用者獲得更多自主處理權(花錢買資源)
挑戰5:消費端(高并發)
解決日志消費問題還是需要從應用場景出發,SLS作為實時管道,絕大部分消費場景都是實時消費,SLS針對消費場景提供了一層Cache,但Cache政策單一,随着消費用戶端增多、資料量膨脹等問題而導緻命中率越來越低,消費延遲越來越高。後來我們重新設計了緩存子產品:
- 全局緩存管理,對于每一個Shard的消費計算消費權值,優先為權值高的Shard提供緩存空間;
- 更加精細化、啟發式的緩存管理,根據使用者近期時間的消費情況來動态調整緩存大小;
- 對于高保使用者,強制配置設定定量的緩存空間,確定不受其他使用者影響。
上述優化上線後,叢集日志平均消費延遲從5ms降低到了1ms以内,有效緩解雙十一資料消費壓力。
挑戰6:消費端(多執行個體與并發)
在以微服務、雲原生為主導的大背景下,應用被切分的越來越細、整個鍊路也越來越複雜,其中産生的日志種類和數量也越來越多;同時日志的重要性也越來越強,同一個日志可能會有好幾個甚至數十個業務方需要消費。
傳統的方式粗暴簡單,需要日志的人自己去機器上采集,最終一份日志可能被重複采集幾十遍,嚴重浪費用戶端、網絡、服務端的資源。
SLS從源頭上禁止同一檔案的重複采集,日志統一采集到SLS後,我們為使用者提供ConsumerGroup用于實時消費。但伴随着日志的細分化以及日志應用場景的豐富化,SLS的資料消費逐漸暴露出了兩個問題:
- 日志細分場景下,ConsumerGroup無法支援同時消費多組Logstore的日志,其中的日志還可能跨越多個Project、隸屬于多個不同賬号,資源映射和權限歸屬管理越發複雜;
- ConsumerGroup配置設定的最小機關是Shard,SLS的一個Shard在不開啟索引的情況下可以支撐幾十MB/s的寫入,而很多消費端單機并沒有能力處理幾十MB/s的資料,造成嚴重的生産、消費不對等。
View消費模式
針對日志細分場景下的資源映射和權限歸屬管理等問題,我們和螞蟻日志平台團隊合作開發了View消費模式(思路來源于資料庫中View),能夠将不同使用者、不同logstore的資源虛拟成一個大的logstore,使用者隻需要消費虛拟的logstore即可,虛拟logstore的實作以及維護對使用者完全透明。該項目已經在螞蟻叢集正式上線,目前已經有數千個View消費執行個體在工作中。
Fanout消費模式
針對單消費者能力不足的問題,我們對ConsumerGroup進一步增強,開發了Fanout消費模式,在Fanout模式下,一個Shard中的資料可交由多個消費者處理,将Shard與消費者解耦,徹底解生産者消費者能力不比對的問題。同時消費端無需關心Checkpoint管理、Failover等細節,Fanout消費組内部全部接管。
挑戰7:自動化運維
SLS對外SLA承諾99.9%服務可用性(實際99.95%+),剛開始的時候我們很難達到這樣的名額,每天收到很多告警,經常夜裡被電話Call醒,疲于處理各種問題。總結下來主要的原因有2點:
- 熱點問題:SLS會把Shard均勻排程到各個Worker節點,但每個Shard實際負載不一而且随着時間會動态變化,經常由于一些熱點Shard存在同一台機器而導緻請求變慢甚至超出服務能力;
- 出現問題定位時間太長:線上問題終究不可避免,為了實作99.9%的可靠性,我們必須能夠在最短的時間内定位問題,及時止血。雖然有很多監控和日志,但人工去定位問題還是要花很多時間。
自動熱點消除
針對熱點問題,我們在系統中增加了排程角色,通過實時資料收集和統計後,自動做出調整,來消除系統中存在的熱點,主要有以下兩個手段:
- 自動負載均衡
- 系統實時統計各節點的負載,以及節點上每個資料分區對于資源的消耗(CPU、MEM、NET等資源)
- 負載資訊彙報至排程器,排程器自動發現目前是否有節點處于高負載情況
- 對于負載過高節點,通過優化組合的方式,将高壓力資料分區,自動遷移到負載低的節點,達到資源負載均衡的目的
- 自動分裂
- 實時監控每個Shard負載壓力
- 如果發現持續超過單分片處理上限,則啟動分裂
- 舊的分區變成Readonly,生成2個新的分區,遷移至其他節點
實際場景下有很多情況需要特殊考慮,例如颠簸情況、異構機型、并發排程、遷移的負面影響等,這裡就不再展開。
秒級流量分析(Root Cause Analysis)
目前SLS線上收集了數千種實時名額,每天的通路日志有上千億,出現問題時純粹手工調查難度非常大。為此我們專門開發了根因分析相關算法,通過頻繁集和差異集的方式,快速定位和異常最相關的資料集合。
如樣例中,将出現錯誤(status >= 500)的通路資料集,定義為異常集合A,在這個集合發現90%的請求,都是由ID=1002引起,是以值得懷疑,目前的錯誤和ID=1002有關,同時為了減少誤判,再從正常的資料集合B(status <500)中,檢視ID=1002的比例,發現在集合B中的該ID比例較低,是以更加強系統判斷,目前異常和這個ID=1002有非常高的相關性。
借助此種方法大大縮短了我們問題調查的時間,在報警時我們會自動帶上根因分析結果,很多時候收到告警時就已經能夠定位具體是哪個使用者、哪台機器還是哪個子產品引發的問題。
其他挑戰:正在解決的問題
1. Shardless
為了便于水準擴充我們引入了Shard的概念(類似Kafka Partition),使用者可以通過分裂Shard、合并Shard來實作資源的伸縮,但這些概念也會為使用者帶來很多使用上的困擾,使用者需要去了解Shard的概念、需要去預估流量配置設定Shard數、有些時候因為Quota限制還需要手動分裂...
優秀的産品應該對使用者暴露盡可能少的概念,未來我們會弱化甚至去除Shard概念,對于使用者而言,SLS的資料管道隻需要聲明一定的Quota,我們就會按照對應的Quota服務,内部的分片邏輯對使用者徹底透明,做到管道能力真正彈性。
2. 從At Least Once到Exactly Once
和Kafka一樣,SLS目前支援At Least Once寫入和消費方式,但很多核心場景(交易、結算、對賬、核心事件等)必須要求Exactly Once,現在很多業務隻能通過在上層包裝一層去重邏輯來Work around,但實作代價以及資源消耗巨大。
馬上我們會支援寫入和消費的Exactly Once語義,且Exactly Once語義場景下也将支援超大流量和高并發。
3. LogHub Select功能(過濾下推)
和Kafka類似,SLS支援的消費是Logstore級别的全量消費方式,如果業務隻需要其中的一部分資料,也必須将這段時間的所有資料全量消費才能得到。所有的資料都要從服務端傳輸到計算節點再進行處理,這種方式對于資源的浪費極其巨大。
是以未來我們會支援計算下推到隊列内部,可以直接在隊列内進行無效資料過濾,大大降低無效的網絡傳輸和上層計算代價。
大家在使用SLS中遇到的任何問題,請加釘釘群,我們有專門的日志女仆24小時線上答疑,還有火鍋哥和燒烤哥專業支援!~
另外歡迎對大資料、分布式、機器學習等有興趣的同學加入,轉崗、内推,來者不拒,請用履歷狠狠的砸我!~