本文節選自《不一樣的 雙11 技術:阿裡巴巴經濟體雲原生實踐》一書
作者 | 湯志敏,阿裡雲容器服務進階技術專家
在 2019 年 雙11 中,容器服務 ACK 支撐了阿裡巴巴内部核心系統容器化和阿裡雲的雲産品本身,也将阿裡巴巴多年的大規模容器技術以産品化的能力輸出給衆多圍繞 雙11 的生态公司。通過支撐來自全球各行各業的容器雲,容器服務沉澱了支援單元化全球化架構和柔性架構的雲原生應用托管中台能力,管理了超過 1W 個以上的容器叢集。本文将會介紹容器服務在海量 Kubernetes 叢集管理上的實踐經驗。
什麼是海量 Kubernetes 叢集管理?
大家可能之前看過一些分享,介紹了阿裡巴巴如何管理單叢集 1W 節點的最佳實踐,管理大規模節點是一個很有意思的挑戰。不過這裡講的海量 Kubernetes 叢集管理,會側重講如何管理超過 1W 個以上不同規格的 Kubernetes 叢集。根據我們和一些同行的溝通,往往一個企業内部隻要管理幾個到幾十個 Kubernetes 叢集,那麼我們為什麼需要考慮管理如此龐大數量的 Kubernetes 叢集?
- 首先,容器服務 ACK 是阿裡雲上的雲産品,提供了 Kubernetes as a Service 的能力,面向全球客戶,目前已經在全球 20 個地域支援;
- 其次,得益于雲原生時代的發展,越來越多的企業擁抱 Kubernetes,Kubernetes 已經逐漸成為雲原生時代的基礎設施,成為 platform of platform。
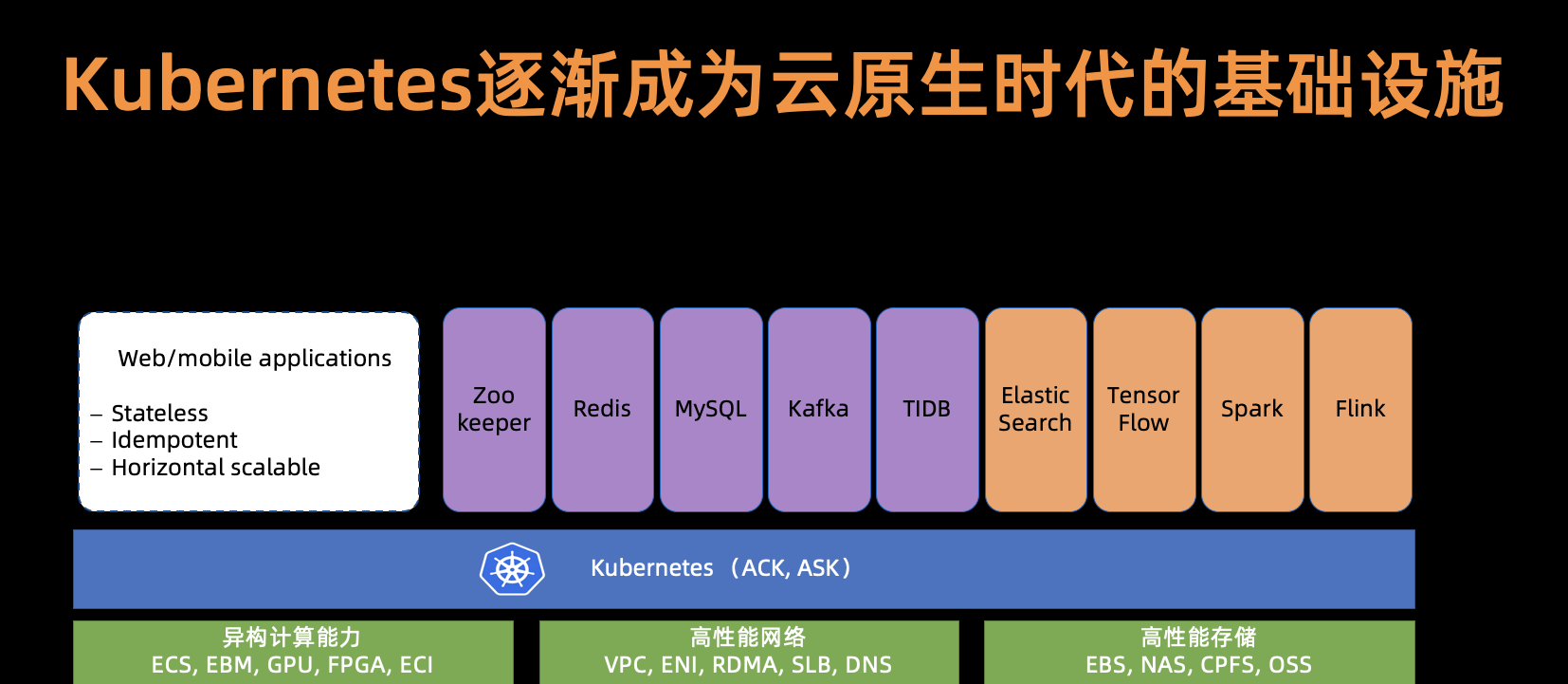
背景介紹

首先我們一起來看下托管這些 Kubernetes 叢集的痛點:
1.叢集種類不同:有标準的、無伺服器的、AI 的、裸金屬的、邊緣、Windows 等 Kubernetes 叢集。不同種類的叢集參數、元件和托管要求不一樣,并且需要支撐更多面向垂直場景的 Kubernetes;
2.叢集大小不一:每個叢集規模大小不一,從幾個節點到上萬個節點,從幾個 service 到幾千個 service 等,需要能夠支撐每年持續幾倍叢集數量的增長;
3.叢集安全合規:分布在不同的地域和環境的 Kubernetes 叢集,需要遵循不同的合規性要求。比如歐洲的 Kubernetes 叢集需要遵循歐盟的 GDPR 法案,在中國的金融業和政務雲需要有額外的等級保護等要求;
4.叢集持續演進:需要能夠持續的支援 Kubernetes 的新版本新特性演進。
設計目标:
- 支援單元化的分檔管理、容量規劃和水位管理;
- 支援全球化的部署、釋出、容災和可觀測性;
- 支援柔性架構的可插拔、可定制、積木式的持續演進能力。
1.支援單元化的分檔管理、容量規劃和水位管理
單元化
一般講到單元化,大家都會聯想到單機房容量不夠或二地三中心災備等場景。那單元化和 Kubernetes 管理有什麼關系?
對我們來說,一個地域(比如:杭州)可能會管理幾千個 Kubernetes,需要統一維護這些 Kubernetes 的叢集生命周期管理。作為一個 Kubernetes 專業團隊,一個樸素的想法就是通過多個 Kubernetes 元叢集來管理這些 guest K8s master。而一個 Kubernetes 元叢集的邊界就是一個單元。
曾經我們經常聽說某某機房光纖被挖斷,某某機房電力因故障而導緻服務中斷,容器服務 ACK 在設計之初就支援了同城多活的架構形态,任何一個使用者 Kubernetes 叢集的 master 元件都會自動地分散在多個機房,不會因單機房問題而影響叢集穩定性;另外一個層面,同時要保證 master 元件間的通信穩定性,容器服務 ACK 在打散 master 時排程政策上也會盡量保證 master 元件間通信延遲在毫秒級。
分檔化
大家都知道,Kubernetes 叢集的 master 元件的負載主要與 Kubernetes 叢集的節點規模、worker 側的 controller 或 workload 等需要與 kube-apiserver 互動的元件數量和調用頻率息息相關,對于上萬個 Kubernetes 叢集,每個使用者 Kubernetes 叢集的規模和業務形态都千差萬别,我們無法用一套标準配置來去管理所有的使用者 Kubernetes 叢集。
同時,從成本經濟角度考慮,我們提供了一種更加靈活、更加智能的托管能力。考慮到不同資源類型會對 master 産生不同的負載壓力,是以我們需要為每類資源設定不同的因子,最終可歸納出一個計算範式,通過此範式可計算出每個使用者 Kubernetes 叢集 master 所适應的檔位。另外,我們也會基于已建構的 Kubernetes 統一監控平台實時名額來不斷地優化和調整這些因素值和範式,進而可實作智能平滑換擋的能力。
容量規劃
接下來我們看下 Kubernetes 元叢集的容量模型,單個元叢集到底能托管多少個使用者 Kubernetes 叢集的 master?
- 首先,要确認容器網絡規劃。這裡我們選擇了阿裡雲自研的高性能容器網絡 Terway, 一方面需要通過彈性網卡 ENI 打通使用者 VPC 和托管 master 的網絡,另一方面提供了高性能和豐富的安全政策;
- 接下來,我們需要結合 VPC 内的 ip 資源,做網段的規劃,分别提供給 node、pod 和 service。
- 最後,我們會結合統計規律,結合成本、密度、性能、資源配額、檔位配比等多種因素的綜合考量,設計每個元叢集單元中部署的不同檔位的 guest Kubernetes 的個數,并預留 40% 的水位。
2.支援全球化的部署、釋出、容災和可觀測性
容器服務已經在全球 20 個地域支援,我們提供了完全自動化的部署、釋出、容災和可觀測性能力,接下來将重點介紹全球化跨資料中心的可觀測。
全球跨資料中心的可觀測性
全球化布局的大型叢集的可觀測性,對于 Kubernetes 叢集的日常保障至關重要。如何在紛繁複雜的網絡環境下高效、合理、安全、可擴充的采集各個資料中心中目标叢集的實時狀态名額,是可觀測性設計的關鍵與核心。
我們需要兼顧區域化資料中心、單元化叢集範圍内可觀測性資料的收集,以及全局視圖的可觀測性和可視化。基于這種設計理念和客觀需求,全球化可觀測性必須使用多級聯合方式,也就是邊緣層的可觀測性實作下沉到需要觀測的叢集内部,中間層的可觀測性用于在若幹區域内實作監控資料的彙聚,中心層可觀測性進行彙聚、形成全局化視圖以及告警。
這樣設計的好處在于可以靈活地在每一級别層内進行擴充以及調整,适合于不斷增長的叢集規模,相應的其他級别隻需調整參數,層次結構清晰;網絡結構簡單,可以實作内網資料穿透到公網并彙聚。
針對該全球化布局的大型叢集的監控系統設計,對于保障叢集的高效運轉至關重要,我們的設計理念是在全球範圍内将各個資料中心的資料實時收集并聚合,實作全局視圖檢視和資料可視化,以及故障定位、告警通知。
進入雲原生時代,Prometheus 作為 CNCF 第二個畢業的項目,天生适用于容器場景,Prometheus 與 Kubernetes 結合一起,實作服務發現和對動态排程服務的監控,在各種監控方案中具有很大的優勢,實際上已經成為容器監控方案的标準,是以我們也選擇了 Prometheus 作為方案的基礎。
針對每個叢集,需要采集的主要名額類别包括:
- OS 名額,例如節點資源(CPU, 記憶體,磁盤等)水位以及網絡吞吐;
- 元叢集以及使用者叢集 Kubernetes master 名額,例如 kube-apiserver, kube-controller-manager, kube-scheduler 等名額;
- Kubernetes 元件(kubernetes-state-metrics,cadvisor)采集的關于 Kubernetes 叢集狀态;
- etcd 名額,例如 etcd 寫磁盤時間,DB size,Peer 之間吞吐量等等。
當全局資料聚合後,AlertManager 對接中心 Prometheus,驅動各種不同的告警通知行為,例如釘釘、郵件、短信等方式。
監控告警架構
為了合理地将監控壓力負擔分到多個層次的 Prometheus 并實作全局聚合,我們使用了聯邦 Federation 的功能。在聯邦叢集中,每個資料中心部署單獨的 Prometheus,用于采集目前資料中心監控資料,并由一個中心的 Prometheus 負責聚合多個資料中心的監控資料。
基于 Federation 的功能,我們設計的全球監控架構圖如下,包括監控體系、告警體系和展示體系三部分。
監控體系按照從元叢集監控向中心監控彙聚的角度,呈現為樹形結構,可以分為三層:
- 邊緣 Prometheus
為了有效監控元叢集 Kubernetes 和使用者叢集 Kubernetes 的名額、避免網絡配置的複雜性,将 Prometheus 下沉到每個元叢集内。
- 級聯 Prometheus
級聯 Prometheus 的作用在于彙聚多個區域的監控資料。級聯 Prometheus 存在于每個大區域,例如中國區、歐洲區、美洲區、亞洲區。每個大區域内包含若幹個具體的區域,例如北京、上海、東京等。随着每個大區域内叢集規模的增長,大區域可以拆分成多個新的大區域,并始終維持每個大區域内有一個級聯 Prometheus,通過這種政策可以實作靈活的架構擴充和演進。
- 中心 Prometheus
中心 Prometheus 用于連接配接所有的級聯 Prometheus,實作最終的資料聚合、全局視圖和告警。為提高可靠性,中心 Prometheus 使用雙活架構,也就是在不同可用區布置兩個 Prometheus 中心節點,都連接配接相同的下一級 Prometheus。
圖2-1 基于 Prometheus Federation 的全球多級别監控架構
優化政策
1.監控資料流量與 API server 流量分離
API server 的代理功能可以使得 Kubernetes 叢集外通過 API server 通路叢集内的 Pod、Node 或者 Service。
圖3-1 通過 API Server 代理模式通路 Kubernetes 叢集内的 Pod 資源
常用的透傳 Kubernetes 叢集内 Prometheus 名額到叢集外的方式是通過 API server 代理功能,優點是可以重用 API server 的 6443 端口對外開放資料,管理簡便;缺點也明顯,增加了 API server 的負載壓力。
如果使用 API Server 代理模式,考慮到客戶叢集以及節點都會随着售賣而不斷擴大,對 API server 的壓力也越來越大并增加了潛在的風險。對此,針對邊緣 Prometheus 增加了 LoadBalancer 類型的 service,監控流量完全 LoadBalancer,實作流量分離。即便監控的對象持續增加,也保證了 API server 不會是以增加 Proxy 功能的開銷。
2.收集指定 Metric
在中心 Prometheus 隻收集需要使用的名額,一定不能全量抓取,否則會造成網絡傳輸壓力過大丢失資料。
3.Label 管理
Label 用于在級聯 Prometheus 上标記 region 和元叢集,是以在中心 Prometheus 彙聚是可以定位到元叢集的顆粒度。同時,盡量減少不必要的 label,實作資料節省。
3.支援柔性架構的可插拔、可定制、積木式的持續演進能力
前面兩部分簡要描述了如何管理海量 Kubernetes 叢集的一些思考,然而光做到全球化、單元化的管理還遠遠不夠。Kubernetes 能夠成功,包含了聲明式的定義、高度活躍的社群、良好的架構抽象等因素,Kubernetes 已經成為雲原生時代的 Linux。
我們必須要考慮 Kubernetes 版本的持續疊代和 CVE 漏洞的修複,必須要考慮 Kubernetes 相關元件的持續更新,無論是 CSI、CNI、Device Plugin 還是 Scheduler Plugin 等等。為此我們提供了完整的叢集群組件的持續更新、灰階、暫停等功能。
元件可插拔
元件檢查
元件更新
2019 年 6 月,阿裡巴巴将内部的雲原生應用自動化引擎 OpenKruise 開源,這裡我們重點介紹下其中的 BroadcastJob 功能,它非常适用于每台 worker 機器上的元件進行更新,或者對每台機器上的節點進行檢測。(Broadcast Job 會在叢集中每個 node 上面跑一個 pod 直至結束。類似于社群的 DaemonSet, 差別在于 DaemonSet 始終保持一個 pod 長服務在每個 node 上跑,而 BroadcastJob 中最終這個 pod 會結束。)
叢集模闆
此外,考慮不同 Kubernetes 使用場景,我們提供了多種 Kubernetes 的 cluster profile,可以友善使用者進行更友善的叢集選擇。我們會結合大量叢集的實踐,持續提供更多更好的叢集模闆。
總結
随着雲計算的發展,以 Kubernetes 為基礎的雲原生技術持續推動行業進行數字化轉型。
容器服務 ACK 提供了安全穩定、高性能的 Kubernetes 托管服務,已經成為雲上運作 Kubernetes 的最佳載體。在本次 雙11,容器服務 ACK 在各個場景為 雙11 做出貢獻,支撐了阿裡巴巴内部核心系統容器化上雲,支撐了阿裡雲微服務引擎 MSE、視訊雲、CDN 等雲産品,也支撐了 雙11 的生态公司和 ISV 公司,包括聚石塔電商雲、菜鳥物流雲、東南亞的支付系統等等。
容器服務 ACK 會持續前行,持續提供更高更好的雲原生容器網絡、存儲、排程和彈性能力、端到端的全鍊路安全能力、serverless 和 servicemesh 等能力。
有興趣的開發者,可以前往
阿裡雲控制台,建立一個 Kubernetes 叢集來體驗。同時也歡迎容器生态的合作夥伴加入阿裡雲的容器應用市場,和我們一起共創雲原生時代。
本書亮點
- 雙11 超大規模 K8s 叢集實踐中,遇到的問題及解決方法詳述
- 雲原生化最佳組合:Kubernetes+容器+神龍,實作核心系統 100% 上雲的技術細節
- 雙 11 Service Mesh 超大規模落地解決方案
“ 阿裡巴巴雲原生微信公衆号(ID:Alicloudnative)關注微服務、Serverless、容器、Service Mesh等技術領域、聚焦雲原生流行技術趨勢、雲原生大規模的落地實踐,做最懂雲原生開發者的技術公衆号。”
更多相關資訊,請關注“
阿裡巴巴雲原生”。