背景
随着網際網路架構的流行,越來越多的系統開始走向分布式化、微服務化。如何快速發現和定位分布式系統下的各類性能瓶頸成為了擺在開發者面前的難題。借助分布式追蹤系統的調用鍊路還原能力,開發者可以完整地了解一次請求的執行過程和詳細資訊。但要真正分析出系統的性能瓶頸往往還需要鍊路拓撲、應用依賴分析等工具的支援。這些工具使用起來雖然簡單,但其背後的原理是什麼?本文将帶您一起探索。
Jaeger 作為從 CNCF 畢業的第七個項目,已經成為了雲原生架構下分布式追蹤系統的第一選擇。本文将以 Jaeger 為例,介紹基于 Tracing 資料的拓撲關系生成原理,文中使用的版本為
1.14
。
Jaeger 架構
筆者曾在 2018 年初基于 Jaeger 1.2.0 做過一些開發,參見
《開放分布式追蹤(OpenTracing)入門與 Jaeger 實作》。經過十多個版本的發展,Jaeger 的架構發生了一些變化,目前在大規模生産環境中推薦下面 2 種部署模式。
Direct to storage
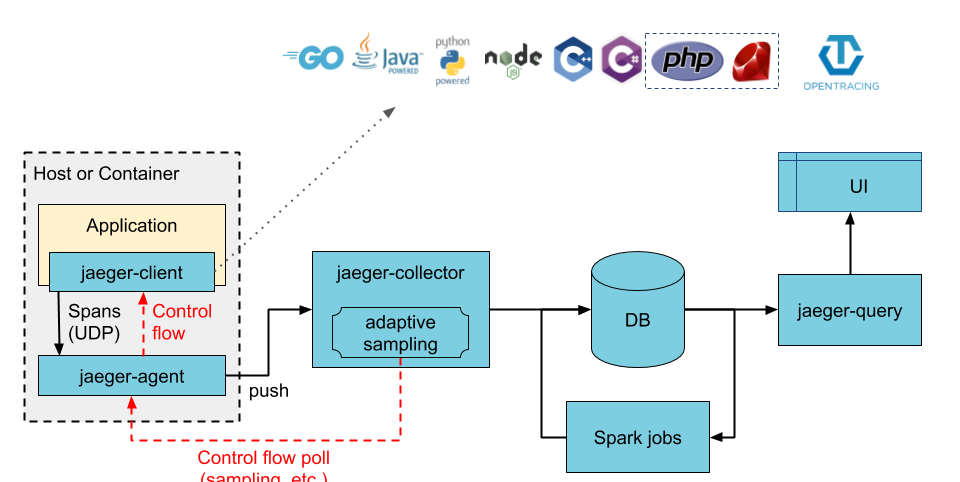
Collector 将采集到的 trace 資料直接寫入 DB,Spark jobs 定期讀取這些 trace 資料并将計算出的拓撲關系再次寫入 DB 中。
Kafka as intermediate buffer

Collector 将采集到的 trace 資料寫入中間緩沖區 Kafka 中,Ingerster 讀取 Kafka 中的資料并持久化到 DB 裡。同時,Flink jobs 持續讀取 Kafka 中的資料并将計算出的拓撲關系寫入 DB 中。
Jaeger 元件
一個完整的 Jaeger 系統由以下幾部分組成。
- Jaeger client libraries - 為不同語言實作了符合 OpenTracing 标準的 SDK。應用程式通過 API 寫入資料,client library 把 trace 資訊按照應用程式指定的采樣政策傳遞給 jaeger-agent。
- Agent - 它是一個監聽在 UDP 端口上接收 span 資料的網絡守護程序,它會将資料批量發送給 collector。它被設計成一個基礎元件,部署到主控端或容器裡。Agent 将 client library 和 collector 解耦,為 client library 屏蔽了路由和發現 collector 的細節。
- Collector - 接收 jaeger-agent 發送過來的 trace 資料,然後在處理管道中對它們進行驗證、索引、轉換并最終完成持久化存儲。Jaeger 的存儲元件被設計成可插拔的,目前官方支援 Cassandra 、 Elasticsearch 和 Kafka
- Query - 接收查詢請求,然後從後端存儲元件中檢索 trace 并通過 UI 進行展示。
- Ingester - 負責從 Kafka 中讀取資料然後寫入另一個存儲後端。
拓撲關系生成
下圖是 Jaeger 官方提供的微服務應用
Hot R.O.D.的服務間拓撲關系。通過此圖,開發者可以清楚地了解過去一段時間裡服務間的調用關系和調用次數。
由于生産環境中的 trace 資料量巨大,每次查詢時通過掃描資料庫中的全量資料來建構拓撲關系不切實際。是以,Jaeger 提供了基于 Spark jobs 和 Flink jobs 兩種從 trace 資料中提取拓撲關系的方法。
Jaeger Spark dependencies
是一個 Spark 任務,它從特定的後端存儲中讀取 span 資料,計算服務間的拓撲關系,并将結果存儲起來供 UI 展示。目前支援的後端存儲類型有 Cassandra 和 Elasticsearch。 由于 Cassadra 和 Elasticsearch 計算拓撲關系的邏輯大同小異,下面将以 Elasticsearch 為例進行分析。
Span 資料組織結構
Jaeger 會根據 span 的 StartTime 字段将它們寫到 Elasticsearch 以天為機關的 index 裡,存放 span 的 index 組織結構如下:
jaeger-span-2019-11-11
jaeger-span-2019-11-12
jaeger-span-2019-11-13
... 拓撲關系計算流程
Spark job 每次運作都會重新計算指定日期的服務間拓撲關系,具體流程如下:
- 根據傳入的日期定位存放 span 資料的 index,例如傳入的日期是
2019-11-11
jaeger-span-2019-11-11
- 将目标 index 中的 span 資料按 traceID 進行分組,得到
Map(traceID: Set(span))
- 針對單個 trace,周遊該 trace 的所有 span,計算出對應的拓撲關系
List<dependency>
- 将
Map(traceID: List<dependency>)
- 将計算結果寫入 Elasticsearch 用于存放拓撲關系的 index 裡。例如
jaeger-span-2019-11-11
jaeger-dependencies-2019-11-11
拓撲關系查詢
查詢時會根據傳入的 lookback 查詢對應時間段的 dependency 資料,預設為過去 24 小時。查詢過程很簡單:
- 找出和指定時間範圍有交集的所有 dependency index。
- 從這些 index 中過濾出符合要求的所有 dependency。
- 将 dependency 在 UI 層進行聚合展示。
Jaeger Analytics
是一個 Flink 任務,它從 Kafka 中消費 span 資料,實時計算服務間的拓撲關系,最後将計算結果寫入 Cassadra 中。
将 Kafka 設為 source
這裡将 Kafka 設定為 Flink 任務的 source,此時 span 資料将不斷地從 Kafka 流向 Flink 任務。
将離散的 span 聚合成 trace
DataStream<Iterable<Span>> traces = spans
.filter((FilterFunction<Span>) span -> span.isClient() || span.isServer())
.name(FILTER_LOCAL_SPANS)
.keyBy((KeySelector<Span, String>) span -> String
.format("%d:%d", span.getTraceIdHigh(), span.getTraceIdLow()))
.window(EventTimeSessionWindows.withGap(Time.minutes(3)))
.apply(new SpanToTraceWindowFunction()).name(SPANS_TO_TRACES)
.map(new AdjusterFunction<>()).name(DEDUPE_SPAN_IDS)
.map(new CountSpansAndLogLargeTraceIdFunction()).name(COUNT_SPANS); -
filter((FilterFunction<Span>) span -> span.isClient() || span.isServer())
-
keyBy((KeySelector<Span, String>) span -> String.format("%d:%d", span.getTraceIdHigh(), span.getTraceIdLow()))
-
window(EventTimeSessionWindows.withGap(Time.minutes(3)))
-
SpanToTraceWindowFunction
-
AdjusterFunction
-
CountSpansAndLogLargeTraceIdFunction
計算 dependencies
DataStream<Dependency> dependencies = traces
.flatMap(new TraceToDependencies()).name(TRACE_TO_DEPENDENCIES)
.keyBy(key -> key.getParent() + key.getChild())
.timeWindow(Time.minutes(30))
.sum("callCount").name(PREAGGREGATE_DEPENDENCIES); -
flatMap(new TraceToDependencies())
-
keyBy(key -> key.getParent() + key.getChild())
-
timeWindow(Time.minutes(30)).sum("callCount")
将 Cassandra 設為 sink
這裡将 Cassandra 設定為 Flink 任務的 sink,當依賴關系因滿足時間視窗的觸發條件被計算完畢後,将以
dependencies(ts, ts_index, dependencies)
的形式持久化到 Cassandra 中。
根據指定的時間範圍過濾出所有符合要求的 dependency,然後在 UI 層進行聚合展示。從 Cassandra 查詢 dependency 使用的 CQL 如下。
SELECT ts, dependencies FROM dependencies WHERE ts_index >= startTs AND ts_index < endTs 總結
Spark jobs、Flink jobs 兩種計算拓撲關系的方案雖然在細節上有所不同,但整體流程非常相似,可總結成下圖。
對于 Jaeger Spark dependencies, 拓撲關系的精确程度和 Spark job 的執行頻率密切相關。執行頻率越高,查詢結果越精确,但消耗的計算資源也會越多。舉個例子,如果 Spark job 每小時運作一次,拓撲關系可能無法反映最近一小時服務間的調用情況。
對于 Jaeger Analytics,它以 Kafka 作為緩存,增量地處理到達的 span 資料,具有更好的實時性。如果對最近時間拓撲關系的精确程度有比較高的要求,建議選用 Jaeger Analytics 方案。