計算噪聲功率譜程式(WebRtcNs_AnalyzeCore)
計算信噪比函數之前的部分分别是:
1.對輸入的時域幀資料進行加窗、FFT變換。
2.然後計算能量,若能量為0,傳回;否則繼續往下。
3.然後計算新的能量和幅度。
4.使用分位數噪聲估計進行初始噪聲估計。
5.然後取前50個幀,計算得到高斯白噪聲、粉紅噪聲模型,聯合白噪聲、粉紅噪聲模型,得到模組化的混合噪聲模型。
計算信噪比(ComputeSnr)
作用:根據分位數噪聲估計計算前後信噪比
Inputs:
|magn|.信号幅度譜估計
|noise| 噪聲幅度譜估計
Outputs:
|snrLocPrior|先驗SNR
|snrLocPost| 後驗SNR
後驗信噪比指觀測到的能量與噪聲功率相關的輸入功率相比的瞬态SNR:
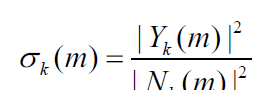
其中Y是輸入含噪聲的頻譜, N是噪聲頻譜,先驗SNR是與噪聲功率相關的純淨(未必是語音)信号功率的期望值,可表示為:

其中X是指輸入的純淨信号,這裡對應的指語音信号。在WebRTC實際的計算中,并沒有采用平方數量級,而是采用了量級數量級。
由于純淨信号是未知信号,先驗SNR的估計是上一幀經估計的先驗SNR和瞬态SNR的平均值:
上式中H對應與代碼中的smooth是上一幀的維納濾波器,用于對瞬時SNR平滑,前一項是上一幀的先驗SNR,後一項是先驗SNR的瞬态估計。其通過判決引導DD進行跟新,時間平滑參數是 ,其值越大,流暢度越高,延遲也會越大,程式中選擇的是0.98。
特征提取(FeatureUpdate)
作用:提取平均LRT參數、頻譜差異、頻譜平坦度
// * |magn| is the signal magnitude spectrum estimate.
// * |updateParsFlag| is an update flag for parameters.
計算頻譜平坦度(ComputeSpectralFlatness)
作用:頻譜平坦度計算。
原理:該算法假設語音比噪聲有更多的諧波。語音頻譜往往會在基頻(基音)和諧波中出現峰值,而噪聲頻譜則相對平坦。是以其作為區分噪聲和語音的一個特征。
頻譜度計算時N表示STFT後頻率點數,B代表頻率帶的數量,K是頻點指數,j是頻帶指數。每個頻帶包括大量的頻率點。就128個頻率點可分成4個頻帶(低帶,中低頻帶,中高頻帶,高頻),每個頻帶32個頻點。對于噪聲Flatness偏大且為常數,而對于語音,計算出的數量則偏下且為變量。
根據上面的公式,如果接近于1,則是噪聲,(噪聲的幅度譜趨于平坦),二對于語音,上面的N次根是對乘積結果進行N次縮小,相比于分母部分,縮小的數量級是倍數的,是以語音的平坦度較小,是趨近于0的。
計算頻譜差異度(ComputeSpectralDifference)
作用:計算輸入譜模闆(學習到的)噪聲譜的差異程度。所參考的噪聲譜是self->magnAvgPause[i],傳回值是正則化的頻譜差異,為self->featureData[4]。
除了頻譜平坦度特征的噪聲相關假設之外,有關噪聲頻譜的另一個假設是,噪聲頻譜比語音頻譜更穩定。是以,可假設噪聲頻譜的整體形狀在任何給定階段都傾向與保持相同。模闆頻譜通過更新頻譜(最初被設為零)中極有可能是噪聲或語音停頓的區段來确定。該比較結果是對噪聲的保守估計,其中僅對語音機率确定低于門檻值(如 的區段處跟新了噪聲。在其它分布中,模闆頻譜也可能被導入到算法中,或從對應不同噪聲的形狀中篩選出來。考慮到輸入頻譜 和模闆頻譜(表示為 ),如想獲得頻譜模闆差異特征,可首先将頻譜差異測量定義為 ,其中α和u是形狀參數,包括線性位移和振幅參數,是通過将J最小化獲得的。(α,u) 通過線性方程獲得,是以可對每個幀輕松抽取此參數。在某些示例中,這些參數可表明輸入頻譜(在音量增加的情況下)的任何簡機關移/标度變化。之後該特征将成為标準話的測度。 語音噪聲機率更新(SpeechNoiseProb)
作用:計算語音/噪聲機率,存儲在probSpeechFinal。
magn:輸入幅度譜。noise:噪聲譜
理論基礎
先推導語音/噪聲機率計算方法,先來看語音/噪聲的機率模型,定義語音狀态為 ,定義噪聲狀态為 ,其中m是幀,k是頻率,則語音/噪聲的機率可以表示為: 。這一機率取決于觀測到的額噪聲輸入頻譜系數 以及所處理信号的一些特征資料(如信号的分類特征),也就是這裡的{F}。特征資料可以是有噪輸入頻譜,過往頻譜資料,模型資料等。如特征資料{F}可以包括頻譜平坦度測量,諧振峰值距,LPC殘餘以及模闆比對等。根據貝葉斯準則,語音/噪聲機率可表示為:
其中 是以信号的特征資料為基礎的先驗機率,該值在後續中被設為一個常數。 是特征資料 下的語音/噪聲機率,在忽略 為基礎的先驗機率p{F},簡化語音機率和噪聲機率為:
語音機率: ,噪聲機率 ,這樣标準化的語音機率可以寫為:
LRT均值的計算
前面計算了三個特征中的兩個(頻譜差異度和頻譜平坦度),這裡介紹第三個,也就是LRT均值,這也是這個函數代碼最開始的部分。實際上在理論裡面已經把LRT均值的計算理論公式給出,但是有時候幀與幀之間的頻變似然比因子 會有很大波動,是以采用經過時間平滑處理的似然比因子:
LRT均值同時也作為q公式的參數之一,用來計算q。
q的計算
q的數值依賴于LRT均值、頻譜差異度、頻譜平坦度。
在語音/噪聲機率計算時,使用高斯假設作為語音PDF模型,進而獲得似然比。在其它模型中,機率密度PDF模型也可以用作測量似然比的基礎,包括拉普拉斯算子,伽馬,超高斯。舉個例子,當高斯假設可合理表示噪聲時,該假設并不一定适用于語音,尤其是在較短的時幀中(如~10ms)。在這種情況下,可以使用另一種語音PDF模型,但這很可能會增加複雜性。
要在噪聲估計和過濾流程中确定語音/噪聲的機率,這不僅需要本地SNR(即先驗SNR和瞬态SNR)的引導,還要結合從特征模組化中獲得的語音模型/認知内容。将語音模型/認知内容并入到語音/噪聲機率确定中,能讓噪聲抑制流程更好地處理和區分極不穩定的噪聲水準。如果僅依靠本地SNR,可能會造成可能性偏差。這裡對包含本地SNR和語音特征/模型
gainPrior = ((float)1.0 - inst->priorSpeechProb) / (inst->priorSpeechProb + (float)0.0001);
for (i = 0; i < inst->magnLen; i++) {
invLrt = (float)exp(-inst->logLrtTimeAvg[i]);
invLrt = (float)gainPrior * invLrt;
probSpeechFinal[i] = (float)1.0 / ((float)1.0 + invLrt);
} 更新噪聲估計(UpdateNoiseEstimate)
功能:更新噪聲估計
輸入:magn、snrLocPrior、snrLocPost
輸出:noise:更新的噪聲頻譜估計
的平滑度。這個式子是使用了輸入頻譜和上次噪聲估計的值對噪聲進行估計,它的估計方法是這樣的:當處于噪聲可能性比較大的幀和頻率槽的時候,進行更新;如果是語音可能性比較大的時候,就用上一個幀的估計作為噪聲估計。
噪聲估計更新流程受到語音/噪聲機率和平滑參數γ控制。對于語音機率超過門檻值參數的地方,平滑參數可能會被增加到0.99,以防止語音開始處的噪聲水準增加過高。
處理核心程式(WebRtcNs_ ProcessCore)
- 确定高低頻。
- 加窗,計算帶噪語音資料幀能量,同樣若能量為0,那麼進行特殊處理。
- 進行FFT變換。
-
基于引導更新計算維納濾波器的系數。ComputeDdBasedWienerFilter(self, magn,
theFilter);計算公式見公式(1.5)。
- 對維納增益值根據使用者設定的降噪等級進行下溢和上溢處理
- 進行維納濾波,然後将頻域資料(頻率降噪)通過IFFT轉為時域資料
- 對降噪等級進行判斷,如果等級為0,則維納濾波輸出則為最後的降噪結果。否則,到第8步。
-
再來計算維納濾波後每一幀的資料能量,然後與前面的能量做比值得到gain=sqrtf(energy2 /
(energy1 + 1.f));
- 計算factor1和factor2。
-
結合Analyze中的priorSpeechProb計算最終的增益因子:factor = self->priorSpeechProb *
factor1+(1.f - self->priorSpeechProb) * factor2;
- 資料相乘,得到降噪結果:self->syntBuf[i] += factor * winData[i];