問題來源
這個問題,是看到有人提到帶中文數字的章節标題,要排序的問題引起的。比如對于:
title_list = [
'第一章',
'第三章',
'第五章',
'第四章',
'第二章',
] 想“正确”排序的話,你直接
title_list.sort()
是不行地:
zys@tower:~$ python3
Python 3.7.1 (default, Apr 1 2019, 01:01:48)
[GCC 7.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> title_list = [
... '第一章',
... '第三章',
... '第五章',
... '第四章',
... '第二章',
... ]
>>> title_list.sort()
>>> title_list
['第一章', '第三章', '第二章', '第五章', '第四章']
>>> 原因是在具體編碼的碼表中,“三”并不一定排在“二”前面,碼表的編撰可不會特别考慮中文的排序這種事。
當然,對于不同的編碼,這幾個數字字元的相對位置,可能會有差異。上面的例子,隻代表 Unicode 的一個結果。你轉成 GB18030 或者 BIG5 的位元組,結果可能不同。但這也足夠說明,中文的數字依賴字典序是不可靠的。編碼不同,結果就不同,這裡的“字典序”本身就沒有标準可言,如果你假設 Unicode ,那事實上這些字元的順序也不是我們希望的“1 2 3 4”這樣的順序。
是以,這裡就引出,我們可以把中文數字,轉成阿拉伯數字,然後使用整數大小來排序就可以準确控制了。
光是 “一”,“二”,“三” 這些單個數字,倒是好辦,我們寫死一位數的映射都可以解決問題。接下來要說的,自然是更一般性的處理方法。
比如:
一千零一億一千零一萬一千零一 要處理的問題
看上面的中文數字,直覺地,可以看出中文數字其實是由“數字”和“機關”構成的:
- 數字就是“一”,“二”,“三”這些。
- 機關則是“千”,“萬”,“億”。
這裡我們先明确一下“十”這個“攪屎棍”的位置,它到底算數字,還是算機關。從我們日常習慣用法中看,它是兩者都有的:
- 用于機關,“一十”,“一十五萬”。
- 用于數字,“一千零十萬”。(注意區分,“一千”個“十萬”,和“一千零十”個“萬”的不同)
我們會把“十”作為機關處理,把它當數字時的情況作為特例。這樣面對的特例,要比作為數字少得多。
如果我們能正确解析出漢字數字中的“數字”與“機關”的話,那麼通過映射與簡單運算,就可以得到需要的阿拉伯數字結果。
比如對于:
一千零一億一千零一萬一千零一 如果我們可以解析到:
- 1001
- 億
- 萬
那最後的結果就很容易了,是
1001 * 10^8 + 1001 * 10^4 + 1001
。
實際的問題當然沒這麼簡單,上面的結果沒問題,但首先你要能得到
1001
啊:
- 1
- 千
- 零
-
-
這才是我們從文字中看到的狀況。
上面的結構,像是一顆樹,按這個方向,為了友善定義節點和分支,我們可以整理得到:
繼續分解:
對于這個結構,針對每一個節點,我們從下往上的順序計算,就可以計算出每個節點的值——平行節點的值相加,父子節點的值相乘,過而得到最終值。再推廣一下,整顆樹從下往上順序周遊就可以算出結果。
上面的分拆過程,有助于我們看到這個問題更深的一些資訊,這些資訊就是我們設計代碼的參考。
我們的分拆,在思維上最開始可能是依據結果的倒推(我們知道“一千零一億一千零一萬一千零一”就是
1001 * 10^8 + 1001 * 10^4 + 1001
),但我們寫代碼需要的是正向的邏輯,是以回到最初,去找出我們直覺上的邏輯依據:
對于:
一千零一億一千零一萬一千零一
我們怎麼發現中間這些字應該提出來作為子節點?
這個問題不難。
前面介紹了“數字”和“機關”的概念,我們把原始漢字中這兩者分開:
隻看标色的“機關”,機關的值我們可以以
10
的指數來表示,從左右到繪制到直角坐标系上就是:
$data<<EOF
1 3
2 8
3 3
4 4
5 3
EOF
$data2<<EOF
2 8
4 4
EOF
set xrange [0:6]
set yrange [0:10]
set ytics ("10" 1, "100" 2, "1000" 3, "10000" 4, "10^5" 5, "10^6" 6, "10^7" 7, "10^8" 8)
set pointsize 2
plot $data using 1:2 notitle with line, $data using 1:2 notitle with point ls 6, $data2 using 1:2 notitle with point ls 7 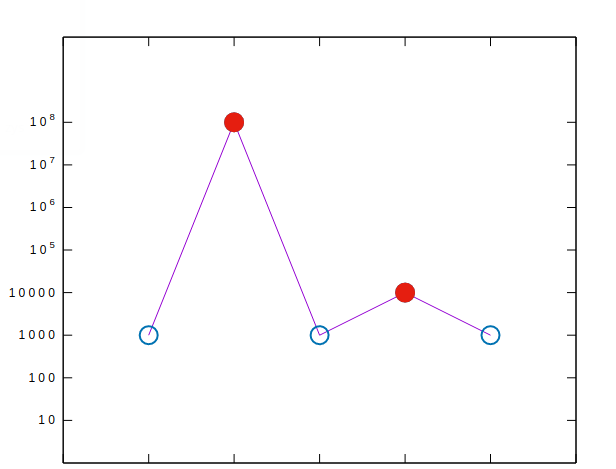
從圖上可以看出,我們要提出來的節點,正好是“波峰”。
再找個例子看看:
一千一百 萬 零 十一億一千一百一十一萬一千一百一十一
$data<<EOF
1 3
2 2
3 4
4 1
5 8
6 3
7 2
8 1
9 4
10 3
11 2
12 1
EOF
$data2<<EOF
3 4
5 8
9 4
EOF
set xrange [0:13]
set yrange [0:10]
set ytics ("10" 1, "100" 2, "1000" 3, "10000" 4, "10^5" 5, "10^6" 6, "10^7" 7, "10^8" 8)
set pointsize 2
plot $data using 1:2 notitle with line, $data using 1:2 notitle with point ls 6, $data2 using 1:2 notitle with point ls 7 
中文的習慣,報數是從大機關到小機關報,是以機關的連線應該是一直向下的。而突然向上,出現波峰,那麼肯定是某個大機關的階段性結束,前面說的那些都是為了“修辭”這個大機關的。
比如上圖的,一千一百,機關是變小的,但馬上接了一個萬,至此,“萬”這個範圍,就結束了。
接着萬,後面是 十,這是一個縮小的機關,沒有特殊,再來就是億,它是一個比“萬”大的機關,同理,意味着“億”這個範圍結束了。
後面還有一個極點,在 萬 上,也是同樣的道理。
再往上看一層,整個過程,波峰處的機關順序是 萬 - 億 - 萬 。
這是否意味着子節點是這三個呢?
-
- x
-
-
答案是否定的,“萬億”,是“萬” x “億”,不是“萬” + “億”。
是以正确的結構應該是:
從 萬 - 億 - 萬 要得到這樣的結構,又有什麼規則?
回溯。
如果從左往右掃,即當碰到一個更大的機關時,需要回溯之前的節點,之前所有不比它大的機關,都應該成為其子節點。
到此,一般性的規則就介紹完了。(其實就這麼點)
運用這個規則,就可以把中文數字,轉成一個樹結構,進而運算出阿拉伯數字結果。
回溯的優化
這點算是經驗之談吧。
當一個場景,如果你從左到右周遊,需要回溯處理。那麼換個方向,從右到左周遊,可能就不需要回溯了。如果周遊對象長度很大,這通常會帶來可觀的性能提升,及代碼編寫上的簡單。
看之前示例的圖和樹結果:
$data<<EOF
1 3
2 2
3 4
4 1
5 8
6 3
7 2
8 1
9 4
10 3
11 2
12 1
EOF
$data2<<EOF
3 4
5 8
9 4
EOF
set xrange [0:13]
set yrange [0:10]
set ytics ("10" 1, "100" 2, "1000" 3, "10000" 4, "10^5" 5, "10^6" 6, "10^7" 7, "10^8" 8)
set pointsize 2
plot $data using 1:2 notitle with line, $data using 1:2 notitle with point ls 6, $data2 using 1:2 notitle with point ls 7 從左到右周遊之是以要回溯,是因為相對于這個樹結構,從左到右周遊的過程是後找到父節點的。當你确定了一個父節點之後,它的子節點你需要重新組織調整。
如果我們把方向反過來,從右到左周遊的話,對于這個樹,總是先遇到父節點。需要做的判斷,僅僅是目前節點是否結束,然後開始一個新的父節點,并不需要不斷折返來調整節點結構。
新節點開始的規則也簡單明了,就是碰到了一個比之前都大的機關。
這些規則弄明白之後,編碼就相對容易了。剩下的更多時間,是處理各種不合邏輯的例外情況,畢竟,人說話是依賴“習慣”,而不是“邏輯”。
編碼
基本配置準備
就是數字和機關的映射,一些資訊可以從網上搜尋到:
num_map = {
u'零': 0,
u'〇': 0,
u'兩': 2,
u'一': 1, u'二': 2, u'三': 3, u'四': 4, u'五': 5, u'六': 6, u'七': 7, u'八': 8, u'九': 9,
u'壹': 1, u'貳': 2, u'叁': 3, u'肆': 4, u'伍': 5, u'陸': 6, u'柒': 7, u'捌': 8, u'玖': 9,
u'廿': 20,
u'卅': 30,
u'卌': 40,
u'圩': 50,
u'圓': 60,
u'進': 70,
u'枯': 80,
u'枠': 90,
}
rank_map = {
u'十': 10, u'百': 100, u'千': 1000, u'萬': 10000, u'億': 100000000,
u'拾': 10, u'佰': 100, u'仟': 1000,
u'兆': 10 ** 16
} 後面如果找到新的詞,也可以直接添加進去。
解析中文
這一步做的事,是把原始中文字元轉換成我們好處理的,中間狀态的資料結構:
先用比較直接簡單的例子來随時測試我們代碼的基本功能,如: 四千五百萬八千零一 。
簡單地使用一個 dict ,有 type 和 value 兩個值就好。
設計上,一點技巧,一是把
單獨處理,因為其實我們知道 零 有些特殊,但還沒有事例來說明它到底特殊在哪裡,是以,給它一點特殊待遇,專門設計一個
zero
的類型。
另一個,是在最後添加一個
complete
類型。這個明确的收尾資訊,可以友善我們處理一些兜底工作,有助于更好的代碼結構。(這個場景,類似于在一個疊代過程中,有一個臨時容器。當疊代結束後,因為在疊代裡面的代碼并不知道疊代何時結束,是以一般你需要在疊代外再額外處理一下這個臨時容器。如果在疊代過程中有一個明确的結束信号,比如明确知道這是最後一個條目了,那麼在疊代内部就可以完成所有工作,代碼會好看點。)
s = '四千五百萬八千零一'
def parse(s):
gen = []
for c in s:
if c in num_map:
if num_map[c] == 0:
gen.append({'type': 'zero'})
else:
gen.append({'type': 'number', 'value': num_map[c]})
if c in rank_map:
gen.append({'type': 'rank', 'value': rank_map[c]})
gen.append({'type': 'complete'})
return gen 執行
parse
可以得到這樣的結果:
[
{'type': 'number', 'value': 4},
{'type': 'rank', 'value': 1000},
{'type': 'number', 'value': 5},
{'type': 'rank', 'value': 100},
{'type': 'rank', 'value': 10000},
{'type': 'number', 'value': 8},
{'type': 'rank', 'value': 1000},
{'type': 'zero'},
{'type': 'number', 'value': 1},
{'type': 'complete'}
] 對于理想狀态,這個結果足夠我們進行接下來的工作了。
生成阿拉伯數字
這一步的一個正常過程,就是前面我們講“規則”的過程。先做一個從左到右的正向周遊,不加回溯,處理一些最簡單場景。接着加入更多場景,發現不加回溯搞不定。最後想到,換個方面周遊更直接友善。
項目上的代碼并不是一蹴而就的,中間會經曆很多次的重構。
這裡就直接給出反向周遊的一個簡單結果:
def generate(token_list):
gen = token_list[:-1]
gen.reverse()
gen.append(token_list[-1])
block = []
level_rank = 1
current_rank = 1
for o in gen:
if o['type'] == 'number':
if not block:
block.append([])
block[-1].append(o['value'] * current_rank)
if o['type'] == 'rank':
rank = o['value']
if not block:
level_rank = rank
current_rank = rank
block.append([])
continue
if rank > level_rank:
level_rank = rank
current_rank = rank
block[-1] = sum(block[-1])
block.append([])
else:
current_rank = rank * level_rank
block[-1] = sum(block[-1])
block.append([])
if o['type'] == 'zero':
continue
if (o['type'] == 'complete'):
if isinstance(block[-1], list):
block[-1] = sum(block[-1])
return sum(block) -
token_list
reverse
- 周遊過程中,小心處理
number
rank
最終,這個
generate
就可以得到我們期望的結果, 45008001 。
不錯的開始。
前面一直在提“理想狀況”,是我們的代碼隻是針對 45008001 這一個普通例子完成。接下來,像這種業務場景,我們就可以做很多的測試用例,然後來“測試驅動完善”了。
更多測試用例
下面的測試用例,絕大部分,是從:
https://github.com/HaveTwoBrush/cn2an/blob/master/cn2an/cn2an_test.py這裡擷取的。
TEST_SUIT = {
u"一": 1,
u"兩": 2,
u"十": 10,
u"十一": 11,
u"一十一": 11,
u"一百一十一": 111,
u"一千一百一十一": 1111,
u"一萬一千一百一十一": 11111,
u"一十一萬一千一百一十一": 111111,
u"一百一十一萬一千一百一十一": 1111111,
u"一千一百一十一萬一千一百一十一": 11111111,
u"一億一千一百一十一萬一千一百一十一": 111111111,
u"一十一億一千一百一十一萬一千一百一十一": 1111111111,
u"一百一十一億一千一百一十一萬一千一百一十一": 11111111111,
u"一千一百一十一億一千一百一十一萬一千一百一十一": 111111111111,
u"壹": 1,
u"拾": 10,
u"拾壹": 11,
u"壹拾壹": 11,
u"壹佰壹拾壹": 111,
u"壹仟壹佰壹拾壹": 1111,
u"壹萬壹仟壹佰壹拾壹": 11111,
u"壹拾壹萬壹仟壹佰壹拾壹": 111111,
u"壹佰壹拾壹萬壹仟壹佰壹拾壹": 1111111,
u"壹仟壹佰壹拾壹萬壹仟壹佰壹拾壹": 11111111,
u"壹億壹仟壹佰壹拾壹萬壹仟壹佰壹拾壹": 111111111,
u"壹拾壹億壹仟壹佰壹拾壹萬壹仟壹佰壹拾壹": 1111111111,
u"壹佰壹拾壹億壹仟壹佰壹拾壹萬壹仟壹佰壹拾壹": 11111111111,
u"壹仟壹佰壹拾壹億壹仟壹佰壹拾壹萬壹仟壹佰壹拾壹": 111111111111,
u"一百零一": 101,
u"一千零一": 1001,
u"一千零一十一": 1011,
u"一千一百零一": 1101,
u"一萬零一": 10001,
u"一萬零一十一": 10011,
u"一萬零一百一十一": 10111,
u"一十萬零一": 100001,
u"一百萬零一": 1000001,
u"一千萬零一": 10000001,
u"一千零一萬一千零一": 10011001,
u"一千零一萬零一": 10010001,
u"一億零一": 100000001,
u"一十億零一": 1000000001,
u"一百億零一": 10000000001,
u"一千零一億一千零一萬一千零一": 100110011001,
u"一千億一千萬一千零一": 100010001001,
u"一千億零一": 100000000001,
u"十萬": 100000,
u"十萬零一": 100001,
u"十億零一萬零一": 1000010001,
u"拾萬零壹": 100001,
u"拾億零壹萬零壹": 1000010001,
u'一千一': 1100,
u'一千一零一': 1101,
u'一千零十億': 101000000000,
u'一一': 11,
u'一二三': 123,
} 拿着這些測試用例去驗證
parse
和
generate
肯定會發現很多異常的,錯誤的情況。再針對這些錯誤的用例,去補充,修改代碼就好。語言不是數學,追求系統層面的完備我覺得沒必要,特殊情況一個
if
就行,實在不行,就再加一個
if
完整實作
下面是一個我多次修改後的一個相對完整的實作,已經通過上面列出的所有測試。
# -*- coding: utf-8 -*-
num_map = {
u'零': 0,
u'〇': 0,
u'兩': 2,
u'一': 1, u'二': 2, u'三': 3, u'四': 4, u'五': 5, u'六': 6, u'七': 7, u'八': 8, u'九': 9,
u'壹': 1, u'貳': 2, u'叁': 3, u'肆': 4, u'伍': 5, u'陸': 6, u'柒': 7, u'捌': 8, u'玖': 9,
u'廿': 20,
u'卅': 30,
u'卌': 40,
u'圩': 50,
u'圓': 60,
u'進': 70,
u'枯': 80,
u'枠': 90,
}
rank_map = {
u'十': 10, u'百': 100, u'千': 1000, u'萬': 10000, u'億': 100000000,
u'拾': 10, u'佰': 100, u'仟': 1000,
u'兆': 10 ** 16
}
s = u'一兆零一'
def convert(s):
gen = []
last_rank = 1
#十 起頭,其它 rank 起頭, 都要補一,否則後面邏輯無法統一解釋
if s[0] in rank_map:
gen.append({'type': 'number', 'value': 1})
for c in s:
if c in num_map:
if num_map[c] == 0:
#前面是數字,要補 rank , 1101
if gen[-1]['type'] == 'number':
gen.append({'type': 'rank', 'value': int(last_rank / 10)})
gen.append({'type': 'zero'})
else:
#連着兩個數字, 如 一一
if gen and (gen[-1]['type'] == 'number'):
gen.append({'type': 'rank', 'value': 10})
gen.append({'type': 'number', 'value': num_map[c]})
if c in rank_map:
# 連續兩個 rank ,合并
# 十 有歧義,如果它前面帶零不能合,如 一千零十億, 還要把它改成數字
# 不帶零要合, 如 一十萬零一
last_rank = rank_map[c]
if gen and gen[-1]['type'] == 'rank':
if (len(gen) > 1) and (gen[-1]['value'] == 10) and (gen[-2]['type'] == 'zero'):
gen[-1]['type'] = 'number'
gen.append({'type': 'rank', 'value': rank_map[c]})
else:
gen[-1]['value'] *= rank_map[c]
continue
gen.append({'type': 'rank', 'value': rank_map[c]})
#補末位的省略, 如 一千一
if gen and len(gen) > 1:
if (gen[-1]['type'] == 'number') and (gen[-2]['type'] == 'rank'):
gen.append({'type': 'rank', 'value': int(gen[-2]['value'] / 10)})
gen.reverse()
gen.append({'type': 'complete'})
block = []
level_rank = 1
current_rank = 1
for o in gen:
if o['type'] == 'number':
if not block:
block.append([])
block[-1].append(o['value'] * current_rank)
if o['type'] == 'rank':
rank = o['value']
if not block:
level_rank = rank
current_rank = rank
block.append([])
continue
if rank > level_rank:
level_rank = rank
current_rank = rank
block[-1] = sum(block[-1])
block.append([])
else:
current_rank = rank * level_rank
block[-1] = sum(block[-1])
block.append([])
if o['type'] == 'zero':
continue
if (o['type'] == 'complete'):
if isinstance(block[-1], list):
block[-1] = sum(block[-1])
return sum(block)
if __name__ == '__main__':
print(s, convert(s))
# from: https://github.com/HaveTwoBrush/cn2an/blob/master/cn2an/cn2an_test.py
TEST_SUIT = {
u"一": 1,
u"兩": 2,
...
u'一千一': 1100,
u'一千一零一': 1101,
u'一千零十億': 101000000000,
u'一一': 11,
u'一二三': 123,
}
count = 0
error = 0
for c, v in TEST_SUIT.items():
r = convert(c)
count += 1
if v != r:
error += 1
print('ERROR', c, v, r)
print('SUM: {} ERROR: {}'.format(count, error))