本文作者: 林武康(花名:知瑕),阿裡巴巴計算平台事業部技術專家,Apache HUE Contributor, 參與了多個開源項目的研發工作,對于分布式系統設計應用有較豐富的經驗,目前主要專注于EMR資料開發相關的産品的研發工作。
本文介紹Spark Operator的設計和實作相關的内容.
Spark運作時架構
經過近幾年的高速發展,分布式計算架構的架構逐漸趨同. 資源管理子產品作為其中最通用的子產品逐漸與架構解耦,獨立成通用的元件.目前大部分分布式計算架構都支援接入多款不同的資料總管. 資料總管負責叢集資源的管理和排程,為計算任務配置設定資源容器并保證資源隔離.Apache Spark作為通用分布式計算平台,目前同時支援多款資料總管,包括:
- YARN
- Mesos
- Kubernetes(K8s)
- Spark Standalone(自帶的資料總管)
Apache Spark的運作時架構如下圖所示, 其與各類資源排程器的互動流程比較類似.
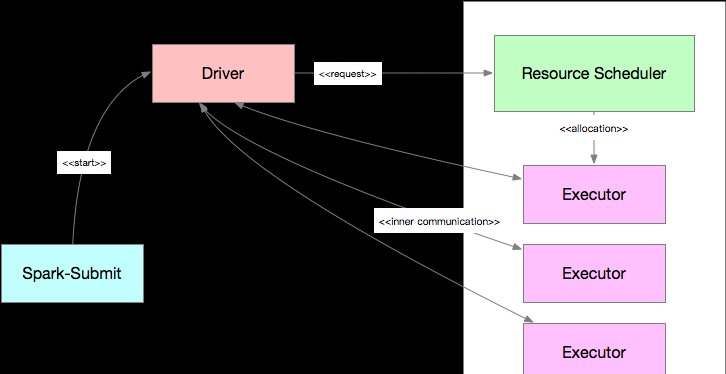
圖1 Spark運作時架構(Client模式)
其中,Driver負責作業邏輯的排程和任務的監控, 資料總管負責資源配置設定和監控.Driver根據部署模式的不同,啟動和運作的實體位置有所不同. 其中,Client模式下,Driver子產品運作在Spark-Submit程序中, Cluster模式下,Driver的啟動過程和Executor類似,運作在資源排程器配置設定的資源容器内.
K8s是Spark在2.3開始支援資料總管,而相關讨論早在2016年就已經開始展開(
https://issues.apache.org/jira/browse/SPARK-18278). Spark對K8s的支援随着版本的疊代也逐漸深入, 在即将釋出的3.0中,Spark on K8s提供了更好的Kerberos支援和資源動态支援的特性.
Spark on K8s
Kubernetes是由Google開源的一款面向應用的容器叢集部署和管理系統,近年來發展十分迅猛,相關生态已經日趨完善. 在Spark官方接入K8s前,社群通常通過在K8s叢集上部署一個Spark Standalone叢集的方式來實作在K8s叢集上運作Spark任務的目的.方案架構如下圖所示:

圖2 Spark Standalone on K8s
這個模式簡單易用,但存在相當大的缺陷:
- 無法按需擴充, Spark Standalone部署後叢集規模固定,無法根據作業需求自動擴充叢集;
- 無法利用K8s原生能力, Spark Standalone内建的資源排程器不支援擴充,難以接入K8s排程,無法利用K8s提供的雲原生特性;
- Spark Standalone叢集在多租戶資源隔離上天生存在短闆;
為此,Spark社群進行了深入而廣泛的讨論,在2.3版本提供了對K8s的官方支援.Spark接入K8s的好處是十分明顯的:
- 直接和K8s對接,可以更加高效和快捷的擷取叢集資源;
- 利用K8s原生能力(如namespace等)可以更好的實作資源隔離和管控.
Spark on K8s方案架構如下圖所示, 設計細節可以參考:
SPARK-18278 圖3 Spark on K8s (Native)
在這個方案中,
- Spark-Submit通過調用K8s API在K8s叢集中啟動一個Spark Driver Pod;
- Driver通過調用K8s API啟動相應的Executor Pod, 組成一個Spark Application叢集,并指派作業任務到這些Executor中執行;
- 作業結束後,Executor Pod會被銷毀, 而Driver Pod會持久化相關日志,并保持在'completed'狀态,直到使用者手清理或被K8s叢集的垃圾回收機制回收.
目前的方案已經解決了Spark Standalone on K8s方案的部分缺陷,然而,Spark Application的生命周期管理方式和排程方式與K8s内置的工作負載(如Deployments、DaemonSets、StatefulSets等)存在較大差異,在K8s上執行作業仍然存在不少問題:
- Spark-submit在K8s叢集之外,使用非聲明式的送出接口;
- Spark Application之間沒有協同排程,在小叢集中很容易出現排程餓死的情況;
- 需要手動配置網絡,來通路WebUI;
- 任務監控比較麻煩,沒有接入Prometheus叢集監控;
當然Spark on K8s方案目前還在快速開發中,更多特性不久會釋出出來,相信未來和K8s的內建會更加緊密和Native, 這些特性包括:
- 動态資源配置設定和外部Shullfe服務
- 本地檔案依賴管理器
- Spark Application管理器
- 作業隊列和資料總管
Spark Operator淺析
在分析Spark Operator的實作之前, 先簡單梳理下Kubernetes Operator的基本概念. Kubernetes Operator是由CoreOS開發的Kubernetes擴充特性, 目标是通過定義一系列CRD(自定義資源)和實作控制器,将特定領域的應用程式運維技術和知識(如部署方法、監控、故障恢複等)通過代碼的方式固化下來. Spark Operator是Google基于Operator模式開發的一款的工具(
https://github.com/GoogleCloudPlatform/spark-on-k8s-operator), 用于通過聲明式的方式向K8s叢集送出Spark作業.使用Spark Operator管理Spark應用,能更好的利用K8s原生能力控制和管理Spark應用的生命周期,包括應用狀态監控、日志擷取、應用運作控制等,彌補Spark on K8s方案在內建K8s上與其他類型的負載之間存在的差距.
下面簡單分析下Spark Operator的實作細節.
系統架構
圖4 Spark Operator架構
可以看出,Spark Operator相比Spark on K8s,架構上要複雜一些,實際上Spark Operator內建了Spark on K8s的方案,提供了更全面管控特性.通過Spark Operator,使用者可以使用更加符合K8s理念的方式來控制Spark應用的生命周期.Spark Operator包括如下幾個元件:
- SparkApplication控制器, 該控制器用于建立、更新、删除SparkApplication對象,同時控制器還會監控相應的事件,執行相應的動作;
- Submission Runner, 負責調用spark-submit送出Spark作業, 作業送出的流程完全複用Spark on K8s的模式;
- Spark Pod Monitor, 監控Spark作業相關Pod的狀态,并同步到控制器中;
- Mutating Admission Webhook: 可選子產品,基于注解來實作Driver/Executor Pod的一些定制化需求;
- SparkCtl: 用于和Spark Operator互動的指令行工具
Spark Operator除了實作基本的作業送出外,還支援如下特性:
- 聲明式的作業管理;
- 支援更新SparkApplication對象後自動重新送出作業;
- 支援可配置的重新開機政策;
- 支援失敗重試;
- 內建prometheus, 可以收集和轉發Spark應用級别的度量和Driver/Executor的度量到prometheus中.
工程結構
Spark Operator的項目是标準的K8s Operator結構, 其中最重要的包括:
- manifest: 定義了Spark相關的CRD,包括:
- ScheduledSparkApplication: 表示一個定時執行的Spark作業
- SparkApplication: 表示一個Spark作業
- pkg: 具體的Operator邏輯實作
- api: 定義了Operator的多個版本的API
- client: 用于對接的client-go SDK
- controller: 自定義控制器的實作,包括:
- ScheduledSparkApplication控制器
- SparkApplication控制器
- batchscheduler: 批處理排程器內建子產品, 目前已經內建了K8s volcano排程器
- spark-docker: spark docker 鏡像
- sparkctl: spark operator指令行工具
下面主要介紹下Spark Operator是如何管理Spark作業的.
Spark Application控制器
控制器的代碼主要位于"pkg/controller/sparkapplication/controller.go"中.
送出流程
送出作業的送出作業的主流程在submitSparkApplication方法中.
// controller.go
// submitSparkApplication creates a new submission for the given SparkApplication and submits it using spark-submit.
func (c *Controller) submitSparkApplication(app *v1beta2.SparkApplication) *v1beta2.SparkApplication {
if app.PrometheusMonitoringEnabled() {
...
configPrometheusMonitoring(app, c.kubeClient)
}
// Use batch scheduler to perform scheduling task before submitting (before build command arguments).
if needScheduling, scheduler := c.shouldDoBatchScheduling(app); needScheduling {
newApp, err := scheduler.DoBatchSchedulingOnSubmission(app)
...
//Spark submit will use the updated app to submit tasks(Spec will not be updated into API server)
app = newApp
}
driverPodName := getDriverPodName(app)
submissionID := uuid.New().String()
submissionCmdArgs, err := buildSubmissionCommandArgs(app, driverPodName, submissionID)
...
// Try submitting the application by running spark-submit.
submitted, err := runSparkSubmit(newSubmission(submissionCmdArgs, app))
...
app.Status = v1beta2.SparkApplicationStatus{
SubmissionID: submissionID,
AppState: v1beta2.ApplicationState{
State: v1beta2.SubmittedState,
},
DriverInfo: v1beta2.DriverInfo{
PodName: driverPodName,
},
SubmissionAttempts: app.Status.SubmissionAttempts + 1,
ExecutionAttempts: app.Status.ExecutionAttempts + 1,
LastSubmissionAttemptTime: metav1.Now(),
}
c.recordSparkApplicationEvent(app)
service, err := createSparkUIService(app, c.kubeClient)
...
ingress, err := createSparkUIIngress(app, *service, c.ingressURLFormat, c.kubeClient)
return app
} 送出作業的核心邏輯在submission.go這個子產品中:
// submission.go
func runSparkSubmit(submission *submission) (bool, error) {
sparkHome, present := os.LookupEnv(sparkHomeEnvVar)
if !present {
glog.Error("SPARK_HOME is not specified")
}
var command = filepath.Join(sparkHome, "/bin/spark-submit")
cmd := execCommand(command, submission.args...)
glog.V(2).Infof("spark-submit arguments: %v", cmd.Args)
output, err := cmd.Output()
glog.V(3).Infof("spark-submit output: %s", string(output))
if err != nil {
var errorMsg string
if exitErr, ok := err.(*exec.ExitError); ok {
errorMsg = string(exitErr.Stderr)
}
// The driver pod of the application already exists.
if strings.Contains(errorMsg, podAlreadyExistsErrorCode) {
glog.Warningf("trying to resubmit an already submitted SparkApplication %s/%s", submission.namespace, submission.name)
return false, nil
}
if errorMsg != "" {
return false, fmt.Errorf("failed to run spark-submit for SparkApplication %s/%s: %s", submission.namespace, submission.name, errorMsg)
}
return false, fmt.Errorf("failed to run spark-submit for SparkApplication %s/%s: %v", submission.namespace, submission.name, err)
}
return true, nil
}
func buildSubmissionCommandArgs(app *v1beta2.SparkApplication, driverPodName string, submissionID string) ([]string, error) {
...
options, err := addDriverConfOptions(app, submissionID)
...
options, err = addExecutorConfOptions(app, submissionID)
...
}
func getMasterURL() (string, error) {
kubernetesServiceHost := os.Getenv(kubernetesServiceHostEnvVar)
...
kubernetesServicePort := os.Getenv(kubernetesServicePortEnvVar)
...
return fmt.Sprintf("k8s://https://%s:%s", kubernetesServiceHost, kubernetesServicePort), nil
} 可以看出,
- 可以配置控制器啟用Prometheus進行度量收集;
- Spark Operator通過拼裝一個spark-submit指令并執行,實作送出Spark作業到K8s叢集中的目的;
- 在每次送出前,Spark Operator都會生成一個UUID作為Session Id,并通過Spark相關配置對driver/executor的pod進行标記.我們可以使用這個id來跟蹤和控制這個Spark作業;
- Controller通過監控相關作業的pod的狀态來更新SparkApplication的狀态,同時驅動SparkApplication對象的狀态流轉.
- 送出成功後,還會做如下幾件事情:
- 更新作業的狀态
- 啟動一個Service,并配置好Ingress,友善使用者通路Spark WebUI
另外,如果對Spark on K8s的使用文檔比較困惑,這段代碼是比較好的一個示例.
狀态流轉控制
在Spark Operator中,Controller使用狀态機來維護Spark Application的狀态資訊, 狀态流轉和Action的關系如下圖所示:
圖5 _State Machine for SparkApplication_
作業送出後,Spark Application的狀态更新都是通過getAndUpdateAppState()方法來實作的.
// controller.go
func (c *Controller) getAndUpdateAppState(app *v1beta2.SparkApplication) error {
if err := c.getAndUpdateDriverState(app); err != nil {
return err
}
if err := c.getAndUpdateExecutorState(app); err != nil {
return err
}
return nil
}
// getAndUpdateDriverState finds the driver pod of the application
// and updates the driver state based on the current phase of the pod.
func (c *Controller) getAndUpdateDriverState(app *v1beta2.SparkApplication) error {
// Either the driver pod doesn't exist yet or its name has not been updated.
...
driverPod, err := c.getDriverPod(app)
...
if driverPod == nil {
app.Status.AppState.ErrorMessage = "Driver Pod not found"
app.Status.AppState.State = v1beta2.FailingState
app.Status.TerminationTime = metav1.Now()
return nil
}
app.Status.SparkApplicationID = getSparkApplicationID(driverPod)
...
newState := driverStateToApplicationState(driverPod.Status)
// Only record a driver event if the application state (derived from the driver pod phase) has changed.
if newState != app.Status.AppState.State {
c.recordDriverEvent(app, driverPod.Status.Phase, driverPod.Name)
}
app.Status.AppState.State = newState
return nil
}
// getAndUpdateExecutorState lists the executor pods of the application
// and updates the executor state based on the current phase of the pods.
func (c *Controller) getAndUpdateExecutorState(app *v1beta2.SparkApplication) error {
pods, err := c.getExecutorPods(app)
...
executorStateMap := make(map[string]v1beta2.ExecutorState)
var executorApplicationID string
for _, pod := range pods {
if util.IsExecutorPod(pod) {
newState := podPhaseToExecutorState(pod.Status.Phase)
oldState, exists := app.Status.ExecutorState[pod.Name]
// Only record an executor event if the executor state is new or it has changed.
if !exists || newState != oldState {
c.recordExecutorEvent(app, newState, pod.Name)
}
executorStateMap[pod.Name] = newState
if executorApplicationID == "" {
executorApplicationID = getSparkApplicationID(pod)
}
}
}
// ApplicationID label can be different on driver/executors. Prefer executor ApplicationID if set.
// Refer https://issues.apache.org/jira/projects/SPARK/issues/SPARK-25922 for details.
...
if app.Status.ExecutorState == nil {
app.Status.ExecutorState = make(map[string]v1beta2.ExecutorState)
}
for name, execStatus := range executorStateMap {
app.Status.ExecutorState[name] = execStatus
}
// Handle missing/deleted executors.
for name, oldStatus := range app.Status.ExecutorState {
_, exists := executorStateMap[name]
if !isExecutorTerminated(oldStatus) && !exists {
// If ApplicationState is SUCCEEDING, in other words, the driver pod has been completed
// successfully. The executor pods terminate and are cleaned up, so we could not found
// the executor pod, under this circumstances, we assume the executor pod are completed.
if app.Status.AppState.State == v1beta2.SucceedingState {
app.Status.ExecutorState[name] = v1beta2.ExecutorCompletedState
} else {
glog.Infof("Executor pod %s not found, assuming it was deleted.", name)
app.Status.ExecutorState[name] = v1beta2.ExecutorFailedState
}
}
}
return nil
} 從這段代碼可以看到, Spark Application送出後,Controller會通過監聽Driver Pod和Executor Pod狀态來計算Spark Application的狀态,推動狀态機的流轉.
度量監控
如果一個SparkApplication示例配置了開啟度量監控特性,那麼Spark Operator會在Spark-Submit送出參數中向Driver和Executor的JVM參數中添加類似"-javaagent:/prometheus/jmx_prometheus_javaagent-0.11.0.jar=8090:/etc/metrics/conf/prometheus.yaml"的JavaAgent參數來開啟SparkApplication度量監控,實作通過JmxExporter向Prometheus發送度量資料.
圖6 Prometheus架構
WebUI
在Spark on K8s方案中, 使用者需要通過
kubectl port-forward
指令建立臨時通道來通路Driver的WebUI,這對于需要頻繁通路多個作業的WebUI的場景來說非常麻煩. 在Spark Operator中,Spark Operator會在作業送出後,啟動一個Spark WebUI Service,并配置Ingress來提供更為自然和高效的通路途徑.
小結
本文總結了Spark計算架構的基礎架構,介紹了Spark on K8s的多種方案,着重介紹了Spark Operator的設計和實作.K8s Operator尊從K8s設計理念,極大的提高了K8s的擴充能力.Spark Operator基于Operator範式實作了更為完備的管控特性,是對官方Spark on K8s方案的有力補充.随着K8s的進一步完善和Spark社群的努力,可以預見Spark on K8s方案會逐漸吸納Spark Operator的相關特性,進一步提升雲原生體驗.
參考資料:
[1]
Kubernetes Operator for Apache Spark Design[2]
What is Prometheus?[3]
Spark on Kubernetes 的現狀與挑戰[4]
Spark in action on Kubernetes - Spark Operator的原了解析[5]
Operator pattern[6]
Custom Resources